SAP-Hana-SQL解析时间过长优化
项目场景:
SAP中自开发的物料主数据查询报表,用于查询物料关联的各个视图数据,包括基本视图/工厂视图/销售视图/仓库视图等,共138个字段。问题描述:
该报表已按照Hana代码下沉的思路,将多次从Hana取数再在应用服务器处理的逻辑,改为1个SQL直接从Hana取数,全量查询时6秒左右(12万条数据138个字段)。 但仍存在部分场景,执行时间超过90秒。原因分析:
调查过程如下:- 确认执行较慢的执行条件,发现均为多条物料号查询,条目在100到9999条间(大于9999条会 dump)
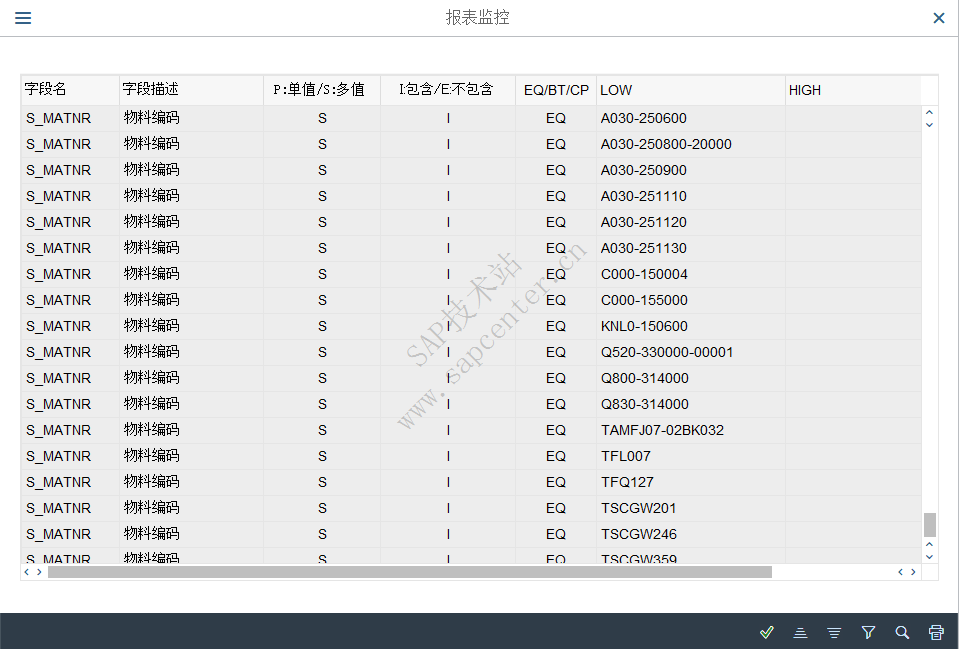
- HANA studio 查询视图M_SQL_PLAN_CACHE ,发现执行时间花费在Preparation上,即语句执行前的解析上(截图其他语句,原记录未保存)
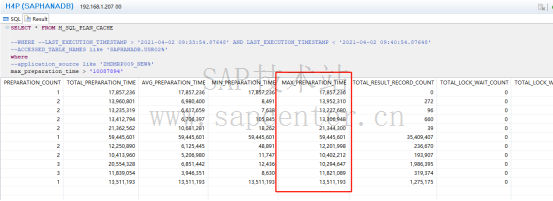
- 分析Hana语句执行过程
如下图,当hana 收到一条sql语句的时候,会到sql plan cache 中确认是否有已解析过的语句,有的话直接取,没有的话会重新解析,时间即耗费在解析环节。
- Hana对多条件range的解析过程
对于ABAP中的RANGE条件,Hana解析的时候会转换为Where条件。由于物料号有几千条,最终的语句是非常长的。其中任意1个物料号的变更,Hana都认为是不同的语句,需要重新解析。而这个判断条件是否有差异的过程比较复杂,时间应该耗费在这里(自认为也是Hana的一个bug,可能后期会优化)。
ST05追踪解析后的语句如下:

解决方案:
1.参考SAP建议,对于长List条件查询,转换为内表join或for all entries 方式
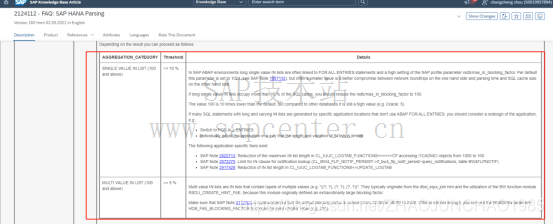
转换后,解析语句如下,红框部分为物料号条件,物料表作为一个单独参数传入,条件变化时不需要重新解析:

效果:此种SQL执行时间也能达到6秒内。
2.减少SQL中的硬写入的文本:
在解决上述问题时,SAP也提到需尽量减少SQL中的文本,以降低解析时间。

从ST05看SQL语句,如下‘10012’为直接写死在sql中的条件为文本,用变量代替的(?)为绑定变量

对应到OPEN SQL中如下,共有约20个写死的文本。
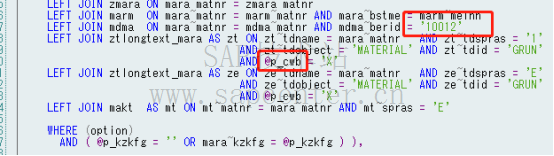
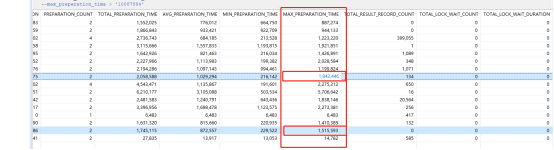
此时,从Hanastudio 查询sql plan cache , 解析时间占1.83秒

替换SQL语句中18个文本变量
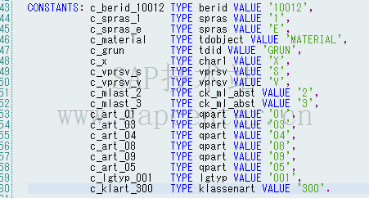
再次执行SQL语句,类似条件下,解析时间平均降低0.3秒
附参考资料:
Bing 搜索SAP HANA PARSE LONG TIME,有如下Note相关
SAP HANA Parsing
How bind variables can reduce parsing or query compilation time on SAP HANA
post SAP-Garson
原文链接:https://blog.csdn.net/ZHAOJUNCHAO1985/article/details/119031055文章来自于网络,如果侵犯了您的权益,请联系站长删除!



