【15W字长文】主从复制高可用Redis集群,完整包含Redis所有知识点
往期文章一览
【7W字长文】使用LVS+Keepalived实现Nginx高可用,一文搞懂Nginx
主从复制高可用Redis集群
分布式架构介绍
什么是分布式架构
随着越来越多的人参与到互联网的浪潮来,曾经的单体应用架构越来越无法满足需求,所以,分布式集群架构出现,也因此,分布式搭建开发成为了Web开发者必掌握的技能之一。那什么是分布式呢?怎么实现分布式以及怎么处理分布式带来的问题呢?本系列文章就来源于对分布式各组件系统的学习总结,包含但不限于Zookeeper、Dubbo、消息队列(ActiveMQ、Kafka、RabbitMQ)、NoSql(Redis、MongoDB)、Nginx、分库分表MyCat、Netty等内容。
简单的说,“分工协作,专人做专事”就是分布式的概念。不同的功能模块分散部署在不同的服务器,每个子系统负责一个或多个不同的业务模块,服务之间可以相互交互和通信。
分布式系统设计对用户是透明的,用户只关心请求是否能返回相应的结果而已,和集群对用户透明的概念类似。同时,分布式架构中每个服务也可以做集群,可以发展为集群分布式系统架构,而且一个服务的集群对于其他服务来说也是透明的。微服务架构是属于分布式架构的一种,微服务架构是分布式架构的一个子集。
- 集群:你们公司业务增长的非常快,老板发现你一个后端忙不过来了,就又招了几个后端开发来协助你,这就是后端集群;再往后,发现前端也忙不过来了,又配备几个前端,就是前端集群。所以也不难看出,将应用拆分后,你可以有针对性地扩展单个服务,做成集群,这就是分布式的好处之一。
- 节点:这个也非常好理解,一个服务就是一个节点,比如你就是后端集群中的一个节点,而集群本身也可以看成是整个应用的一个集群节点。
- 副本:副本就是为服务和数据提供的冗余,保证高可用。
- 中间件:为开发者提供便利,屏蔽复杂的底层的一类框架组件。如服务管理通信、序列化、负载均衡等组件。
单体架构和分布式架构举例描述
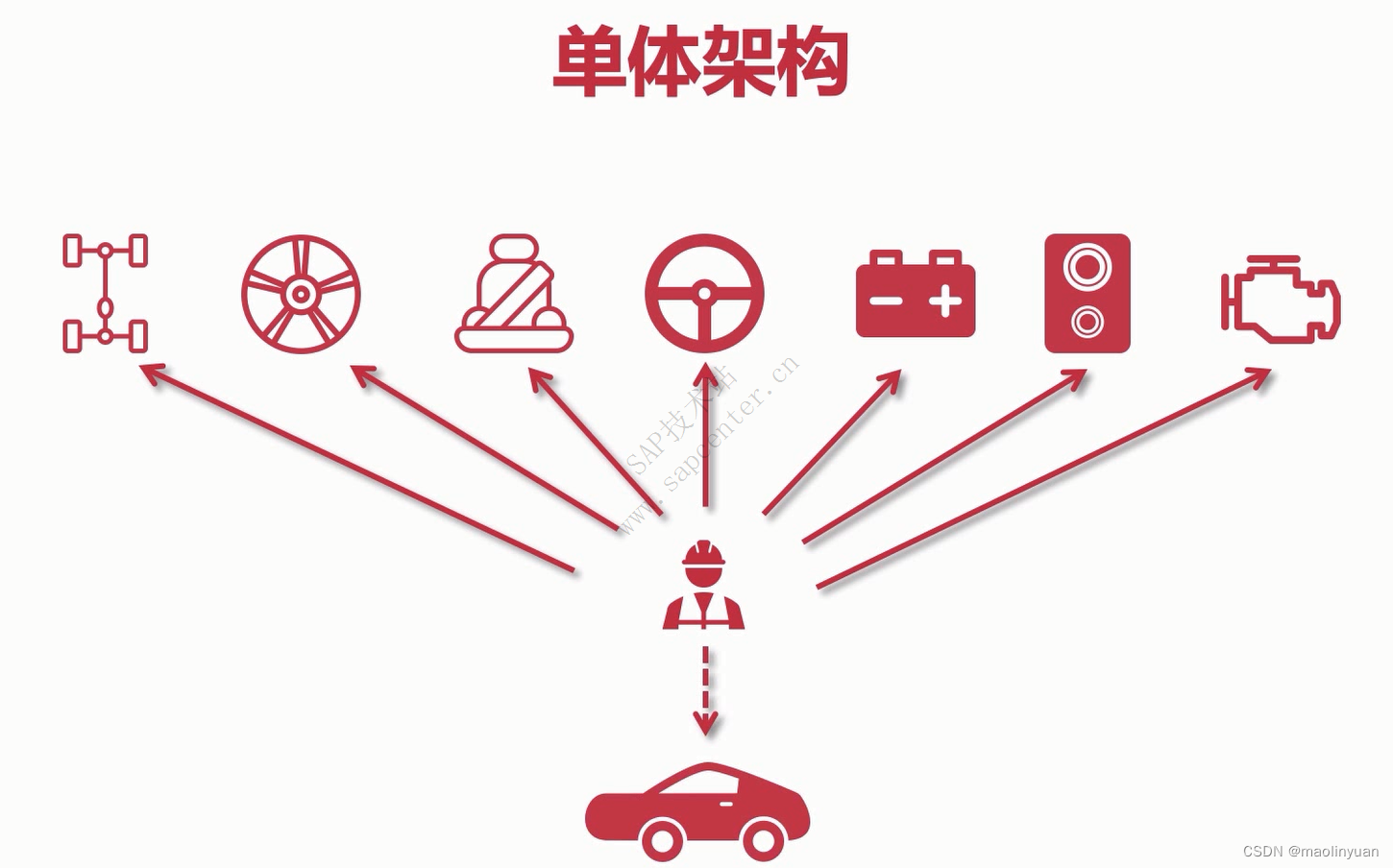
举例来说,一个工人造汽车时,从左到右每个环节都是他来处理,最后得到一台整车。这时,服务的性能顶点就很低,因为一个人的能力是有限的。
当然我们也可以多请几个工人,多线进行,形成一个相当于服务集群的效果,当然这个是把整个服务的所有功能都进行了集群。但是又出现一个问题,比如说装底盘比较简单,几分钟就完成了,而装轮子比较难,几天都完成不了。那么影响汽车建造完成的瓶颈就在轮子上,我把整个流程复制一份,再请一个工人来做,成本提高了,但是效率却并没有提升这么大。因为装底盘本来就简单,我一个人就可以跟上生产的速度,我没必要两个人都要去装底盘。
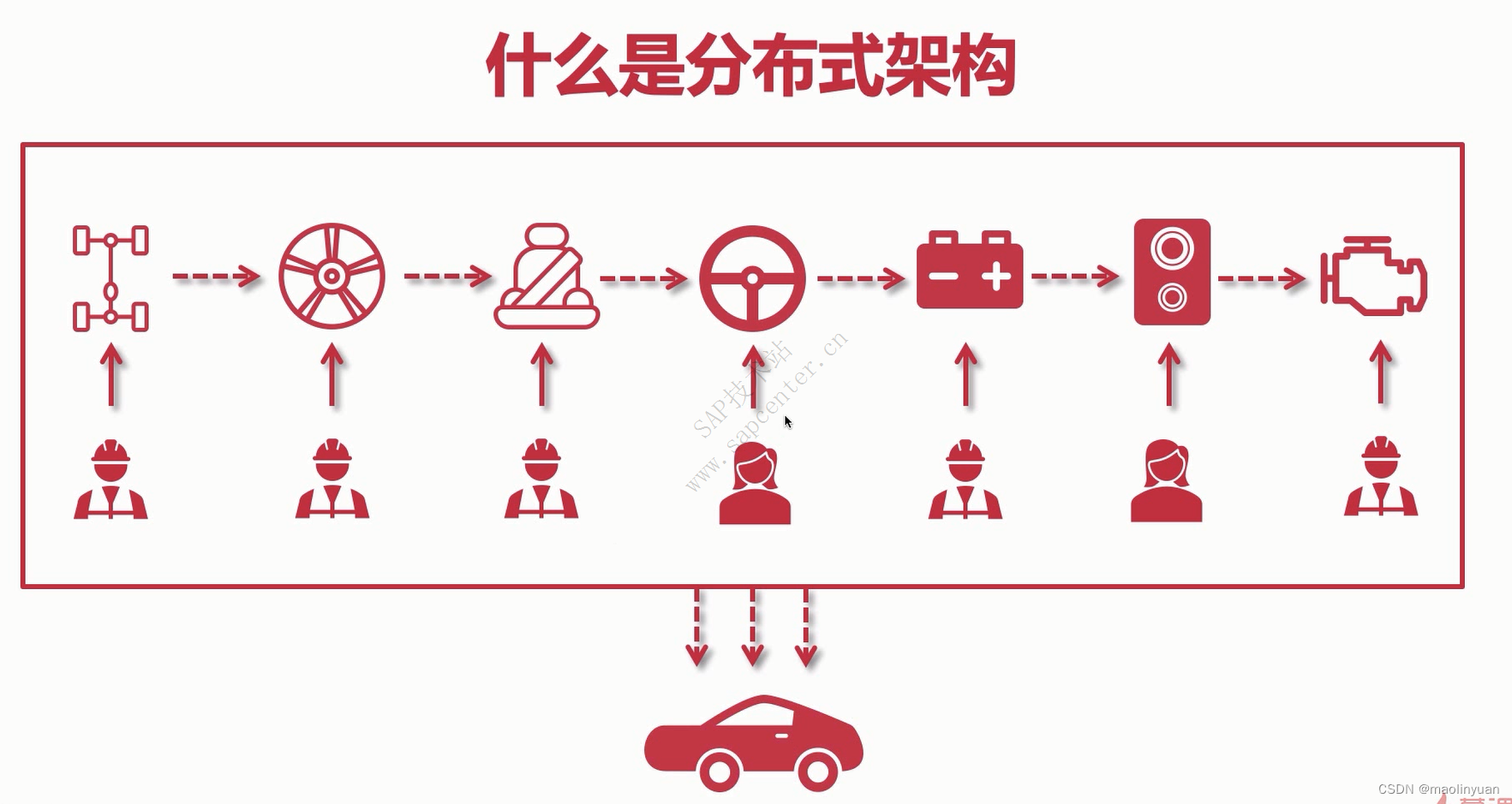
为了解决这个问题,首先我们把人员分来,每个人只做自己擅长的事情,就像是流水线。这样学习时间会缩短,熟练之后效率也提高的快,这就形成了一个基本的分布式架构。
装轮子比较困难,一个人装需要几天时间,我可以多分配几个人一起装,这样可以提高这个步骤的安装时间,而其他步骤比较简单的,就保持一个人就行了。定向优化某一个服务,提高它的性能瓶颈,这样可以尽量缩短每个服务处理的时间差,成本也可以大大减少,这就形成了分布式集群架构。
分布式架构的优点
- 业务解耦:解耦之后方便性能优化。
- 系统模块化,可重用化:发布时也不用全部模块一起发布,只需要发布更新的模块就行了。
- 提升系统并发量:单体架构的并发量是有限的,而分布式架构可以集群某一个可承载并发量比较低的模块从而提升整体架构的并发量上限。
- 优化运维部署效率:迭代发布时,只需要根据模块发布,包比较轻巧,单体架构打包往往比较庞大。
分布式架构的缺点
- 架构比较复杂:功能多了,模块多,服务器也会更多,架构就更加复杂了
- 部署多个子系统复杂:当同时修改多个模块时,部署则需要同时更新多个服务器上面的应用
- 系统之间通信耗时:服务之间调用会有时间的损耗,这是不可避免的。
- 新人融入团队缓慢:架构复杂时,新人上手难度会变高
- 调试复杂:调用链路比较长的话,debug时往往需要同时启多个服务,打印日志也需要在多个服务中查看。
基本设计原则
- 异步解构:模块拆分之后,模块与模块之间的通信会有异步和同步之分。能使用异步尽量使用异步,不到万不得已不要使用同步,因为异步的效率往往要比同步高很多,异步解耦需要涉及到消息队列。
- 幂等一致性:用户的请求可能需要经过多个子系统,不管是查询或者增删改,多次操作或者重复操作数据的一致性是需要保证的。主要针对于增加和修改操作,因为查询多查几次结果都是一致的,删除删掉一次数据就没有了,多删几次也不会删掉别的数据,而增加假如没有处理好会增加很多条重复数据,会使应用出现问题。
- 拆分原则:可以根据业务来拆,比如说可以拆分成订单系统、文件系统、门户系统等;也可以根据系统功能来拆分比如把文件系统可以拆分成上传文件子系统、下载文件子系统等。
- 融合分布式中间件:比如Redis可以作为缓存,Zookeeper可以作为协调,MQ可以作为消息队列等,这些我们都可以把它融入到我们的系统中去。
- 容错高可用:每个服务单独部署都会容易产生单点故障,这是我们可以使用集群的方案来应对单点故障,集群和分布式技术是相辅相成的。
分布式架构需要使用到的技术
- 分布式缓存中间件Redis
- 分布式会话以及单点登录
- 分布式搜索引擎Elasticsearch
- 分布式文件系统
- 分布式消息队列
- 分布式锁
- 数据库读写分离以及分库分表
- 数据库表全局唯一主键id设计
- 分布式事务以及数据一致性
- 接口幂等设计以及分布式限流
分布式缓存和技术选型
什么是Redis
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
Redis的出现,很大程度补偿了Memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。
它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,Redis支持各种不同方式的排序。与Memcached一样,为了保证效率,数据都是缓存在内存中。
区别的是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
Redis的官网地址,非常好记,是redis.io。(域名后缀io属于国家域名,是british Indian Ocean territory,即英属印度洋领地)
特性和特点
Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库,其具备如下特性:
- 基于内存运行,性能高效
- 支持分布式,理论上可以无限扩展
- key-value存储系统
- 开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
相比于其他数据库类型,Redis具备的特点是:
- C/S通讯模型
- 单进程单线程模型
- 丰富的数据类型
- 操作具有原子性
- 持久化
- 高并发读写
- 支持lua脚本
参考链接:
为什么要引入Redis
在Web应用发展的初期,那时关系型数据库受到了较为广泛的关注和应用,原因是因为那时候Web站点基本上访问和并发不高、交互也较少。而在后来,随着访问量的提升,使用关系型数据库的Web站点多多少少都开始在性能上出现了一些瓶颈,而瓶颈的源头一般是在磁盘的I/O上。而随着互联网技术的进一步发展,各种类型的应用层出不穷,这导致在当今云计算、大数据盛行的时代,对性能有了更多的需求,主要体现在以下四个方面:
- 低延迟的读写速度:应用快速地反应能极大地提升用户的满意度
- 支撑海量的数据和流量:对于搜索这样大型应用而言,需要利用PB级别的数据和能应对百万级的流量
- 大规模集群的管理:系统管理员希望分布式应用能更简单的部署和管理
- 庞大运营成本的考量:IT部门希望在硬件成本、软件成本和人力成本能够有大幅度地降低
为了克服这一问题,NoSQL应运而生,它同时具备了高性能、可扩展性强、高可用等优点,受到广泛开发人员和仓库管理人员的青睐。
现有架构分析
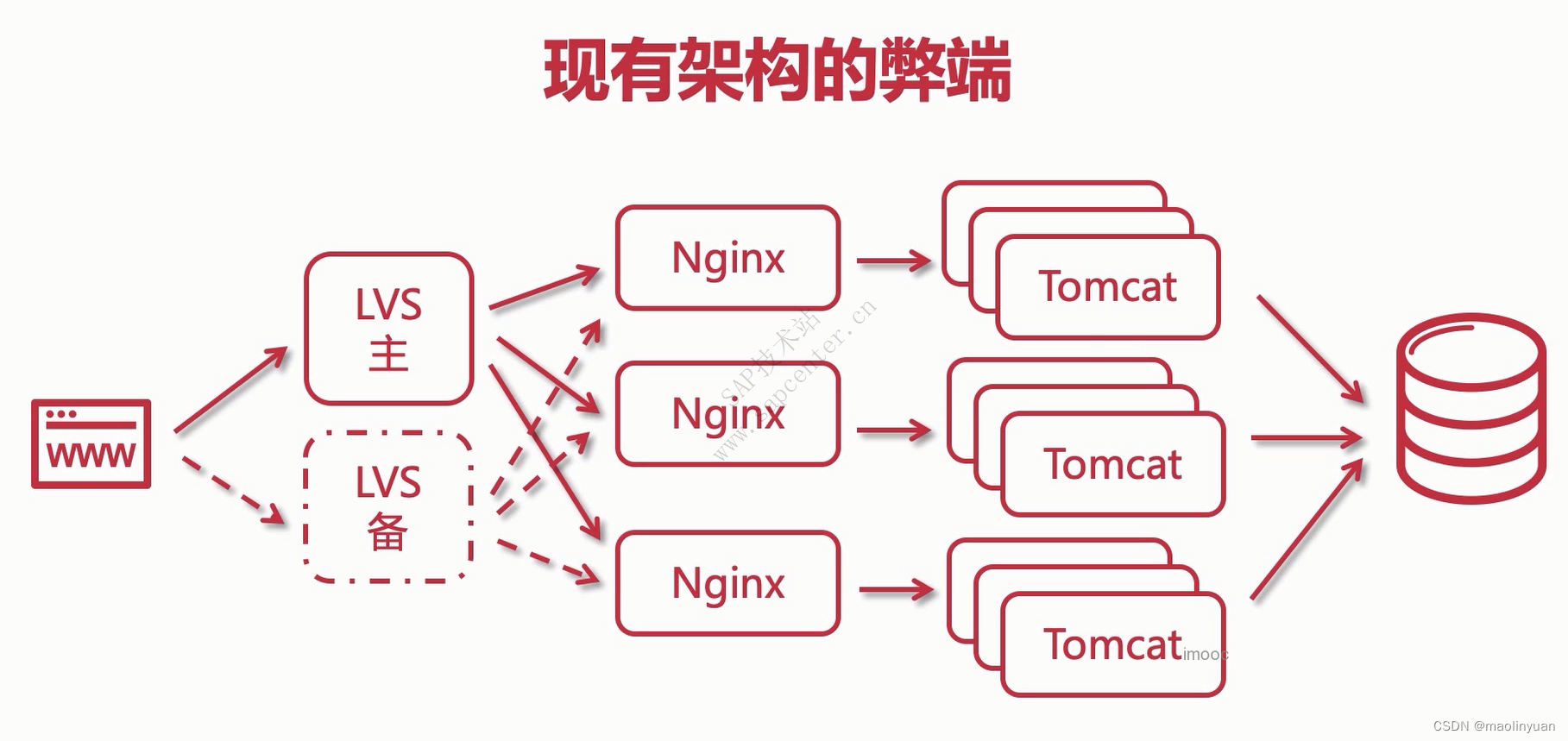
- 浏览器访问时,请求先到LVS,使用Keepalived让两台LVS达成一个主备关系或者双主热备关系
- LVS的之后是Nginx集群,LVS是四层负载均衡,使用DR模式使请求通过LVS,而响应直接由应用响应到浏览器
- 每个Nginx集群的每一个节点都使用了upstream模块,配置了tomcat集群
- 因为每个应用服务是完全相同的,所以他们的都会连接到同一个数据库,现在应用的性能瓶颈就在应用到数据库之间
- 在应用的时,对于数据库来说当中有一个二八原则,请求中百分之八十都是读请求,写请求远远少于读请求
举个例子,假如系统中有2千万用户信息,用户信息基本固定,一旦录入很少变动,那么你每次加载所有用户信息时,如果都要请求数据库,数据库编译并执行你的查询语句,这样效率就会低下很多,针对这种信息不经常变动并且数据量较大的情况,通常做法,就是把他加入缓存,每次取数前先去判断,如果缓存不为空,那么就从缓存取值,如果为空,再去请求数据库,并将数据加入缓存,这样大大提高系统访问效率。
其次,假如有一个明星的负面新闻被曝光在微博上了,这时会有几千万上亿的请求会访问到它。对于这种高流量的热点新闻,我们也可以加入缓存,减缓数据库压力,是数据库不会被上亿的流量冲垮。
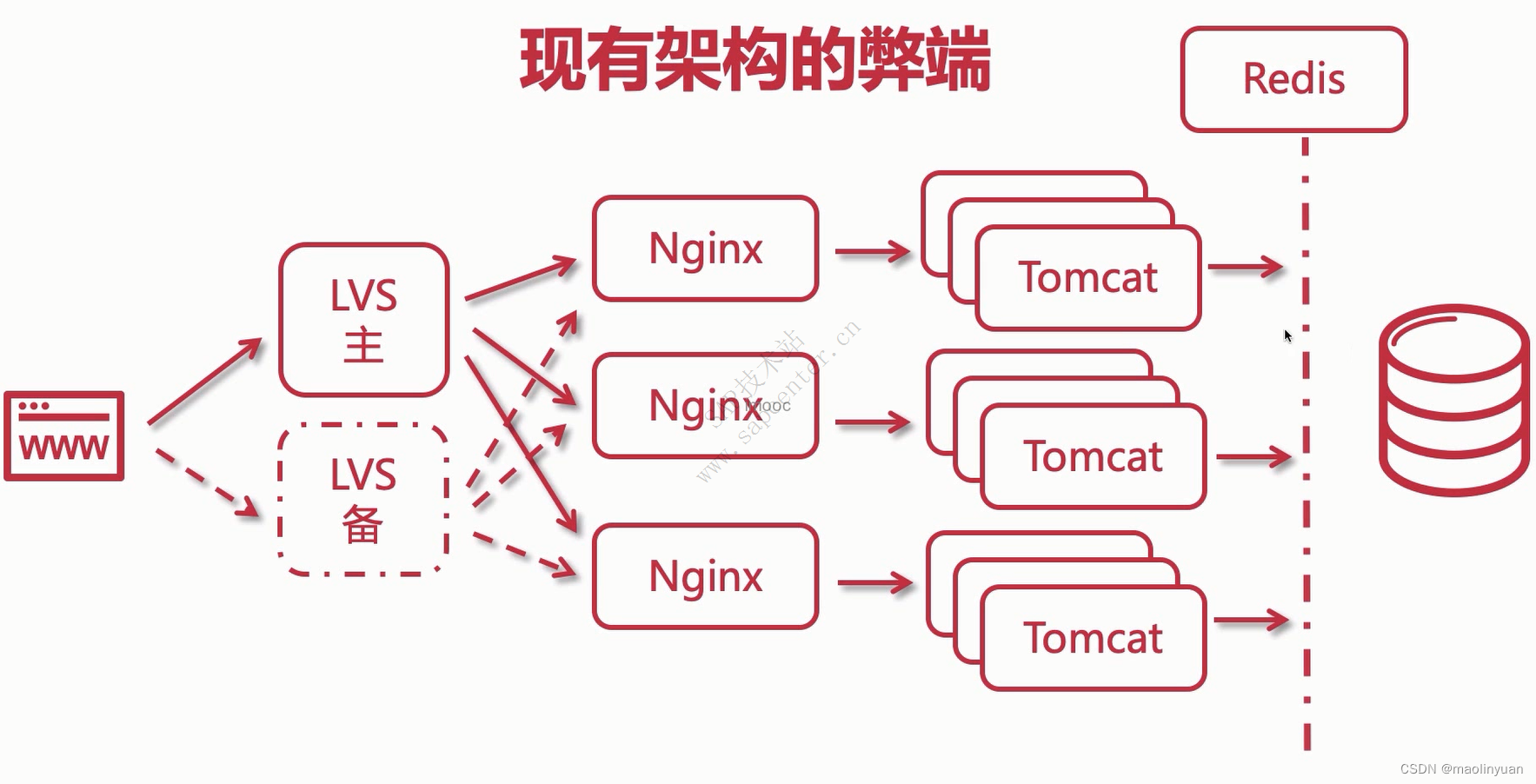
所以,我们可以使用Redis缓存把应用服务和数据库分隔开,把一些热点数据和不经常变动的数据放到缓存中,让上亿的请求访问到Redis,而不会直接接触数据库,从而达到保护数据库的效果。相当于提高了数据库的读取这类型数据的性能,也就是提高了应用服务的性能和吞吐量,也可以承载更多的并发。
Redis的作用
动物园中有各种动物,当游客来到动物园中,她想要知道大熊猫有多少只。她去询问管理员时,管理员进去动物园中数了数大熊猫的数量,返回到原来的地方告诉游客她想要知道的信息。这时若客流量突然变大时,管理员对于每一个人的问题都要去动物园中寻找,他就会非常累。
管理员灵机一动想到了一个方法,他每次去动物园中寻找时,把问题和问题对应的结果写到一个账本上。久而久之,账本上记录的问题和数据越来越多。
当他遇到有人问到之前记录过的一个问题时,他就会直接把账本上的问题答案回答给游客,就不用再一次进去动物园中了。这时,他能接待的客流量就增多了。
这时又会出现一个问题,当动物园中动物的数据发生变化之后,账本和真实数据就对应不上了。这就要靠动物园中的维护人员来保证数据的一致性了,当动物园中动物数据发生变化之后,维护人员要及时修改账本的数据,使其数据和真实数据保持一致。
而账本就相当于我们架构中的Redis,管理员和动物园相当于数据库,这样我们应用的并发量和吞吐量也就提高了,当原有数据发生变化时(新增或修改),要及时更新Redis中缓存的数据,保证数据一致性。
什么是NoSql
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
- 平时我们使用的最多的数据库MySql、postgreSql等等都是关系型数据库,NoSql则是非关系型数据库
- 对于关系型数据库来说,是需要把数据存储到库、表、行、字段里,查询的时候根据条件一行一行地去匹配,当量非常大的时候就很耗费时间和资源,尤其是数据是需要从磁盘里去检索
- NoSQL数据库存储原理非常简单(典型的数据类型为k-v),不存在繁杂的关系链,比如mysql查询的时候,需要找到对应的库、表(通常是多个表)以及字段
- NoSQL数据可以存储在内存里,查询速度非常快
- NoSQL在性能表现上虽然能优于关系型数据库,但是它并不能完全替代关系型数据库
- NoSQL因为没有复杂的数据结构,扩展非常容易,支持分布式
传统项目都是使用关系型数据库,访问量也不是很大,任何请求过来直接查询数据库也不会造成什么影响。当今互联网中数据量越来越大,请求数和并发要求越来越高,而传统的纯数据库架构设计慢慢的不能满足我们的需求。普通的关系型数据库不再适合把超大量的数据提供出去做并发型的查询(用户信息,地理信息,购物信息等)。数据库单表的性能是有限的,数据库做的好优化的好的话单表数据量能到达400w-600w的样子,而一般一点的最多只能到300w-400w,就会对应用的性能造成很大的影响。

一旦数据量达到300w时,数据库管理员(DBA)就要及时准备数据库的优化方案,从而的对数据库进行优化。数据库的数据量庞大之后,关系型数据库也不适合对数据进行深挖(数据挖掘、大数据分析等)。这时使用NoSql就是顺势而为,NoSql水平(横向)扩展非常方便高效。Redis的数据结构是key-value的这种结构,存储形式是非常简单的,所以扩展起来就非常容易,而且由于是键值对这种形式,增加或者删除缓存中的数据会非常高效。数据库中数据量到达上百万的话,数据库中增加和删除数据性能会非常差,若是针对字段的新增或者删除其对性能的影响更是灾难性的,对于整体的数据会有非常大的影响。
对于Redis来说,它的读取性能是非常高的,每秒能达到十万次,远远大于传统关系型数据库。还能搭建集群,而且非常容易。可以存储数据,也可以对于缓存的数据进行持久化(不同的NoSql,对于持久化的支持情况不同)。
NoSql的分类

键值对数据库
相关产品:Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached
应用:内容缓存
优点:扩展性好、灵活性好、大量写操作时性能高
缺点:无法存储结构化信息、条件查询效率较低
使用者:百度云(Redis)、GitHub(Riak)、BestBuy(Riak)、Twitter(Ridis和Memcached)
列存储数据库
相关产品:BigTable、HBase、Cassandra、HadoopDB、GreenPlum、PNUTS
应用:分布式数据存储与管理
优点:查找速度快、可扩展性强、容易进行分布式扩展、复杂性低
使用者:Ebay(Cassandra)、Instagram(Cassandra)、NASA(Cassandra)、Facebook(HBase)
文档型数据库
相关产品:MongoDB、CouchDB、ThruDB、CloudKit、Perservere、Jackrabbit
应用:存储、索引并管理面向文档的数据或者类似的半结构化数据
优点:性能好、灵活性高、复杂性低、数据结构灵活
缺点:缺乏统一的查询语言
使用者:百度云数据库(MongoDB)、SAP(MongoDB)
图形数据库
相关产品:Neo4J、OrientDB、InfoGrid、GraphDB
应用:大量复杂、互连接、低结构化的图结构场合,如社交网络、推荐系统等
优点:灵活性高、支持复杂的图形算法、可用于构建复杂的关系图谱
缺点:复杂性高、只能支持一定的数据规模
使用者:Adobe(Neo4J)、Cisco(Neo4J)、T-Mobile(Neo4J)
参考链接:
总结:Redis、Memcached、MongoDB是国内使用的最多的数据库,假如一个项目没有使用到任何一个NoSql则可以断定这是一个非常传统的项目
什么是分布式缓存
在高并发的分布式的系统中,缓存是必不可少的一部分。没有缓存对系统的加速和阻挡大量的请求直接落到系统的底层,系统是很难撑住高并发的冲击,所以分布式系统中缓存的设计是很重要的一环。
在高并发的场景下,通过分布式缓存可以提高数据的读取数据,相应的应用的性能和吞吐量就提高了。这里只针对读操作,读取数据时尽量在缓存中读取,可以降低数据库对服务器性能的开支,降低服务器的压力,而写操作时才把数据直接写到数据库,这里遵循二八原则(百分之八十都是读操作)。Redis是基于内存的,读写性能远远高于磁盘存储的数据库。一般情况下,尽量让大部分查询请求去命中缓存,少量的请求根据需要直接操作数据库。在分布式系统中,分布式缓存中的数据可以被所有服务访问到,可以很轻松的实现服务之间数据的共享。
使用缓存我们得到以下收益:
加速读写。因为缓存通常是全内存的,比如Redis、Memcache。对内存的直接读写会比传统的存储层如MySQL,性能好很多。举个例子:同等配置单机Redis QPS可轻松上万,MySQL则只有几千。加速读写之后,响应时间加快,相比之下系统的用户体验能得到更好的提升。
降低后端的负载。缓存一些复杂计算或者耗时得出的结果可以降低后端系统对CPU、IO、线程这些资源的需求,让系统运行在一个相对资源健康的环境。
但随之以来也有一些成本:
- 数据不一致性:缓存层与存储层的数据存在着一定时间窗口一致,时间窗口与缓存的过期时间更新策略有关。
- 代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增加了开发者维护代码的成本。
- 运维成本:引入缓存层,比如Redis。为保证高可用,需要做主从,高并发需要做集群。
综合起来,只要收益大于成本,我们就可以采用缓存。
参考链接:
缓存方案的对比
Ehcache
Ehcache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认CacheProvider。Ehcache是一种广泛使用的开源Java分布式缓存。主要面向通用缓存,Java EE和轻量级容器。它具有内存和磁盘存储、缓存加载器、缓存扩展、缓存异常处理程序、一个gzip缓存servlet过滤器、支持REST和SOAP API等特点。
Spring 提供了对缓存功能的抽象:即允许绑定不同的缓存解决方案(如Ehcache),但本身不直接提供缓存功能的实现。它支持注解方式使用缓存,非常方便。
特性
- 快速、简单
- 多种缓存策略
- 缓存数据有两级:内存和磁盘,因此无需担心容量问题
- 缓存数据会在虚拟机
重启的过程中写入磁盘 - 可以通过RMI、可插入API等方式进行分布式缓存
- 具有缓存和缓存管理器的侦听接口
- 支持
多缓存管理器实例,以及一个实例的多个缓存区域 - 提供Hibernate的缓存实现
优点

- 基于Java开发:对于Java项目的整合,其代码的健壮性比较好
- 基于JVM缓存:在JVM中使用的话,速度比较快,性能也会更高
- 简单、轻巧、方便:整合起来非常容易,很多框架都整合了Ehchache,例如:hibernate
缺点

- 集群不支持:不支持缓存共享,对于集群的实现非常复杂,维护起来也非常不方便
- 分布式不支持:Ehchache更加适合于单应用以及快速开发
集成
可以单独使用,一般在第三方库中被用到的比较多(如mybatis、shiro等)Ehcache 对分布式支持不够好,多个节点不能同步,通常和redis一块使用
灵活性
Ehcache具备对象api接口和可序列化api接口
不能序列化的对象可以使用出磁盘存储外Ehcache的所有功能
支持基于Cache和基于Element的过期策略,每个Cache的存活时间都是可以设置和控制的。
提供了LRU、LFU和FIFO缓存淘汰算法,Ehcache 1.2引入了最少使用和先进先出缓存淘汰算法,构成了完整的缓存淘汰算法。
提供内存和磁盘存储,Ehcache和大多数缓存解决方案一样,提供高性能的内存和磁盘存储。
动态、运行时缓存配置,存活时间、空闲时间、内存和磁盘存放缓存的最大数目都是可以在运行时修改的。
应用持久化
在jvm重启后,持久化到磁盘的存储可以复原数据
Ehache是第一个引入缓存数据持久化存储的开源java缓存框架,缓存的数据可以在机器重启后从磁盘上重新获得
根据需要将缓存刷到磁盘。将缓存条目刷到磁盘的操作可以通过cache.fiush方法执行,这大大方便了Ehcache的使用
Ehcache和Redis 比较
- Ehcache直接在jvm虚拟机中缓存,速度快,效率高;但是缓存共享麻烦,集群分布式应用不方便。
- Redis是通过socket访问到缓存服务,效率比Ecache低,比数据库要快很多,处理集群和分布式缓存方便,有成熟的方案。如果是单个应用或者对缓存访问要求很高的应用,用Ehcache。如果是大型系统,存在缓存共享、分布式部署、缓存内容很大的,建议用Redis。
参考链接:
Memcache
Memcache是一个自由、源码开放、高性能、分布式的分布式内存对象缓存系统,用于动态Web应用以减轻数据库的负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度。Memcache是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)所使用的key-value存储,数据可以来自数据库调用、API调用,或者页面渲染的结果。Memcache设计理念就是小而强大,它简单的设计促进了快速部署、易于开发并解决面对大规模的数据缓存的许多难题,而所开放的API使得Memcache能用于Java、C/C++/C#、Perl、Python、PHP、Ruby等大部分流行的程序语言。
Memcache通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。简单的说就是将数据调用到内存中,然后从内存中读取,从而大大提高读取速度。Memcached是以守护程序(监听)方式运行于一个或多个服务器中,随时会接收客户端的连接和操作。
另外,说一下Memcache和Memcached的区别:
Memcache是项目的名称
Memcached是Memcache服务器端可以执行文件的名称
特性和限制
- 在 Memcached中可以保存的item数据量是没有限制的,只要内存足够 。
- Memcached单进程在32位系统中最大使用内存为2G,若在64位系统则没有限制,这是由于32位系统限制单进程最多可使用2G内存,要使用更多内存,可以分多个端口开启多个Memcached进程 。
- 最大30天的数据过期时间,设置为永久的也会在这个时间过期,常量REALTIME_MAXDELTA 60 * 60 * 24 * 30控制
- 最大键长为250字节,大于该长度无法存储,常量KEY_MAX_LENGTH 250控制
- 单个item最大数据是1MB,超过1MB数据不予存储,常量POWER_BLOCK 1048576进行控制,它是默认的slab大小
- Memcache服务端是不安全的,比如已知某个Memcache节点,可以直接telnet过去,并通过flush_all让已经存在的键值对立即失效
- Memcache的高性能源自于两阶段哈希结构:第一阶段在客户端,通过Hash算法根据Key值算出一个节点;第二阶段在服务端,通过一个内部的Hash算法,查找真正的item并返回给客户端。从实现的角度看,Memcache是一个非阻塞的、基于事件的服务器程序
- 最大同时连接数是200,通过 conn_init()中的freetotal进行控制,最大软连接数是1024,通过 settings.maxconns=1024 进行控制
- 跟空间占用相关的参数:settings.factor=1.25, settings.chunk_size=48, 影响slab的数据占用和步进方式
- memcached是一种无阻塞的socket通信方式服务,基于libevent库,由于无阻塞通信,对内存读写速度非常之快。
- memcached分服务器端和客户端,可以配置多个服务器端和客户端,应用于分布式的服务非常广泛。
- memcached作为小规模的数据分布式平台是十分有效果的。
- memcached是键值一一对应,key默认最大不能超过128个字 节,value默认大小是1M,也就是一个slabs,如果要存2M的值(连续的),不能用两个slabs,因为两个slabs不是连续的,无法在内存中 存储,故需要修改slabs的大小,多个key和value进行存储时,即使这个slabs没有利用完,那么也不会存放别的数据。
- memcached已经可以支持C/C++、Perl、PHP、Python、Ruby、Java、C#、Postgres、Chicken Scheme、Lua、MySQL和Protocol等语言客户端
参考链接:
优点

- 部分容灾:假设只用一台Memcache,如果这台Memcache服务器挂掉了,那么请求将不断的冲击数据库,这样有可能搞死数据库,从而引发”雪崩“。如果使用多台Memcache服务器,由于Memcache使用一致性哈希算法,万一其中一台挂掉了,部分请求还是可以在Memcache中命中,为修复系统赢得一些时间。
- 横向扩展简单:一台Memcache服务器的容量毕竟有限,可以使用多台Memcache服务器,增加缓存容量。
- 均衡请求:使用多台Memcache服务器,可以均衡请求,避免所有请求都冲进一台Memcache服务器,导致服务器挂掉。
- 多核运行:Memcache 可以利用多核优势,单实例吞吐量极高,可以达到几十万 QPS(取决于 key、value 的字节大小以及服务器硬件性能,日常环境中 QPS 高峰大约在 4-6w 左右)。适用于最大程度扛量。
- 支持直接配置为 session handle。
缺点

只支持简单的 key/value 数据结构,不像 Redis 可以支持丰富的数据类型。
无法进行持久化,数据不能备份,只能用于缓存使用,且重启后数据全部丢失。
无法进行数据同步,不能将Memcache中的数据迁移到其他Memcache实例中。
Memcached 内存分配采用 Slab Allocation 机制管理内存,value 大小分布差异较大时会造成内存利用率降低,并引发低利用率时依然出现踢出等问题。需要用户注重 value 设计。
Memcache和Redis比较
- 持久化能力:Redis支持持久化,Memcache也支持但一般不做持久化(重启丢失数据)
- 数据类型支持:Redis类型较多(5种数据类型,string、list、hash、set、sorted set),Memcache只能是字符串
- 线程模型:Redis是单线程+多路IO复用,虽然没有锁冲突,但很难利用多核特性提升整体吞吐量。Memcache是多线程+锁的方式,主线程监听,work子线程接收请求,执行读写,有锁冲突。;
- 数据库特征:Redis不是所有的数据都存储在内存,在很多方面具备数据库的特征,Memcache只是简单的kv缓存;相当于Memcache更像是redis在功能上的一个子集。
- 高可用支持:高可用(redis原生支持高可用功能,可以实现主从复制,哨兵模式,redis集群模式,而Memcache要实现高可用,需要进行二次开发,例如客户端的双读双写,或者服务端的集群同步)(延伸:虽然数据类型单一,但是Memcache的内存管理机制导致无碎片,这让Memcache工作更加稳定,而redis本身也考虑到自己功能复杂,会产生碎片,并且容易崩溃,所以支持高可用)
- 内容大小比较:Redis存储的内容比较大(Memcache的value存储最大是1M,如果存储value很大,只能选择redis)
- 内存分配:memchache使用预分配内存池的方式管理内存,能够省区内存分配的时间,这个节省的时间在数据量很大的时候还是很可观的。而redis则是临时申请空间,可能导致碎片。Redis和Memcache在写入性能上面差别不大的,读取性能上面尤其是批量读取性能上面Memcache更强的。
参考链接:
Redis
简单来说 Redis 就是一个用C语言写的数据库,不过与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。另外,Redis 也经常用来做分布式锁。Redis 提供了多种数据类型来支持不同的业务场景。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
Redis是一个开源的,先进的key-value持久化产品。它通常被称为数据结构服务器,它的值可以是字符串(String)、哈希(Map)、列表(List)、集合(Sets)和有序集合(Sorted sets)等类型。可以在这些类型上面做一些原子操作,如:字符串追加、增加Hash里面的值、添加元素到列表、计算集合的交集,并集和差集;或者区有序集合中排名最高的成员。为了取得好的性能,Redis是一个内存型数据库。不限于此,Redis也可以把数据持久化到磁盘中,或者把数据操作指令追加了一个日志文件,把它用于持久化。也可以用Redis容易的搭建master-slave架构用于数据复制。其它让它像缓存的特性包括,简单的check-and-set机制,pub/sub和配置设置。Redis可以用大部分程序语言来操作:C、C++、C#、Java、Node.js、php、ruby等等。
特性
速度快
正常情况下,Redis执行命令的速度非常快,官方给出的数字是读写性能可以达到10万/秒,当然这也取决于机器的性能,但这里先不讨论机器性能上的差异,只分析一下是什么造就了Redis除此之快的速度,可以大致归纳为以下三点:
- Redis的所有数据都是存放在内存中的,所以把数据放在内存中是Redis速度快的最主要原因。
- Redis是用C语言实现的,一般来说C语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- Redis使用了单线程架构,预防了多线程可能产生的竞争问题。
基于键值对的数据结构服务器
几乎所有的编程语言都提供了类似字典的功能,例如Java里的map、Python里的dict,类似于这种组织数据的方式叫作基于键值的方式,与很多键值对数据库不同的是,Redis中的值不仅可以是字符串,而且还可以是具体的数据结构,这样不仅能便于在许多应用场景的开发,同时也能够提高开发效率。Redis的全称是REmote Dictionary Server,它主要提供了5种数据结构:字符串、哈希、列表、集合、有序集合。
丰富的功能
除了5种数据结构,Redis还提供了许多额外的功能:
- 提供了键过期功能,可以用来实现缓存。
- 提供了发布订阅功能,可以用来实现消息系统。
- 支持Lua脚本功能,可以利用Lua创造出新的Redis命令。
- 提供了简单的事务功能,能在一定程度上保证事务特性。
- 提供了流水线(Pipeline)功能,这样客户端能将一批命令一次性传到Redis,减少了网络的开销。
简单稳定
Redis的简单主要表现在三个方面。
- Redis的源码很少。
- Redis使用单线程模型,这样不仅使得Redis服务端处理模型变得简单,而且也使得客户端开发变得简单。
- Redis不需要依赖于操作系统中的类库(例如Memcache需要依赖libevent这样的系统类库),Redis自己实现了事件处理的相关功能。
- Redis虽然很简单,但是不代表它不稳定。维护的上千个Redis为例,没有出现过因为Redis自身bug而宕掉的情况。
客户端语言多
Redis提供了简单的TCP通信协议,很多编程语言可以很方便地接入到Redis,并且由于Redis受到社区和各大公司的广泛认可,所以支持Redis的客户端语言也非常多,几乎涵盖了主流的编程语言,例如Java、PHP、Python、C、C++、Nodejs等。
持久化
通常看,将数据放在内存中是不安全的,一旦发生断电或者机器故障,重要的数据可能就会丢失,因此Redis提供了两种持久化方式:RDB和AOF,即可以用两种策略将内存的数据保存到硬盘中(如图所示)这样就保证了数据的可持久性。
主从复制
Redis提供了复制功能,实现了多个相同数据的Redis副本(如图所示),复制功能是分布式Redis的基础。
高可用和分布式
Redis从2.8版本正式提供了高可用实现Redis Sentinel,它能够保证Redis节点的故障发现和故障自动转移。Redis从3.0版本正式提供了分布式实现Redis Cluster,它是Redis真正的分布式实现,提供了高可用、读写和容量的扩展性。
参考链接:
优点

- 支持多种数据类型:包括set,zset,list,hash,string这五种数据类型,操作非常方便。比如,如果你在做好友系统,查看自己的好友关系,如果采用其他的key-value系统,则必须把对应的好友拼接成字符串,然后在提取好友时,再把value进行解析,而Redis则相对简单,直接支持list的存储(采用双向链表或者压缩链表的存储方式)。
- 持久化存储:作为一个内存数据库,最担心的,就是万一机器死机,数据会消失掉。redi使用rdb和aof做数据的持久化存储。主从数据同时,生成rdb文件,并利用缓冲区添加新的数据更新操作做对应的同步。
- 丰富的特性:pub/sub,key过期策略,事务,支持多个DB等。
- 性能很好:由于是全内存操作,所以读写性能很好,可以达到10w/s的频率。公司有项目使用Redis,目前的访问频率是80w/s,通过适当的部署,线上运行一切ok。
缺点

- 由于是内存数据库,所以,单台机器,存储的数据量,跟机器本身的内存大小。虽然Redis本身有key过期策略,但是还是需要提前预估和节约内存。如果内存增长过快,需要定期删除数据。
- 如果进行完整重同步,由于需要生成rdb文件,并进行传输,会占用主机的CPU,并会消耗现网的带宽。不过Redis2.8版本,已经有部分重同步的功能,但是还是有可能有完整重同步的。比如,新上线的备机。
- 修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中,Redis不能提供服务。
相关问题
数据库和缓存双写一致性问题:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
缓存穿透:即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。解决方案:
- 利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
- 采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
- 提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
缓存雪崩:即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。解决方案:
- 给缓存的失效时间,加上一个随机值,避免集体失效。
- 使用互斥锁,但是该方案吞吐量明显下降了。
- 双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
- 从缓存A读数据库,有则直接返回
- A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
- 更新线程同时更新缓存A和缓存B。
缓存的并发竞争:同时有多个子系统去set一个key。
如果对这个key操作,不要求顺序:这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
如果对这个key操作,要求顺序:(假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC)期望按照key1的value值按照 valueA–>valueB–>valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下:
- 系统A key 1 {valueA 3:00}
- 系统B key 1 {valueB 3:05}
- 系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
Redis的过期策略以及内存淘汰机制:Redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略。
定期删除+惰性删除是如何工作的呢?
定期删除,Redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,Redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,Redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。于是,惰性删除派上用场。也就是说在你获取某个key的时候,Redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,Redis的内存会越来越高。那么就应该采用内存淘汰机制。
在redis.conf中有一行配置:
# maxmemory-policy volatile-lru
该配置就是配内存淘汰策略的
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把Redis既当缓存,又做持久化存储的时候才用。不推荐
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
- ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
参考链接:
Redis的使用
Redis的安装和配置
打开官网:https://redis.io (中文官网:http://www.redis.cn)点击下载最新版本的Redis
上传到Linux服务器

解压安装包
tar -zxvf redis.xxxx.tar.gz
进入解压缩之后的文件夹,可以发现其中有一个Makefile文件,因此安装方式和Nginx类似
因为是C语言编写的,所以安装gcc的编译环境
yum install gcc-c++
编译
make
当最后看到:Hint: It’s a good idea to run ‘make test’ 😉
说明编译成功了
安装
make install
拷贝Redis解压目录中的utils文件夹下的启动脚本到系统目录中,以备后用
cp ./utils/redis_init_script /etc/init.d/
创建配置文件所在的文件夹以及Redis的工作空间
mkdir /usr/local/redis -p
mkdir /usr/local/redis/db -p
拷贝redis.conf文件夹到创建的目录中
cp ./redis.conf /usr/local/redis/redis.conf
修改配置文件
vim /usr/local/redis/redis.conf
修改以下配置项
- 设置后台启动:daemonize yes
- 设置工作空间:dir /usr/local/redis/db
- 设置允许访问Redis服务的ip:bind 0.0.0.0
- 修改访问密码(此项配置默认是关闭的):requirepass imooc
部分配置项:
daemonize yes #是否以后台进程运行 pidfile /var/run/redis/redis-server.pid #pid文件位置 port 6379#监听端口 bind 127.0.0.1 #绑定地址,如外网需要连接,设置0.0.0.0 timeout 300 #连接超时时间,单位秒 loglevel notice #日志级别,分别有: # debug :适用于开发和测试 # verbose :更详细信息 # notice :适用于生产环境 # warning :只记录警告或错误信息 logfile /var/log/redis/redis-server.log #日志文件位置 syslog-enabled no #是否将日志输出到系统日志 databases 16#设置数据库数量,默认数据库为0 ############### 快照方式 ############### save 900 1 #在900s(15m)之后,至少有1个key发生变化,则快照 save 300 10 #在300s(5m)之后,至少有10个key发生变化,则快照 save 60 10000 #在60s(1m)之后,至少有1000个key发生变化,则快照 rdbcompression yes #dump时是否压缩数据 dir /var/lib/redis #数据库(dump.rdb)文件存放目录 ############### 主从复制 ############### slaveof <masterip> <masterport> #主从复制使用,用于本机redis作为slave去连接主redis masterauth <master-password> #当master设置密码认证,slave用此选项指定master认证密码 slave-serve-stale-data yes #当slave与master之间的连接断开或slave正在与master进行数据同步时,如果有slave请求,当设置为yes时,slave仍然响应请求,此时可能有问题,如果设置no时,slave会返回"SYNC with master in progress"错误信息。但INFO和SLAVEOF命令除外。 ############### 安全 ############### requirepass foobared #配置redis连接认证密码 ############### 限制 ############### maxclients 128#设置最大连接数,0为不限制 maxmemory <bytes>#内存清理策略,如果达到此值,将采取以下动作: maxmemory-policy volatile-lru#如果达到maxmemory值,采用此策略 # volatile-lru :默认策略,只对设置过期时间的key进行LRU算法删除 # allkeys-lru :删除不经常使用的key # volatile-random :随机删除即将过期的key # allkeys-random :随机删除一个key # volatile-ttl :删除即将过期的key # noeviction :不过期,写操作返回报错 maxmemory-samples 3 #默认随机选择3个key,从中淘汰最不经常用的 ############### 附加模式 ############### appendonly no #AOF持久化,是否记录更新操作日志,默认redis是异步(快照)把数据写入本地磁盘 appendfilename appendonly.aof #指定更新日志文件名 # AOF持久化三种同步策略: # appendfsync always #每次有数据发生变化时都会写入appendonly.aof # appendfsync everysec #默认方式,每秒同步一次到appendonly.aof # appendfsync no #不同步,数据不会持久化 no-appendfsync-on-rewrite no #当AOF日志文件即将增长到指定百分比时,redis通过调用BGREWRITEAOF是否自动重写AOF日志文件。 ############### 虚拟内存 ############### vm-enabled no #是否启用虚拟内存机制,虚拟内存机将数据分页存放,把很少访问的页放到swap上,内存占用多,最好关闭虚拟内存 vm-swap-file /var/lib/redis/redis.swap #虚拟内存文件位置 vm-max-memory 0 #redis使用的最大内存上限,保护redis不会因过多使用物理内存影响性能 vm-page-size 32 #每个页面的大小为32字节 vm-pages 134217728 #设置swap文件中页面数量 vm-max-threads 4 #访问swap文件的线程数 ############### 高级配置 ############### hash-max-zipmap-entries 512 #哈希表中元素(条目)总个数不超过设定数量时,采用线性紧凑格式存储来节省空间 hash-max-zipmap-value 64 #哈希表中每个value的长度不超过多少字节时,采用线性紧凑格式存储来节省空间 list-max-ziplist-entries 512 #list数据类型多少节点以下会采用去指针的紧凑存储格式 list-max-ziplist-value 64 #list数据类型节点值大小小于多少字节会采用紧凑存储格式 set-max-intset-entries 512 #set数据类型内部数据如果全部是数值型,且包含多少节点以下会采用紧凑格式存储 activerehashing yes #是否激活重置哈希参考链接:
修改Redis启动脚本
vim /etc/init.d/redis_init_script
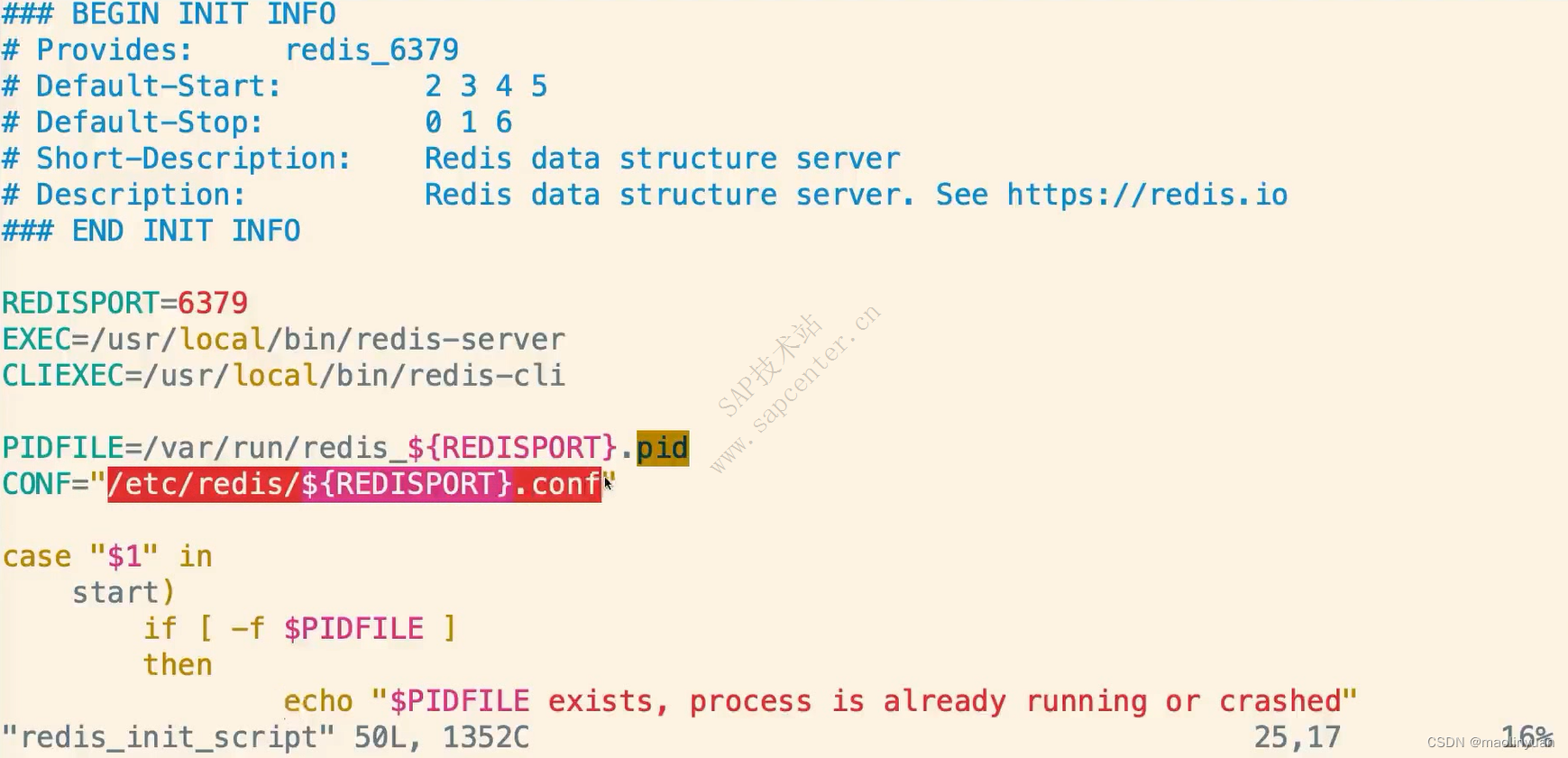
修改脚本的配置文件地址为:
CONF=“/usr/local/redis/redis.conf”
给脚本新增执行权限
chmod 777 /etc/init.d/redis_init_script
使用脚本启动Redis Server
/etc/init.d/redis_init_script start
查看Redis进程是否启动成功
ps -ef | grep redis
在脚本中配置启动级别和描述
在脚本文件中新增以下内容:
# chkconfig: 22345 10 90
# description: Start and Stop redis
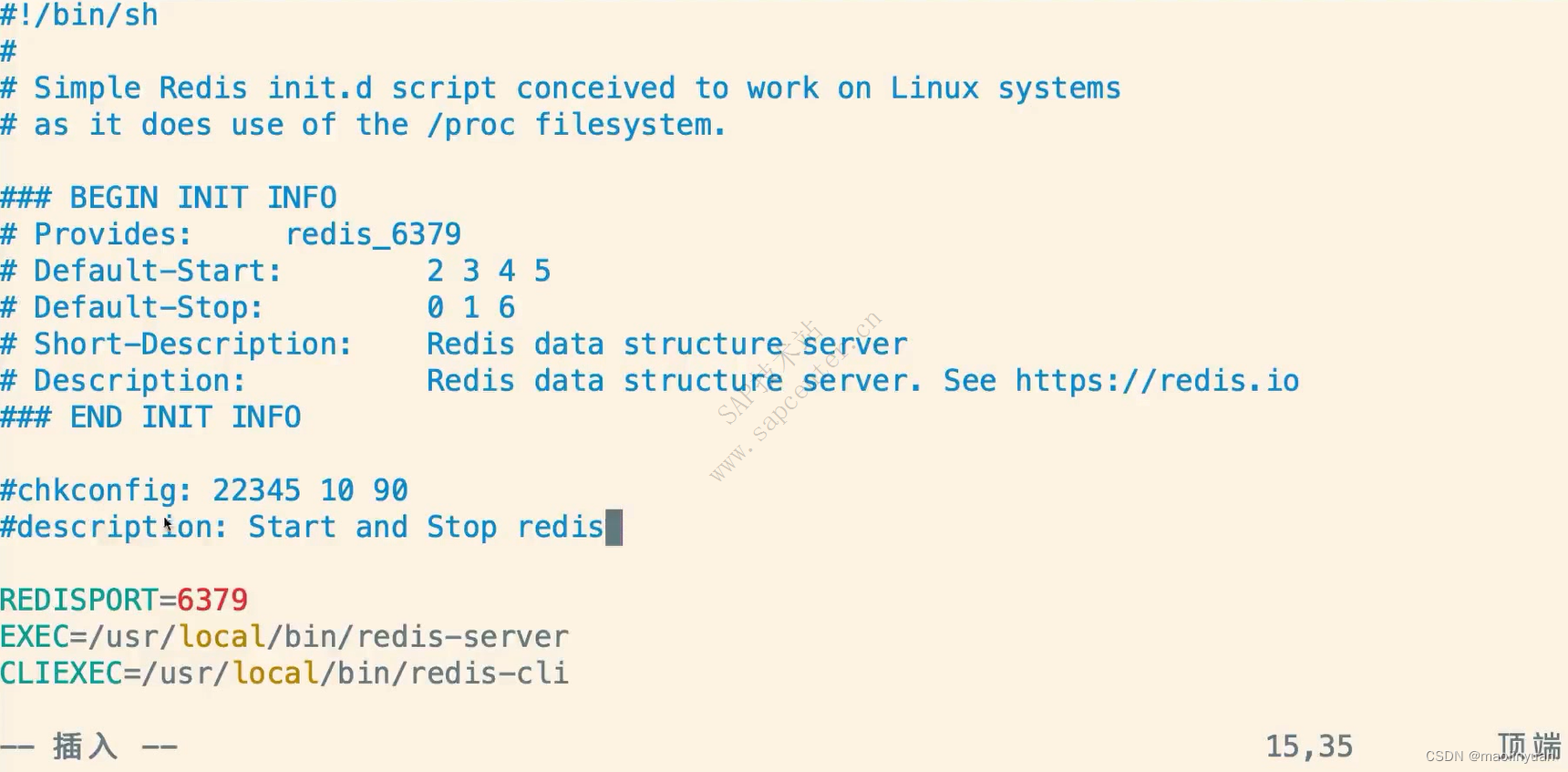
将脚本注册到启动项中
chkconfig redis_init_script on
参考链接:
例子:
# 1.将(脚本)启动文件移动到 /etc/init.d/或者/etc/rc.d/init.d/目录下。(前者是后者的软连接) mv /www/wwwroot/test.sh /etc/rc.d/init.d # 2.启动文件前面务必添加如下三行代码,否侧会提示chkconfig不支持。 #!/bin/sh 告诉系统使用的shell,所以的shell脚本都是这样 #chkconfig: 35 20 80 分别代表运行级别,启动优先权,关闭优先权,此行代码必须 #description: http server 自己随便发挥!!!,此行代码必须 /bin/echo $(/bin/date +%F_%T) >> /tmp/test.log # 3.增加脚本的可执行权限 chmod +x /etc/rc.d/init.d/test.sh # 4.添加脚本到开机自动启动项目中。添加到chkconfig,开机自启动。 [root@localhost ~]# cd /etc/rc.d/init.d [root@localhost ~]# chkconfig --add test.sh [root@localhost ~]# chkconfig test.sh on # 5.关闭开机启动 [root@localhost ~]# chkconfig test.sh off # 6.从chkconfig管理中删除test.sh [root@localhost ~]# chkconfig --del test.sh # 7.查看chkconfig管理 [root@localhost ~]# chkconfig --list test.sh
使用redis-cli工具操作Redis
打开Redis自启动脚本文件,查看redis-cli工具的安装位置
vim /etc/init.d/redis_init_script

使用此工具连接Redis
可以直接输入redis-cli或者输入绝对路径进入使用状态

新开一个连接可以查看工具的此工具的进程,输入
ps -ef | grep redis

当我们使用时发现Redis报错,提示没有授权
是我们连接Redis时没有输入密码的原因

使用时设置密码,使用set命令和get命令操作key-value
使用auth命令后面跟密码进行认证
使用set命令设置key-value键值对
使用get命令获取key对应的value值
使用del命令删除一个键值对
使用ctrl+c直接退出redis-cli客户端工具

参考链接:
在客户端工具之外操作Redis
检测Redis是否存活
redis-cli -p imooc ping

想要停止Redis除了直接kill掉此进程之外,还可以使用脚本文件停止
/etc/init.d/redis_init_script stop
因为设置了密码,它会提示没有权限

打开此脚本
vim /etc/init.d/redis_init_script
在stop部分找到以下位置加上设置的密码

重新执行脚本停止服务

查询是否还有Redis进程
ps -ef | grep redis

redis-cli常用命令
string类型
KEYS pattern
查找所有符合给定模式pattern(正则表达式)的 key 。
时间复杂度为O(N),N为数据库里面key的数量。
例如,Redis在一个有1百万个key的数据库里面执行一次查询需要的时间是40毫秒 。
警告: KEYS的速度非常快,但在一个大的数据库中使用它仍然可能造成性能问题,如果你需要从一个数据集中查找特定的 KEYS, 你最好还是用 Redis 的集合结构 SETS 来代替。
支持的正则表达模式:
h?llo匹配hello,hallo和hxlloh*llo匹配hllo和heeeelloh[ae]llo匹配hello和hallo,但是不匹配hilloh[^e]llo匹配hallo,hbllo, … 但是不匹配helloh[a-b]llo匹配hallo和hbllo
如果你想取消字符的特殊匹配(正则表达式,可以在它的前面加\。
返回值
array-reply: 所有符合条件的key
例子
redis> MSET one 1 two 2 three 3 four 4
OK
redis> KEYS *o*
1) "four"
2) "one"
3) "two"
redis> KEYS t??
1) "two"
redis> KEYS *
1) "four"
2) "three"
3) "one"
4) "two"
redis>
SET key value [EX seconds] [PX milliseconds] [NX|XX]
将键key设定为指定的“字符串”值。
如果 key 已经保存了一个值,那么这个操作会直接覆盖原来的值,并且忽略原始类型。
当set命令执行成功之后,之前设置的过期时间都将失效
选项
从2.6.12版本开始,redis为SET命令增加了一系列选项:
EXseconds – Set the specified expire time, in seconds.PXmilliseconds – Set the specified expire time, in milliseconds.NX– Only set the key if it does not already exist.XX– Only set the key if it already exist.EXseconds – 设置键key的过期时间,单位时秒PXmilliseconds – 设置键key的过期时间,单位时毫秒NX– 只有键key不存在的时候才会设置key的值XX– 只有键key存在的时候才会设置key的值
注意: 由于SET命令加上选项已经可以完全取代SETNX, SETEX, PSETEX的功能,所以在将来的版本中,redis可能会不推荐使用并且最终抛弃这几个命令。
返回值
simple-string-reply:如果SET命令正常执行那么回返回OK,否则如果加了NX 或者 XX选项,但是没有设置条件。那么会返回nil。
例子
redis> SET mykey "Hello"
OK
redis> GET mykey
"Hello"
redis>
设计模式
注意: 下面这种设计模式并不推荐用来实现redis分布式锁。应该参考the Redlock algorithm的实现,因为这个方法只是复杂一点,但是却能保证更好的使用效果。
命令 SET resource-name anystring NX EX max-lock-time 是一种用 Redis 来实现锁机制的简单方法。
如果上述命令返回OK,那么客户端就可以获得锁(如果上述命令返回Nil,那么客户端可以在一段时间之后重新尝试),并且可以通过DEL命令来释放锁。
客户端加锁之后,如果没有主动释放,会在过期时间之后自动释放。
可以通过如下优化使得上面的锁系统变得更加鲁棒:
- 不要设置固定的字符串,而是设置为随机的大字符串,可以称为token。
- 通过脚步删除指定锁的key,而不是DEL命令。
上述优化方法会避免下述场景:a客户端获得的锁(键key)已经由于过期时间到了被redis服务器删除,但是这个时候a客户端还去执行DEL命令。而b客户端已经在a设置的过期时间之后重新获取了这个同样key的锁,那么a执行DEL就会释放了b客户端加好的锁。
解锁脚本的一个例子将类似于以下:
if redis.call("get",KEYS[1]) == ARGV[1]
then
return redis.call("del",KEYS[1])
else
return 0
end
这个脚本执行方式如下:
EVAL …script… 1 resource-name token-value
GET key
返回key的value。如果key不存在,返回特殊值nil。如果key的value不是string,就返回错误,因为GET只处理string类型的values。
返回值
simple-string-reply:key对应的value,或者nil(key不存在时)
例子
redis> GET nonexisting
(nil)
redis> SET mykey "Hello"
OK
redis> GET mykey
"Hello"
redis>
DEL key [key …]
删除指定的一批keys,如果删除中的某些key不存在,则直接忽略。
返回值
integer-reply: 被删除的keys的数量
例子
redis> SET key1 "Hello"
OK
redis> SET key2 "World"
OK
redis> DEL key1 key2 key3
(integer) 2
redis>
TYPE key
起始版本:1.0.0
时间复杂度:O(1)
返回key所存储的value的数据结构类型,它可以返回string, list, set, zset 和 hash等不同的类型。
返回值
simple-string-reply: 返回当前key的数据类型,如果key不存在时返回none。
例子
redis> SET key1 "value"
OK
redis> LPUSH key2 "value"
(integer) 1
redis> SADD key3 "value"
(integer) 1
redis> TYPE key1
string
redis> TYPE key2
list
redis> TYPE key3
set
redis>
SETNX key value
起始版本:1.0.0
时间复杂度:O(1)
可能会被弃用,因为SET命令可以设置参数来代替此功能
将key设置值为value,如果key不存在,这种情况下等同SET命令。 当key存在时,什么也不做。SETNX是”SET if Not eXists”的简写。
返回值
Integer reply, 特定值:
1如果key被设置了0如果key没有被设置
例子
redis> SETNX mykey "Hello"
(integer) 1
redis> SETNX mykey "World"
(integer) 0
redis> GET mykey
"Hello"
redis>
设计模式:使用!SETNX加锁
请注意:
- 不鼓励以下模式来实现the Redlock algorithm ,该算法实现起来有一些复杂,但是提供了更好的保证并且具有容错性。
- 无论如何,我们保留旧的模式,因为肯定存在一些已实现的方法链接到该页面作为引用。而且,这是一个有趣的例子说明Redis命令能够被用来作为编程原语的。
- 无论如何,即使假设一个单例的加锁原语,但是从 2.6.12 开始,可以创建一个更加简单的加锁原语,相当于使用
SET命令来获取锁,并且用一个简单的 Lua 脚本来释放锁。该模式被记录在SET命令的页面中。
也就是说,SETNX能够被使用并且以前也在被使用去作为一个加锁原语。例如,获取键为foo的锁,客户端可以尝试一下操作:
SETNX lock.foo <current Unix time + lock timeout + 1>
如果客户端获得锁,SETNX返回1,那么将lock.foo键的Unix时间设置为不在被认为有效的时间。客户端随后会使用DEL lock.foo去释放该锁。
如果SETNX返回0,那么该键已经被其他的客户端锁定。如果这是一个非阻塞的锁,才能立刻返回给调用者,或者尝试重新获取该锁,直到成功或者过期超时。
处理死锁
以上加锁算法存在一个问题:如果客户端出现故障,崩溃或者其他情况无法释放该锁会发生什么情况?这是能够检测到这种情况,因为该锁包含一个Unix时间戳,如果这样一个时间戳等于当前的Unix时间,该锁将不再有效。
当以下这种情况发生时,我们不能调用DEL来删除该锁,并且尝试执行一个SETNX,因为这里存在一个竞态条件,当多个客户端察觉到一个过期的锁并且都尝试去释放它。
- C1 和 C2 读
lock.foo检查时间戳,因为他们执行完SETNX后都被返回了0,因为锁仍然被 C3 所持有,并且 C3 已经崩溃。 - C1 发送
DEL lock.foo - C1 发送
SETNX lock.foo命令并且成功返回 - C2 发送
DEL lock.foo - C2 发送
SETNX lock.foo命令并且成功返回 - 错误:由于竞态条件导致 C1 和 C2 都获取到了锁
幸运的是,可以使用以下的算法来避免这种情况,请看 C4 客户端所使用的好的算法:
C4 发送
SETNX lock.foo为了获得该锁已经崩溃的客户端 C3 仍然持有该锁,所以Redis将会返回
0给 C4C4 发送
GET lock.foo检查该锁是否已经过期。如果没有过期,C4 客户端将会睡眠一会,并且从一开始进行重试操作另一种情况,如果因为
lock.foo键的Unix时间小于当前的Unix时间而导致该锁已经过期,C4 会尝试执行以下的操作:GETSET lock.foo <current Unix timestamp + lock timeout + 1>由于
GETSET的语意,C4会检查已经过期的旧值是否仍然存储在lock.foo中。如果是的话,C4 会获得锁如果另一个客户端,假如为 C5 ,比 C4 更快的通过
GETSET操作获取到锁,那么 C4 执行GETSET操作会被返回一个不过期的时间戳。C4 将会从第一个步骤重新开始。请注意:即使 C4 在将来几秒设置该键,这也不是问题。
为了使这种加锁算法更加的健壮,持有锁的客户端应该总是要检查是否超时,保证使用DEL释放锁之前不会过期,因为客户端故障的情况可能是复杂的,不止是崩溃,还会阻塞一段时间,阻止一些操作的执行,并且在阻塞恢复后尝试执行DEL(此时,该LOCK已经被其他客户端所持有
TTL key
起始版本:1.0.0
时间复杂度:O(1)
返回key剩余的过期时间。 这种反射能力允许Redis客户端检查指定key在数据集里面剩余的有效期。
在Redis 2.6和之前版本,如果key不存在或者已过期时返回-1。
从Redis2.8开始,错误返回值的结果有如下改变:
- 如果key不存在或者已过期,返回
-2 - 如果key存在并且没有设置过期时间(永久有效),返回
-1。
另见PTTL命令返回相同的信息,只不过他的时间单位是毫秒(仅适用于Redis 2.6及更高版本)。
返回值
Integer reply: key有效的秒数(TTL in seconds),或者一个负值的错误 (参考上文)。
例子
redis> SET mykey "Hello"
OK
redis> EXPIRE mykey 10 # 设置mykey 10秒后过期
(integer) 1
redis> TTL mykey # 查看mykey剩余的过期时间
(integer) 10
redis>
EXPIRE key seconds
起始版本:1.0.0
时间复杂度:O(1)
设置key的过期时间,超过时间后,将会自动删除该key。在Redis的术语中一个key的相关超时是不确定的。
超时后只有对key执行DEL命令或者SET命令或者GETSET时才会清除。 这意味着,从概念上讲所有改变key的值的操作都会使他清除。 例如,INCR递增key的值,执行LPUSH操作,或者用HSET改变hash的field所有这些操作都会触发删除动作。
使用PERSIST命令可以清除超时,使其变成一个永久的key。
如果key被RENAME命令修改,相关的超时时间会转移到新key上面。
如果key被RENAME命令修改,比如原来就存在Key_A,然后调用RENAME Key_B Key_A命令,这时不管原来Key_A是永久的还是设置为超时的,都会由Key_B的有效期状态覆盖。
刷新过期时间
对已经有过期时间的key执行EXPIRE操作,将会更新它的过期时间。有很多应用有这种业务场景,例如记录会话的session。
返回值
integer-reply, 具体的:
1如果成功设置过期时间。0如果key不存在或者不能设置过期时间。
例子
redis> SET mykey "Hello"
OK
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 10
redis> SET mykey "Hello World"
OK
redis> TTL mykey
(integer) -1
redis>
案例: Navigation session
想象一下,你有一个网络服务器,你对用户最近访问的N个网页感兴趣,每一个相邻的页面设置超时时间为60秒。在概念上你为这些网页添加Navigation session,如果你的用户,可能包含有趣的信息,他或她正在寻找什么样的产品,你可以推荐相关产品。
你可以使用下面的策略模型,使用这种模式:每次用户浏览网页调用下面的命令:
MULTI
RPUSH pagewviews.user:<userid> http://.....
EXPIRE pagewviews.user:<userid> 60
EXEC
如果用户60秒没有操作,这个key将会被删除,不到60秒的话,后续网页将会被继续记录。
附录: Redis 过期时间
Keys的过期时间
通常Redis keys创建时没有设置相关过期时间。他们会一直存在,除非使用显示的命令移除,例如,使用DEL命令。
EXPIRE一类命令能关联到一个有额外内存开销的key。当key执行过期操作时,Redis会确保按照规定时间删除他们。key的过期时间和永久有效性可以通过
EXPIRE和PERSIST命令(或者其他相关命令)来进行更新或者删除过期时间。过期精度
在 Redis 2.4 及以前版本,过期期时间可能不是十分准确,有0-1秒的误差。
从 Redis 2.6 起,过期时间误差缩小到0-1毫秒。
过期和持久
Keys的过期时间使用Unix时间戳存储(从Redis 2.6开始以毫秒为单位)。这意味着即使Redis实例不可用,时间也是一直在流逝的。
要想过期的工作处理好,计算机必须采用稳定的时间。 如果你将RDB文件在两台时钟不同步的电脑间同步,有趣的事会发生(所有的 keys装载时就会过期)。
即使正在运行的实例也会检查计算机的时钟,例如如果你设置了一个key的有效期是1000秒,然后设置你的计算机时间为未来2000秒,这时key会立即失效,而不是等1000秒之后。
Redis如何淘汰过期的keys
Redis keys过期有两种方式:被动和主动方式。
当一些客户端尝试访问它时,key会被发现并主动的过期。
当然,这样是不够的,因为有些过期的keys,永远不会访问他们。 无论如何,这些keys应该过期,所以定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
- 测试随机的20个keys进行相关过期检测。
- 删除所有已经过期的keys。
- 如果有多于25%的keys过期,重复步奏1.
这是一个平凡的概率算法,基本上的假设是,我们的样本是这个密钥控件,并且我们不断重复过期检测,直到过期的keys的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期keys。
在复制AOF文件时如何处理过期
为了获得正确的行为而不牺牲一致性,当一个key过期,
DEL将会随着AOF文字一起合成到所有附加的slaves。在master实例中,这种方法是集中的,并且不存在一致性错误的机会。然而,当slaves连接到master时,不会独立过期keys(会等到master执行DEL命令),他们任然会在数据集里面存在,所以当slave当选为master时淘汰keys会独立执行,然后成为master。
APPEND key value
起始版本:2.0.0
时间复杂度:O(1)。均摊时间复杂度是O(1), 因为redis用的动态字符串的库在每次分配空间的时候会增加一倍的可用空闲空间,所以在添加的value较小而且已经存在的 value是任意大小的情况下,均摊时间复杂度是O(1) 。
如果 key 已经存在,并且值为字符串,那么这个命令会把 value 追加到原来值(value)的结尾。 如果 key 不存在,那么它将首先创建一个空字符串的key,再执行追加操作,这种情况 APPEND 将类似于 SET 操作。
返回值
Integer reply:返回append后字符串值(value)的长度。
例子
redis> EXISTS mykey
(integer) 0
redis> APPEND mykey "Hello"
(integer) 5
redis> APPEND mykey " World"
(integer) 11
redis> GET mykey
"Hello World"
redis>
模式:节拍序列(Time series)
APPEND 命令可以用来连接一系列固定长度的样例,与使用列表相比这样更加紧凑. 通常会用来记录节拍序列. 每收到一个新的节拍样例就可以这样记录:
APPEND timeseries "fixed-size sample"
在节拍序列里, 可以很容易地访问序列中的每个元素:
- STRLEN 可以用来计算样例个数.
- GETRANGE 允许随机访问序列中的各个元素. 如果序列中有明确的节拍信息, 在Redis 2.6中就可以使用GETRANGE配合Lua脚本来实现一个二分查找算法.
- SETRANGE 可以用来覆写已有的节拍序列.
该模式的局限在于只能做追加操作. Redis目前缺少剪裁字符串的命令, 所以无法方便地把序列剪裁成指定的尺寸. 但是, 节拍序列在空间占用上效率极好.
小贴士: 在键值中组合Unix时间戳, 可以在构建一系列相关键值时缩短键值长度,更优雅地分配Redis实例.
使用定长字符串进行温度采样的例子(在实际使用时,采用二进制格式会更好).
redis> APPEND ts "0043"
(integer) 4
redis> APPEND ts "0035"
(integer) 8
redis> GETRANGE ts 0 3
"0043"
redis> GETRANGE ts 4 7
"0035"
redis>
STRLEN key
起始版本:2.2.0
时间复杂度:O(1)
返回key的string类型value的长度。如果key对应的非string类型,就返回错误。
返回值
integer-reply:key对应的字符串value的长度,或者0(key不存在)
例子
redis> SET mykey "Hello world"
OK
redis> STRLEN mykey
(integer) 11
redis> STRLEN nonexisting
(integer) 0
redis>
INCR key
起始版本:1.0.0
时间复杂度:O(1)
对存储在指定key的数值执行原子的加1操作。
如果指定的key不存在,那么在执行incr操作之前,会先将它的值设定为0。
如果指定的key中存储的值不是字符串类型(fix:)或者存储的字符串类型不能表示为一个整数,
那么执行这个命令时服务器会返回一个错误(eq:(error) ERR value is not an integer or out of range)。
这个操作仅限于64位的有符号整型数据。
注意: 由于redis并没有一个明确的类型来表示整型数据,所以这个操作是一个字符串操作。
执行这个操作的时候,key对应存储的字符串被解析为10进制的64位有符号整型数据。
事实上,Redis 内部采用整数形式(Integer representation)来存储对应的整数值,所以对该类字符串值实际上是用整数保存,也就不存在存储整数的字符串表示(String representation)所带来的额外消耗。
返回值
integer-reply:执行递增操作后key对应的值。
例子
redis> SET mykey "10"
OK
redis> INCR mykey
(integer) 11
redis> GET mykey
"11"
redis>
实例:计数器
Redis的原子递增操作最常用的使用场景是计数器。
使用思路是:每次有相关操作的时候,就向Redis服务器发送一个incr命令。
例如这样一个场景:我们有一个web应用,我们想记录每个用户每天访问这个网站的次数。
web应用只需要通过拼接用户id和代表当前时间的字符串作为key,每次用户访问这个页面的时候对这个key执行一下incr命令。
这个场景可以有很多种扩展方法:
- 通过结合使用
INCR和EXPIRE命令,可以实现一个只记录用户在指定间隔时间内的访问次数的计数器 - 客户端可以通过GETSET命令获取当前计数器的值并且重置为0
- 通过类似于DECR或者INCRBY等原子递增/递减的命令,可以根据用户的操作来增加或者减少某些值 比如在线游戏,需要对用户的游戏分数进行实时控制,分数可能增加也可能减少。
实例: 限速器
限速器是一种可以限制某些操作执行速率的特殊场景。
传统的例子就是限制某个公共api的请求数目。
假设我们要解决如下问题:限制某个api每秒每个ip的请求次数不超过10次。
我们可以通过incr命令来实现两种方法解决这个问题。
实例: 限速器 1
更加简单和直接的实现如下:
FUNCTION LIMIT_API_CALL(ip)
ts = CURRENT_UNIX_TIME()
keyname = ip+":"+ts
current = GET(keyname)
IF current != NULL AND current > 10 THEN
ERROR "too many requests per second"
ELSE
MULTI
INCR(keyname,1)
EXPIRE(keyname,10)
EXEC
PERFORM_API_CALL()
END
这种方法的基本点是每个ip每秒生成一个可以记录请求数的计数器。
但是这些计数器每次递增的时候都设置了10秒的过期时间,这样在进入下一秒之后,redis会自动删除前一秒的计数器。
注意上面伪代码中我们用到了MULTI和EXEC命令,将递增操作和设置过期时间的操作放在了一个事务中, 从而保证了两个操作的原子性。
实例: 限速器 2
另外一个实现是对每个ip只用一个单独的计数器(不是每秒生成一个),但是需要注意避免竟态条件。 我们会对多种不同的变量进行测试。
FUNCTION LIMIT_API_CALL(ip):
current = GET(ip)
IF current != NULL AND current > 10 THEN
ERROR "too many requests per second"
ELSE
value = INCR(ip)
IF value == 1 THEN
EXPIRE(value,1)
END
PERFORM_API_CALL()
END
上述方法的思路是,从第一个请求开始设置过期时间为1秒。如果1秒内请求数超过了10个,那么会抛异常。
否则,计数器会清零。
上述代码中,可能会进入竞态条件,比如客户端在执行INCR之后,没有成功设置EXPIRE时间。这个ip的key 会造成内存泄漏,直到下次有同一个ip发送相同的请求过来。
把上述INCR和EXPIRE命令写在lua脚本并执行EVAL命令可以避免上述问题(只有redis版本>=2.6才可以使用)
local current
current = redis.call("incr",KEYS[1])
if tonumber(current) == 1 then
redis.call("expire",KEYS[1],1)
end
还可以通过使用redis的list来解决上述问题避免进入竞态条件。
实现代码更加复杂并且利用了一些redis的新的feature,可以记录当前请求的客户端ip地址。这个有没有好处 取决于应用程序本身。
FUNCTION LIMIT_API_CALL(ip)
current = LLEN(ip)
IF current > 10 THEN
ERROR "too many requests per second"
ELSE
IF EXISTS(ip) == FALSE
MULTI
RPUSH(ip,ip)
EXPIRE(ip,1)
EXEC
ELSE
RPUSHX(ip,ip)
END
PERFORM_API_CALL()
END
The RPUSHX command only pushes the element if the key already exists.
RPUSHX命令会往list中插入一个元素,如果key存在的话
上述实现也可能会出现竞态,比如我们在执行EXISTS指令之后返回了false,但是另外一个客户端创建了这个key。
后果就是我们会少记录一个请求。但是这种情况很少出现,所以我们的请求限速器还是能够运行良好的。
DECR key
起始版本:1.0.0
时间复杂度:O(1)
对key对应的数字做减1操作。如果key不存在,那么在操作之前,这个key对应的值会被置为0。如果key有一个错误类型的value或者是一个不能表示成数字的字符串,就返回错误。这个操作最大支持在64位有符号的整型数字。
查看命令INCR了解关于增减操作的额外信息。
返回值
数字:减小之后的value
例子
redis> SET mykey "10"
OK
redis> DECR mykey
(integer) 9
redis> SET mykey "234293482390480948029348230948"
OK
redis> DECR mykey
ERR value is not an integer or out of range
redis>
INCRBY key increment
起始版本:1.0.0
时间复杂度:O(1)
将key对应的数字加decrement。如果key不存在,操作之前,key就会被置为0。如果key的value类型错误或者是个不能表示成数字的字符串,就返回错误。这个操作最多支持64位有符号的正型数字。
查看命令INCR了解关于增减操作的额外信息。
返回值
integer-reply: 增加之后的value值。
例子
redis> SET mykey "10"
OK
redis> INCRBY mykey 5
(integer) 15
redis>
DECRBY key decrement
起始版本:1.0.0
时间复杂度:O(1)
将key对应的数字减decrement。如果key不存在,操作之前,key就会被置为0。如果key的value类型错误或者是个不能表示成数字的字符串,就返回错误。这个操作最多支持64位有符号的正型数字。
查看命令INCR了解关于增减操作的额外信息。似。
返回值
返回一个数字:减少之后的value值。
例子
redis> SET mykey "10"
OK
redis> DECRBY mykey 5
(integer) 5
redis>
GETRANGE key start end
起始版本:2.4.0
时间复杂度:O(N) N是字符串长度,复杂度由最终返回长度决定,但由于通过一个字符串创建子字符串是很容易的,它可以被认为是O(1)。
警告:这个命令是被改成GETRANGE的,在小于2.0的Redis版本中叫SUBSTR。 返回key对应的字符串value的子串,这个子串是由start和end位移决定的(两者都在string内)。可以用负的位移来表示从string尾部开始数的下标。所以-1就是最后一个字符,-2就是倒数第二个,以此类推。
这个函数处理超出范围的请求时,都把结果限制在string内。
返回值
例子
redis> SET mykey "This is a string"
OK
redis> GETRANGE mykey 0 3
"This"
redis> GETRANGE mykey -3 -1
"ing"
redis> GETRANGE mykey 0 -1
"This is a string"
redis> GETRANGE mykey 10 100
"string"
redis>
SETRANGE key offset value
起始版本:2.2.0
时间复杂度:O(1),不计算将新字符串复制到位所需的时间。通常,该字符串非常小,因此时间复杂度为O(1),否则,时间复杂度为O(M),M是开始值参数的长度
这个命令的作用是覆盖key对应的string的一部分,从指定的offset处开始,覆盖value的长度。如果offset比当前key对应string还要长,那这个string后面就补0以达到offset。不存在的keys被认为是空字符串,所以这个命令可以确保key有一个足够大的字符串,能在offset处设置value。
注意,offset最大可以是229-1(536870911),因为redis字符串限制在512M大小。如果你需要超过这个大小,你可以用多个keys。
警告:当set最后一个字节并且key还没有一个字符串value或者其value是个比较小的字符串时,Redis需要立即分配所有内存,这有可能会导致服务阻塞一会。在一台2010MacBook Pro上,set536870911字节(分配512MB)需要~300ms,set134217728字节(分配128MB)需要~80ms,set33554432比特位(分配32MB)需要~30ms,set8388608比特(分配8MB)需要8ms。注意,一旦第一次内存分配完,后面对同一个key调用SETRANGE就不会预先得到内存分配。
模式
正因为有了SETRANGE和类似功能的GETRANGE命令,你可以把Redis的字符串当成线性数组,随机访问只要O(1)复杂度。这在很多真实场景应用里非常快和高效。
返回值
integer-reply:该命令修改后的字符串长度
例子
基本使用方法:
redis> SET key1 "Hello World"
OK
redis> SETRANGE key1 6 "Redis"
(integer) 11
redis> GET key1
"Hello Redis"
redis>
补充的例子:
redis> SETRANGE key2 6 "Redis"
(integer) 11
redis> GET key2
"\x00\x00\x00\x00\x00\x00Redis"
redis>
MSET key value [key value …]
起始版本:1.0.1
时间复杂度:O(N),其中N是要设置的key的数量。
对应给定的keys到他们相应的values上。MSET会用新的value替换已经存在的value,就像普通的SET命令一样。如果你不想覆盖已经存在的values,请参看命令MSETNX。
MSET是原子的,所以所有给定的keys是一次性set的。客户端不可能看到这种一部分keys被更新而另外的没有改变的情况。
返回值
simple-string-reply:总是OK,因为MSET不会失败。
例子
redis> MSET key1 "Hello" key2 "World"
OK
redis> GET key1
"Hello"
redis> GET key2
"World"
redis>
MGET key [key …]
起始版本:1.0.0
时间复杂度:O(N),其中N是要检索的key数量。
返回所有指定的key的value。对于每个不对应string或者不存在的key,都返回特殊值nil。正因为此,这个操作从来不会失败。
返回值
array-reply: 指定的key对应的values的list
例子
redis> SET key1 "Hello"
OK
redis> SET key2 "World"
OK
redis> MGET key1 key2 nonexisting
1) "Hello"
2) "World"
3) (nil)
redis>
MSETNX key value [key value …]
起始版本:1.0.1
时间复杂度:O(N),其中N是要设置的key的数量。
对应给定的keys到他们相应的values上。只要有一个key已经存在,MSETNX一个操作都不会执行。 由于这种特性,MSETNX可以实现要么所有的操作都成功,要么一个都不执行,这样可以用来设置不同的key,来表示一个唯一的对象的不同字段。
MSETNX是原子的,所以所有给定的keys是一次性set的。客户端不可能看到这种一部分keys被更新而另外的没有改变的情况。
返回值
integer-reply,只有以下两种值:
- 1 如果所有的key被set
- 0 如果没有key被set(至少其中有一个key是存在的)
例子
redis> MSETNX key1 "Hello" key2 "there"
(integer) 1
redis> MSETNX key2 "there" key3 "world"
(integer) 0
redis> MGET key1 key2 key3
1) "Hello"
2) "there"
3) (nil)
redis>
SELECT index
起始版本:1.0.0
选择一个数据库,下标值从0开始,一个新连接默认连接的数据库是DB0。
返回值
FLUSHDB
起始版本:1.0.0
删除当前数据库里面的所有数据。
这个命令永远不会出现失败。
这个操作的时间复杂度是O(N),N是当前数据库的keys数量。
返回
FLUSHALL
起始版本:1.0.0
删除所有数据库里面的所有数据,注意不是当前数据库,而是所有数据库。
这个命令永远不会出现失败。
这个操作的时间复杂度是O(N),N是数据库的数量。
返回
hash类型
HSET key field value
起始版本:2.0.0
时间复杂度:O(1)
设置 key 指定的哈希集中指定字段的值。
如果 key 指定的哈希集不存在,会创建一个新的哈希集并与 key 关联。
如果字段在哈希集中存在,它将被重写。
返回值
integer-reply:含义如下
- 1如果field是一个新的字段
- 0如果field原来在map里面已经存在
例子
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HGET myhash field1
"Hello"
redis>
HGET key field
起始版本:2.0.0
时间复杂度**:**O(1)
返回 key 指定的哈希集中该字段所关联的值
返回值
bulk-string-reply:该字段所关联的值。当字段不存在或者 key 不存在时返回nil。
例子
redis> HSET myhash field1 "foo"
(integer) 1
redis> HGET myhash field1
"foo"
redis> HGET myhash field2
(nil)
redis>
HMSET key field value [field value …]
起始版本:2.0.0
时间复杂度:O(N),这里的N是需要设置的字段数
设置 key 指定的哈希集中指定字段的值。该命令将重写所有在哈希集中存在的字段。如果 key 指定的哈希集不存在,会创建一个新的哈希集并与 key 关联
返回值
例子
redis> HMSET myhash field1 "Hello" field2 "World"
OK
redis> HGET myhash field1
"Hello"
redis> HGET myhash field2
"World"
redis>
HMGET key field [field …]
起始版本:2.0.0
时间复杂度:O(N),这里的N是需要设置的字段数
返回 key 指定的哈希集中指定字段的值。
对于哈希集中不存在的每个字段,返回 nil 值。因为不存在的keys被认为是一个空的哈希集,对一个不存在的 key 执行 HMGET 将返回一个只含有 nil 值的列表
返回值
array-reply:含有给定字段及其值的列表,并保持与请求相同的顺序。
例子
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HMGET myhash field1 field2 nofield
1) "Hello"
2) "World"
3) (nil)
redis>
HGETALL key
起始版本:2.0.0
时间复杂度**:**O(N),这里的N是这个hash的size
返回 key 指定的哈希集中所有的字段和值。返回值中,每个字段名的下一个是它的值,所以返回值的长度是哈希集大小的两倍
返回值
array-reply:哈希集中字段和值的列表。当 key 指定的哈希集不存在时返回空列表。
例子
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
redis>
HLEN key
起始版本:2.0.0
时间复杂度:O(1)
返回 key 指定的哈希集包含的字段的数量。
返回值
integer-reply: 哈希集中字段的数量,当 key 指定的哈希集不存在时返回 0
例子
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HLEN myhash
(integer) 2
redis>
HKEYS key
起始版本:2.0.0
时间复杂度:O(N),这里的N是此hash的size
返回 key 指定的哈希集中所有字段的名字。
返回值
array-reply:哈希集中的字段列表,当 key 指定的哈希集不存在时返回空列表。
例子
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HKEYS myhash
1) "field1"
2) "field2"
redis>
HVALS key
起始版本:2.0.0
时间复杂度:O(N),这里的N是此hash的size
返回 key 指定的哈希集中所有字段的值。
返回值
array-reply:哈希集中的值的列表,当 key 指定的哈希集不存在时返回空列表。
例子
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HVALS myhash
1) "Hello"
2) "World"
redis>
HINCRBY key field increment
起始版本:2.0.0
时间复杂度:O(1)
增加 key 指定的哈希集中指定字段的数值。如果 key 不存在,会创建一个新的哈希集并与 key 关联。如果字段不存在,则字段的值在该操作执行前被设置为 0
HINCRBY 支持的值的范围限定在 64位 有符号整数
返回值
integer-reply:增值操作执行后的该字段的值。
例子
redis> HSET myhash field 5
(integer) 1
redis> HINCRBY myhash field 1
(integer) 6
redis> HINCRBY myhash field -1
(integer) 5
redis> HINCRBY myhash field -10
(integer) -5
redis>
HINCRBYFLOAT key field increment
起始版本:2.6.0
时间复杂度:O(1)
为指定key的hash的field字段值执行float类型的increment加。如果field不存在,则在执行该操作前设置为0.如果出现下列情况之一,则返回错误:
field的值包含的类型错误(不是字符串)。- 当前
field或者increment不能解析为一个float类型。
此命令的确切行为与INCRBYFLOAT命令相同,请参阅INCRBYFLOAT命令获取更多信息。
返回值
bulk-string-reply: field执行increment加后的值
例子
redis> HSET mykey field 10.50
(integer) 1
redis> HINCRBYFLOAT mykey field 0.1
"10.6"
redis> HSET mykey field 5.0e3
(integer) 0
redis> HINCRBYFLOAT mykey field 2.0e2
"5200"
redis>
实现细节
该命令始终是在复制和模仿HSET,因此,在底层的浮点数运算不会出现数据不一致性问题。
HEXISTS key field
起始版本:2.0.0
时间复杂度:O(1)
返回hash里面field是否存在
返回值
integer-reply, 含义如下:
- 1 hash里面包含该field。
- 0 hash里面不包含该field或者key不存在。
例子
redis> HSET myhash field1 "foo"
(integer) 1
redis> HEXISTS myhash field1
(integer) 1
redis> HEXISTS myhash field2
(integer) 0
redis>
HDEL key field [field …]
起始版本:2.0.0
时间复杂度:O(N) N是被删除的字段数量。
从 key 指定的哈希集中移除指定的域。在哈希集中不存在的域将被忽略。
如果 key 指定的哈希集不存在,它将被认为是一个空的哈希集,该命令将返回0。
返回值
integer-reply: 返回从哈希集中成功移除的域的数量,不包括指出但不存在的那些域
历史
例子
redis> HSET myhash field1 "foo"
(integer) 1
redis> HDEL myhash field1
(integer) 1
redis> HDEL myhash field2
(integer) 0
redis>
list类型
LPUSH key value [value …]
起始版本:1.0.0
时间复杂度:O(1)
将所有指定的值插入到存于 key 的列表的头部。如果 key 不存在,那么在进行 push 操作前会创建一个空列表。 如果 key 对应的值不是一个 list 的话,那么会返回一个错误。
可以使用一个命令把多个元素 push 进入列表,只需在命令末尾加上多个指定的参数。元素是从最左端的到最右端的、一个接一个被插入到 list 的头部。 所以对于这个命令例子 LPUSH mylist a b c,返回的列表是 c 为第一个元素, b 为第二个元素, a 为第三个元素。
返回值
integer-reply: 在 push 操作后的 list 长度。
历史
- 2.4: 接受多个 value 参数。版本老于 2.4 的 Redis 只能每条命令 push 一个值。
例子
redis> LPUSH mylist "world"
(integer) 1
redis> LPUSH mylist "hello"
(integer) 2
redis> LRANGE mylist 0 -1
1) "hello"
2) "world"
redis>
LRANGE key start stop
起始版本:1.0.0
时间复杂度:O(S+N),其中S是小列表的起始偏移距头部的距离,大列表的起始偏移距最近端(头部或尾部)的距离;N是指定范围内的元素数。
返回存储在 key 的列表里指定范围内的元素。 start 和 end 偏移量都是基于0的下标,即list的第一个元素下标是0(list的表头),第二个元素下标是1,以此类推。
偏移量也可以是负数,表示偏移量是从list尾部开始计数。 例如, -1 表示列表的最后一个元素,-2 是倒数第二个,以此类推。
在不同编程语言里,关于求范围函数的一致性
需要注意的是,如果你有一个list,里面的元素是从0到100,那么 LRANGE list 0 10 这个命令会返回11个元素,即最右边的那个元素也会被包含在内。 在你所使用的编程语言里,这一点可能是也可能不是跟那些求范围有关的函数都是一致的。(像Ruby的 Range.new,Array#slice 或者Python的 range() 函数。)
超过范围的下标
当下标超过list范围的时候不会产生error。 如果start比list的尾部下标大的时候,会返回一个空列表。 如果stop比list的实际尾部大的时候,Redis会当它是最后一个元素的下标。
返回值
array-reply: 指定范围里的列表元素。
例子
redis> RPUSH mylist "one"
(integer) 1
redis> RPUSH mylist "two"
(integer) 2
redis> RPUSH mylist "three"
(integer) 3
redis> LRANGE mylist 0 0
1) "one"
redis> LRANGE mylist -3 2
1) "one"
2) "two"
3) "three"
redis> LRANGE mylist -100 100
1) "one"
2) "two"
3) "three"
redis> LRANGE mylist 5 10
(empty list or set)
redis>
RPUSH key value [value …]
起始版本:1.0.0
时间复杂度:O(1)
向存于 key 的列表的尾部插入所有指定的值。如果 key 不存在,那么会创建一个空的列表然后再进行 push 操作。 当 key 保存的不是一个列表,那么会返回一个错误。
可以使用一个命令把多个元素打入队列,只需要在命令后面指定多个参数。元素是从左到右一个接一个从列表尾部插入。 比如命令 RPUSH mylist a b c 会返回一个列表,其第一个元素是 a ,第二个元素是 b ,第三个元素是 c。
返回值
integer-reply: 在 push 操作后的列表长度。
历史
- 2.4: 接受多个 value 参数。 在老于 2.4 的 Redis 版本中,一条命令只能 push 单一个值。
例子
redis> RPUSH mylist "hello"
(integer) 1
redis> RPUSH mylist "world"
(integer) 2
redis> LRANGE mylist 0 -1
1) "hello"
2) "world"
redis>
LPOP key
起始版本:1.0.0
时间复杂度:O(1)
移除并且返回 key 对应的 list 的第一个元素。
返回值
bulk-string-reply: 返回第一个元素的值,或者当 key 不存在时返回 nil。
例子
redis> RPUSH mylist "one"
(integer) 1
redis> RPUSH mylist "two"
(integer) 2
redis> RPUSH mylist "three"
(integer) 3
redis> LPOP mylist
"one"
redis> LRANGE mylist 0 -1
1) "two"
2) "three"
redis>
RPOP key
起始版本:1.0.0
时间复杂度:O(1)
移除并返回存于 key 的 list 的最后一个元素。
返回值
bulk-string-reply: 最后一个元素的值,或者当 key 不存在的时候返回 nil。
例子
redis> RPUSH mylist "one"
(integer) 1
redis> RPUSH mylist "two"
(integer) 2
redis> RPUSH mylist "three"
(integer) 3
redis> RPOP mylist
"three"
redis> LRANGE mylist 0 -1
1) "one"
2) "two"
redis>
LLEN key
起始版本:1.0.0
时间复杂度:O(1)
返回存储在 key 里的list的长度。 如果 key 不存在,那么就被看作是空list,并且返回长度为 0。 当存储在 key 里的值不是一个list的话,会返回error。
返回值
integer-reply: key对应的list的长度。
例子
redis> LPUSH mylist "World"
(integer) 1
redis> LPUSH mylist "Hello"
(integer) 2
redis> LLEN mylist
(integer) 2
redis>
LINDEX key index
起始版本:1.0.0
时间复杂度:O(N),其中N是要遍历的元素数,以到达索引处的元素。这使得请求列表的第一个或最后一个元素成为O(1)。
返回列表里的元素的索引 index 存储在 key 里面。 下标是从0开始索引的,所以 0 是表示第一个元素, 1 表示第二个元素,并以此类推。 负数索引用于指定从列表尾部开始索引的元素。在这种方法下,-1 表示最后一个元素,-2 表示倒数第二个元素,并以此往前推。
当 key 位置的值不是一个列表的时候,会返回一个error。
返回值
bulk-reply:请求的对应元素,或者当 index 超过范围的时候返回 nil。
例子
redis> LPUSH mylist "World"
(integer) 1
redis> LPUSH mylist "Hello"
(integer) 2
redis> LINDEX mylist 0
"Hello"
redis> LINDEX mylist -1
"World"
redis> LINDEX mylist 3
(nil)
redis>
LSET key index value
起始版本:1.0.0
**时间复杂度:**O(N),其中N是列表的长度。将列表的第一个或最后一个元素设置为O(1)。
设置 index 位置的list元素的值为 value。 更多关于 index 参数的信息,详见 LINDEX。
当index超出范围时会返回一个error。
返回值
例子
redis> RPUSH mylist "one"
(integer) 1
redis> RPUSH mylist "two"
(integer) 2
redis> RPUSH mylist "three"
(integer) 3
redis> LSET mylist 0 "four"
OK
redis> LSET mylist -2 "five"
OK
redis> LRANGE mylist 0 -1
1) "four"
2) "five"
3) "three"
redis>
LINSERT key BEFORE|AFTER pivot value
起始版本:2.2.0
时间复杂度:O(N),其中N是在看到值轴之前要遍历的元素数。这意味着在列表的左端(头部)的某个地方插入可以被认为是O(1),而在右端(尾部)的某个地方插入可以被认为是O(N)。
把 value 插入存于 key 的列表中在基准值 pivot 的前面或后面。
当 key 不存在时,这个list会被看作是空list,任何操作都不会发生。
当 key 存在,但保存的不是一个list的时候,会返回error。
返回值
integer-reply: 经过插入操作后的list长度,或者当 pivot 值找不到的时候返回 -1。
例子
redis> RPUSH mylist "Hello"
(integer) 1
redis> RPUSH mylist "World"
(integer) 2
redis> LINSERT mylist BEFORE "World" "There"
(integer) 3
redis> LRANGE mylist 0 -1
1) "Hello"
2) "There"
3) "World"
redis>
LREM key count value
起始版本:1.0.0
时间复杂度:O(N),N是list的长度
从存于 key 的列表里移除前 count 次出现的值为 value 的元素。 这个 count 参数通过下面几种方式影响这个操作:
- count > 0: 从头往尾移除值为 value 的元素。
- count < 0: 从尾往头移除值为 value 的元素。
- count = 0: 移除所有值为 value 的元素。
比如, LREM list -2 “hello” 会从存于 list 的列表里移除最后两个出现的 “hello”。
需要注意的是,如果list里没有存在key就会被当作空list处理,所以当 key 不存在的时候,这个命令会返回 0。
返回值
integer-reply: 被移除的元素个数。
例子
redis> RPUSH mylist "hello"
(integer) 1
redis> RPUSH mylist "hello"
(integer) 2
redis> RPUSH mylist "foo"
(integer) 3
redis> RPUSH mylist "hello"
(integer) 4
redis> LREM mylist -2 "hello"
(integer) 2
redis> LRANGE mylist 0 -1
1) "hello"
2) "foo"
redis>
LTRIM key start stop
起始版本:1.0.0
时间复杂度:O(N),其中N是操作要移除的元素数。
修剪(trim)一个已存在的 list,这样 list 就会只包含指定范围的指定元素。start 和 stop 都是由0开始计数的, 这里的 0 是列表里的第一个元素(表头),1 是第二个元素,以此类推。
例如: LTRIM foobar 0 2 将会对存储在 foobar 的列表进行修剪,只保留列表里的前3个元素。
start 和 end 也可以用负数来表示与表尾的偏移量,比如 -1 表示列表里的最后一个元素, -2 表示倒数第二个,等等。
超过范围的下标并不会产生错误:如果 start 超过列表尾部,或者 start > end,结果会是列表变成空表(即该 key 会被移除)。 如果 end 超过列表尾部,Redis 会将其当作列表的最后一个元素。
LTRIM 的一个常见用法是和 LPUSH / RPUSH 一起使用。 例如:
- LPUSH mylist someelement
- LTRIM mylist 0 99
这一对命令会将一个新的元素 push 进列表里,并保证该列表不会增长到超过100个元素。这个是很有用的,比如当用 Redis 来存储日志。 需要特别注意的是,当用这种方式来使用 LTRIM 的时候,操作的复杂度是 O(1) , 因为平均情况下,每次只有一个元素会被移除。
返回值
例子
redis> RPUSH mylist "one"
(integer) 1
redis> RPUSH mylist "two"
(integer) 2
redis> RPUSH mylist "three"
(integer) 3
redis> LTRIM mylist 1 -1
OK
redis> LRANGE mylist 0 -1
1) "two"
2) "three"
redis>
set类型
SADD key member [member …]
起始版本:1.0.0
时间复杂度:O(N),其中N是要添加的成员数。
添加一个或多个指定的member元素到集合的 key中.指定的一个或者多个元素member 如果已经在集合key中存在则忽略.如果集合key 不存在,则新建集合key,并添加member元素到集合key中.
如果key 的类型不是集合则返回错误.
返回值
integer-reply:返回新成功添加到集合里元素的数量,不包括已经存在于集合中的元素.
历史
- 2.4: 接受多个member 参数. Redis 2.4 以前的版本每次只能添加一个member元素.
例子
redis> SADD myset "Hello"
(integer) 1
redis> SADD myset "World"
(integer) 1
redis> SADD myset "World"
(integer) 0
redis> SMEMBERS myset
1) "World"
2) "Hello"
redis>
SMEMBERS key
起始版本:1.0.0
时间复杂度:O(N),其中N是集合基数。
返回key集合所有的元素.
该命令的作用与使用一个参数的SINTER 命令作用相同.
返回值
array-reply:集合中的所有元素.
举例
redis> SADD myset "Hello"
(integer) 1
redis> SADD myset "World"
(integer) 1
redis> SMEMBERS myset
1) "World"
2) "Hello"
redis>
SCARD key
起始版本:1.0.0
时间复杂度:O(1)
返回集合存储的key的基数 (集合元素的数量).
返回值
integer-reply: 集合的基数(元素的数量),如果key不存在,则返回 0.
举例
redis> SADD myset "Hello"
(integer) 1
redis> SADD myset "World"
(integer) 1
redis> SCARD myset
(integer) 2
redis>
SISMEMBER key member
起始版本:1.0.0
时间复杂度:O(1)
返回成员 member 是否是存储的集合 key的成员.
返回值
integer-reply,详细说明:
- 如果member元素是集合key的成员,则返回1
- 如果member元素不是key的成员,或者集合key不存在,则返回0
举例
redis> SADD myset "one"
(integer) 1
redis> SISMEMBER myset "one"
(integer) 1
redis> SISMEMBER myset "two"
(integer) 0
redis>
SREM key member [member …]
起始版本:1.0.0
时间复杂度:O(N),N是需要移除的元素数量
在key集合中移除指定的元素. 如果指定的元素不是key集合中的元素则忽略 如果key集合不存在则被视为一个空的集合,该命令返回0.
如果key的类型不是一个集合,则返回错误.
返回值
integer-reply:从集合中移除元素的个数,不包括不存在的成员.
历史
- 2.4: 接受多个 member 元素参数. Redis 2.4 之前的版本每次只能移除一个元素.
举例
redis> SADD myset "one"
(integer) 1
redis> SADD myset "two"
(integer) 1
redis> SADD myset "three"
(integer) 1
redis> SREM myset "one"
(integer) 1
redis> SREM myset "four"
(integer) 0
redis> SMEMBERS myset
1) "three"
2) "two"
redis>
SPOP key [count]
起始版本:1.0.0
时间复杂度:O(1)
从存储在key的集合中移除并返回一个或多个随机元素。
此操作与SRANDMEMBER类似,它从一个集合中返回一个或多个随机元素,但不删除元素。
count参数将在更高版本中提供,但是在2.6、2.8、3.0中不可用。
返回值
bulk-string-reply:被删除的元素,或者当key不存在时返回nil。
例子
redis> SMEMBERS db
1) "MySQL"
2) "MongoDB"
3) "Redis"
redis> SPOP db
"Redis"
redis> SMEMBERS db
1) "MySQL"
2) "MongoDB"
redis> SPOP db
"MySQL"
redis> SMEMBERS db
1) "MongoDB"
传递count时的行为规范
如果count大于集合内部的元素数量,此命令将会返回整个集合,不会有额外的元素。
返回元素的分布
请注意,当你需要保证均匀分布返回的元素时,此命令不适用。更多有关SPOP使用的算法的信息,请查阅Knuth采样和Floyd采样算法。
count参数扩展
Redis 3.2是第一个可以给SPOP传递可选参数count的版本,以便在一次调用中取回多个元素。此实现已经在unstable分支中可用。
SRANDMEMBER key [count]
起始版本:1.0.0
时间复杂度:不带count参数O(1),否则为O(N),其中N是传递的计数的绝对值。
仅提供key参数,那么随机返回key集合中的一个元素.
Redis 2.6开始,可以接受 count 参数,如果count是整数且小于元素的个数,返回含有 count 个不同的元素的数组,如果count是个整数且大于集合中元素的个数时,仅返回整个集合的所有元素,当count是负数,则会返回一个包含count的绝对值的个数元素的数组,如果count的绝对值大于元素的个数,则返回的结果集里会出现一个元素出现多次的情况.
仅提供key参数时,该命令作用类似于SPOP命令,不同的是SPOP命令会将被选择的随机元素从集合中移除,而SRANDMEMBER仅仅是返回该随记元素,而不做任何操作.
返回值
bulk-string-reply: 不使用count 参数的情况下该命令返回随机的元素,如果key不存在则返回nil。
array-reply: 使用count参数,则返回一个随机的元素数组,如果key不存在则返回一个空的数组。
举例
redis> SADD myset one two three
(integer) 3
redis> SRANDMEMBER myset
"one"
redis> SRANDMEMBER myset 2
1) "three"
2) "one"
redis> SRANDMEMBER myset -5
1) "one"
2) "one"
3) "one"
4) "one"
5) "one"
redis>
传递count参数时的行为规范
当传递了一个值为正数的count参数,返回的元素就好像从集合中移除了每个选中的元素一样(就像在宾果游戏中提取数字一样)。但是元素不会从集合中移除。所以基本上:
- 不会返回重复的元素。
- 如果count参数的值大于集合内的元素数量,此命令将会仅返回整个集合,没有额外的元素。
相反,当count参数的值为负数时,此命令的行为将发生改变,并且提取操作就像在每次提取后,重新将取出的元素放回包里一样,因此,可能返回重复的元素,以及总是会返回我们请求的数量的元素,因为我们可以一次又一次地重复相同的元素,除了当集合为空(或者不存在key)的时候,将总是会返回一个空数组。
返回元素的分布
当集合中的元素数量很少时,返回元素分布远不够完美,这是因为我们使用了一个近似随机元素函数,它并不能保证良好的分布。
所使用的算法(在dict.c中实现)对哈希表桶进行采样以找到非空桶。一旦找到非空桶,由于我们在哈希表的实现中使用了链接法,因此会检查桶中的元素数量,并且选出一个随机元素。
这意味着,如果你在整个哈希表中有两个非空桶,其中一个有三个元素,另一个只有一个元素,那么其桶中单独存在的元素将以更高的概率返回。
SMOVE source destination member
起始版本:1.0.0
时间复杂度:O(1)
将member从source集合移动到destination集合中. 对于其他的客户端,在特定的时间元素将会作为source或者destination集合的成员出现.
如果source 集合不存在或者不包含指定的元素,这smove命令不执行任何操作并且返回0.否则对象将会从source集合中移除,并添加到destination集合中去,如果destination集合已经存在该元素,则smove命令仅将该元素充source集合中移除. 如果source 和destination不是集合类型,则返回错误.
返回值
- 如果该元素成功移除,返回1
- 如果该元素不是 source集合成员,无任何操作,则返回0.
举例
redis> SADD myset "one"
(integer) 1
redis> SADD myset "two"
(integer) 1
redis> SADD myotherset "three"
(integer) 1
redis> SMOVE myset myotherset "two"
(integer) 1
redis> SMEMBERS myset
1) "one"
redis> SMEMBERS myotherset
1) "three"
2) "two"
redis>
SDIFF key [key …]
起始版本:1.0.0
时间复杂度:O(N),其中N是所有给定集合中的元素总数。
返回一个集合与给定集合的差集的元素.
举例:
key1 = {a,b,c,d}
key2 = {c}
key3 = {a,c,e}
SDIFF key1 key2 key3 = {b,d}
不存在的key认为是空集.
返回值
array-reply:结果集的元素.
举例
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SDIFF key1 key2
1) "a"
2) "b"
redis>
SINTER key [key …]
起始版本:1.0.0
时间复杂度:O(N*M),最坏情况,其中N是最小集合的基数,M是集合数。
返回指定所有的集合的成员的交集.
例如:
key1 = {a,b,c,d}
key2 = {c}
key3 = {a,c,e}
SINTER key1 key2 key3 = {c}
如果key不存在则被认为是一个空的集合,当给定的集合为空的时候,结果也为空.(一个集合为空,结果一直为空).
返回值
array-reply: 结果集成员的列表.
例子
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SINTER key1 key2
1) "c"
redis>
SUNION key [key …]
起始版本:1.0.0
时间复杂度:O(N),其中N是所有给定集合中的元素总数。
返回给定的多个集合的并集中的所有成员.
例如:
key1 = {a,b,c,d}
key2 = {c}
key3 = {a,c,e}
SUNION key1 key2 key3 = {a,b,c,d,e}
不存在的key可以认为是空的集合.
返回值
array-reply:并集的成员列表
举例
redis> SADD key1 "a"
(integer) 1
redis> SADD key1 "b"
(integer) 1
redis> SADD key1 "c"
(integer) 1
redis> SADD key2 "c"
(integer) 1
redis> SADD key2 "d"
(integer) 1
redis> SADD key2 "e"
(integer) 1
redis> SUNION key1 key2
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
redis>
zset类型
ZADD key [NX|XX] [CH] [INCR] score member [score member …]
起始版本:1.2.0
时间复杂度:O(log(N)),对于添加的每个元素,其中N是排序集中的元素数。
将所有指定成员添加到键为key有序集合(sorted set)里面。 添加时可以指定多个分数/成员(score/member)对。 如果指定添加的成员已经是有序集合里面的成员,则会更新改成员的分数(scrore)并更新到正确的排序位置。
如果key不存在,将会创建一个新的有序集合(sorted set)并将分数/成员(score/member)对添加到有序集合,就像原来存在一个空的有序集合一样。如果key存在,但是类型不是有序集合,将会返回一个错误应答。
分数值是一个双精度的浮点型数字字符串。+inf和-inf都是有效值。
ZADD 参数(options) (>= Redis 3.0.2)
ZADD 命令在key后面分数/成员(score/member)对前面支持一些参数,他们是:
- XX: 仅仅更新存在的成员,不添加新成员。
- NX: 不更新存在的成员。只添加新成员。
- CH: 修改返回值为发生变化的成员总数,原始是返回新添加成员的总数 (CH 是 changed 的意思)。更改的元素是新添加的成员,已经存在的成员更新分数。 所以在命令中指定的成员有相同的分数将不被计算在内。注:在通常情况下,
ZADD返回值只计算新添加成员的数量。 - INCR: 当
ZADD指定这个选项时,成员的操作就等同ZINCRBY命令,对成员的分数进行递增操作。
分数可以精确的表示的整数的范围
Redis 有序集合的分数使用双精度64位浮点数。我们支持所有的架构,这表示为一个IEEE 754 floating point number,它能包括的整数范围是-(2^53) 到 +(2^53)。或者说是-9007199254740992 到 9007199254740992。更大的整数在内部用指数形式表示,所以,如果为分数设置一个非常大的整数,你得到的是一个近似的十进制数。
Sorted sets 101
有序集合按照分数以递增的方式进行排序。相同的成员(member)只存在一次,有序集合不允许存在重复的成员。 分数可以通过ZADD命令进行更新或者也可以通过ZINCRBY命令递增来修改之前的值,相应的他们的排序位置也会随着分数变化而改变。
获取一个成员当前的分数可以使用ZSCORE命令,也可以用它来验证成员是否存在。
更多关于有序集合的信息请参考数据类型-有序集合。
相同分数的成员
有序集合里面的成员是不能重复的都是唯一的,但是,不同成员间有可能有相同的分数。当多个成员有相同的分数时,他们将是有序的字典(ordered lexicographically)(仍由分数作为第一排序条件,然后,相同分数的成员按照字典规则相对排序)。
字典顺序排序用的是二进制,它比较的是字符串的字节数组。
如果用户将所有元素设置相同分数(例如0),有序集合里面的所有元素将按照字典顺序进行排序,范围查询元素可以使用ZRANGEBYLEX命令(注:范围查询分数可以使用ZRANGEBYSCORE命令)。
返回值
Integer reply, 包括:
- 添加到有序集合的成员数量,不包括已经存在更新分数的成员。
如果指定INCR参数, 返回将会变成bulk-string-reply :
- 成员的新分数(双精度的浮点型数字)字符串。
历史
>= 2.4: 接受多个成员。 在Redis 2.4以前,命令只能添加或者更新一个成员。
例子
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 1 "uno"
(integer) 1
redis> ZADD myzset 2 "two" 3 "three"
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "uno"
4) "1"
5) "two"
6) "2"
7) "three"
8) "3"
redis>
ZRANGE key start stop [WITHSCORES]
起始版本:1.2.0
时间复杂度:O(log(N)+M),N是排序集中的元素数,M是返回的元素数。
返回存储在有序集合key中的指定范围的元素。 返回的元素可以认为是按得分从最低到最高排列。 如果得分相同,将按字典排序。
当你需要元素从最高分到最低分排列时,请参阅ZREVRANGE(相同的得分将使用字典倒序排序)。
参数start和stop都是基于零的索引,即0是第一个元素,1是第二个元素,以此类推。 它们也可以是负数,表示从有序集合的末尾的偏移量,其中-1是有序集合的最后一个元素,-2是倒数第二个元素,等等。
start和stop都是全包含的区间,因此例如ZRANGE myzset 0 1将会返回有序集合的第一个和第二个元素。
超出范围的索引不会产生错误。 如果start参数的值大于有序集合中的最大索引,或者start > stop,将会返回一个空列表。 如果stop的值大于有序集合的末尾,Redis会将其视为有序集合的最后一个元素。
可以传递WITHSCORES选项,以便将元素的分数与元素一起返回。这样,返回的列表将包含value1,score1,...,valueN,scoreN,而不是value1,...,valueN。 客户端类库可以自由地返回更合适的数据类型(建议:具有值和得分的数组或记录)。
返回值
array-reply:给定范围内的元素列表(如果指定了WITHSCORES选项,将同时返回它们的得分)。
例子
redis > ZRANGE salary 0 -1 WITHSCORES # 显示整个有序集成员
1) "jack"
2) "3500"
3) "tom"
4) "5000"
5) "boss"
6) "10086"
redis > ZRANGE salary 1 2 WITHSCORES # 显示有序集下标区间 1 至 2 的成员
1) "tom"
2) "5000"
3) "boss"
4) "10086"
redis > ZRANGE salary 0 200000 WITHSCORES # 测试 end 下标超出最大下标时的情况
1) "jack"
2) "3500"
3) "tom"
4) "5000"
5) "boss"
6) "10086"
redis > ZRANGE salary 200000 3000000 WITHSCORES # 测试当给定区间不存在于有序集时的情况
(empty list or set)
可以通过使用 WITHSCORES 选项,来让成员和它的 score 值一并返回,返回列表以 value1,score1, ..., valueN,scoreN 的格式表示。 客户端库可能会返回一些更复杂的数据类型,比如数组、元组等。
ZRANK key member
起始版本:2.0.0
时间复杂度:O(log(N))
返回有序集key中成员member的排名。其中有序集成员按score值递增(从小到大)顺序排列。排名以0为底,也就是说,score值最小的成员排名为0。
使用ZREVRANK命令可以获得成员按score值递减(从大到小)排列的排名。
返回值
- 如果member是有序集key的成员,返回integer-reply:member的排名。
- 如果member不是有序集key的成员,返回bulk-string-reply:
nil。
例子
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANK myzset "three"
(integer) 2
redis> ZRANK myzset "four"
(nil)
redis>
ZSCORE key member
起始版本:1.2.0
时间复杂度:O(1)
返回有序集key中,成员member的score值。
如果member元素不是有序集key的成员,或key不存在,返回nil。
返回值
bulk-string-reply: member成员的score值(double型浮点数),以字符串形式表示。
例子
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZSCORE myzset "one"
"1"
redis>
ZCARD key
起始版本:1.2.0
时间复杂度:O(1)
返回key的有序集元素个数。
返回值
integer-reply: key存在的时候,返回有序集的元素个数,否则返回0。
例子
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZCARD myzset
(integer) 2
redis>
ZCOUNT key min max
起始版本:2.0.0
时间复杂度: O(log(N)),
N为有序集的基数。
返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量。
关于参数 min 和 max 的详细使用方法,请参考 [ZRANGEBYSCORE key min max WITHSCORES] [LIMIT offset count] 命令。
返回值
score 值在 min 和 max 之间的成员的数量。
代码示例
redis> ZRANGE salary 0 -1 WITHSCORES # 测试数据
1) "jack"
2) "2000"
3) "peter"
4) "3500"
5) "tom"
6) "5000"
redis> ZCOUNT salary 2000 5000 # 计算薪水在 2000-5000 之间的人数
(integer) 3
redis> ZCOUNT salary 3000 5000 # 计算薪水在 3000-5000 之间的人数
(integer) 2
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
起始版本:1.0.5
时间复杂度:O(log(N)+M),N是排序集中的元素数,M是返回的元素数。如果M是常数(例如总是要求前10个元素具有限制),你可以考虑它O(log(n))。
如果M是常量(比如,用limit总是请求前10个元素),你可以认为是O(log(N))。
返回key的有序集合中的分数在min和max之间的所有元素(包括分数等于max或者min的元素)。元素被认为是从低分到高分排序的。
具有相同分数的元素按字典序排列(这个根据redis对有序集合实现的情况而定,并不需要进一步计算)。
可选的LIMIT参数指定返回结果的数量及区间(类似SQL中SELECT LIMIT offset, count)。注意,如果offset太大,定位offset就可能遍历整个有序集合,这会增加O(N)的复杂度。
可选参数WITHSCORES会返回元素和其分数,而不只是元素。这个选项在redis2.0之后的版本都可用。
##区间及无限
min和max可以是-inf和+inf,这样一来,你就可以在不知道有序集的最低和最高score值的情况下,使用ZRANGEBYSCORE这类命令。
默认情况下,区间的取值使用闭区间(小于等于或大于等于),你也可以通过给参数前增加(符号来使用可选的开区间(小于或大于)。
举个例子:
ZRANGEBYSCORE zset (1 5
返回所有符合条件1 < score <= 5的成员;
ZRANGEBYSCORE zset (5 (10
返回所有符合条件5 < score < 10 的成员。
返回值
array-reply: 指定分数范围的元素列表(也可以返回他们的分数)。
例子
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGEBYSCORE myzset -inf +inf
1) "one"
2) "two"
3) "three"
redis> ZRANGEBYSCORE myzset 1 2
1) "one"
2) "two"
redis> ZRANGEBYSCORE myzset (1 2
1) "two"
redis> ZRANGEBYSCORE myzset (1 (2
(empty list or set)
redis>
ZREM key member [member …]
起始版本:1.2.0
时间复杂度:O(M*log(N)),N是排序集中的元素数,M是要删除的元素数。
移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
当 key 存在但不是有序集类型时,返回一个错误。
返回值
integer-reply, 如下的整数:
返回的是从有序集合中删除的成员个数,不包括不存在的成员。
历史
- 2.4: 接受多个元素。在2.4之前的版本中,每次只能删除一个成员。
例子
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREM myzset "two"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "three"
4) "3"
redis>
IO模型简单介绍
一、什么是同步?什么是异步?
同步和异步的概念出来已经很久了,网上有关同步和异步的说法也有很多。以下是我个人的理解:
同步就是:如果有多个任务或者事件要发生,这些任务或者事件必须逐个地进行,一个事件或者任务的执行会导致整个流程的暂时等待,这些事件没有办法并发地执行;
异步就是:如果有多个任务或者事件发生,这些事件可以并发地执行,一个事件或者任务的执行不会导致整个流程的暂时等待。
这就是同步和异步。举个简单的例子,假如有一个任务包括两个子任务A和B,对于同步来说,当A在执行的过程中,B只有等待,直至A执行完毕,B才能执行;而对于异步就是A和B可以并发地执行,B不必等待A执行完毕之后再执行,这样就不会由于A的执行导致整个任务的暂时等待。
如果还不理解,可以先看下面这2段代码:
void fun1() {
}
void fun2() {
}
void function(){
fun1();
fun2();
.....
.....
}
这段代码就是典型的同步,在方法function中,fun1在执行的过程中会导致后续的fun2无法执行,fun2必须等待fun1执行完毕才可以执行。
接着看下面这段代码:
void fun1() {
}
void fun2() {
}
void function(){
new Thread(){
public void run() {
fun1();
}
}.start();
new Thread(){
public void run() {
fun2();
}
}.start();
.....
.....
}
这段代码是一种典型的异步,fun1的执行不会影响到fun2的执行,并且fun1和fun2的执行不会导致其后续的执行过程处于暂时的等待。
事实上,同步和异步是一个非常广的概念,它们的重点在于多个任务和事件发生时,一个事件的发生或执行是否会导致整个流程的暂时等待。我觉得可以将同步和异步与Java中的synchronized关键字联系起来进行类比。当多个线程同时访问一个变量时,每个线程访问该变量就是一个事件,对于同步来说,就是这些线程必须逐个地来访问该变量,一个线程在访问该变量的过程中,其他线程必须等待;而对于异步来说,就是多个线程不必逐个地访问该变量,可以同时进行访问。
因此,个人觉得同步和异步可以表现在很多方面,但是记住其关键在于多个任务和事件发生时,一个事件的发生或执行是否会导致整个流程的暂时等待。一般来说,可以通过多线程的方式来实现异步,但是千万记住不要将多线程和异步画上等号,异步只是宏观上的一个模式,采用多线程来实现异步只是一种手段,并且通过多进程的方式也可以实现异步。
二、什么是阻塞?什么是非阻塞?
在前面介绍了同步和异步的区别,这一节来看一下阻塞和非阻塞的区别。
阻塞就是:当某个事件或者任务在执行过程中,它发出一个请求操作,但是由于该请求操作需要的条件不满足,那么就会一直在那等待,直至条件满足;
非阻塞就是:当某个事件或者任务在执行过程中,它发出一个请求操作,如果该请求操作需要的条件不满足,会立即返回一个标志信息告知条件不满足,不会一直在那等待。
这就是阻塞和非阻塞的区别。也就是说阻塞和非阻塞的区别关键在于当发出请求一个操作时,如果条件不满足,是会一直等待还是返回一个标志信息。
举个简单的例子:
假如我要读取一个文件中的内容,如果此时文件中没有内容可读,对于阻塞来说就是会一直在那等待,直至文件中有内容可读;而对于非阻塞来说,就会直接返回一个标志信息告知文件中暂时无内容可读。
在网上有一些朋友将同步和异步分别与阻塞和非阻塞画上等号,事实上,它们是两组完全不同的概念。注意,理解这两组概念的区别对于后面IO模型的理解非常重要。
同步和异步着重点在于多个任务的执行过程中,一个任务的执行是否会导致整个流程的暂时等待;
而阻塞和非阻塞着重点在于发出一个请求操作时,如果进行操作的条件不满足是否会返会一个标志信息告知条件不满足。
理解阻塞和非阻塞可以同线程阻塞类比地理解,当一个线程进行一个请求操作时,如果条件不满足,则会被阻塞,即在那等待条件满足。
三、什么是阻塞IO? 什么是非阻塞IO?
在了解阻塞IO和非阻塞IO之前,先看下一个具体的IO操作过程是怎么进行的。
通常来说,IO操作包括:对硬盘的读写、对socket的读写以及外设的读写。
当用户线程发起一个IO请求操作(本文以读请求操作为例),内核会去查看要读取的数据是否就绪,对于阻塞IO来说,如果数据没有就绪,则会一直在那等待,直到数据就绪;对于非阻塞IO来说,如果数据没有就绪,则会返回一个标志信息告知用户线程当前要读的数据没有就绪。当数据就绪之后,便将数据拷贝到用户线程,这样才完成了一个完整的IO读请求操作,也就是说一个完整的IO读请求操作包括两个阶段:
查看数据是否就绪;
进行数据拷贝(内核将数据拷贝到用户线程)。
那么阻塞(blocking IO)和非阻塞(non-blocking IO)的区别就在于第一个阶段,如果数据没有就绪,在查看数据是否就绪的过程中是一直等待,还是直接返回一个标志信息。
Java中传统的IO都是阻塞IO,比如通过socket来读数据,调用read()方法之后,如果数据没有就绪,当前线程就会一直阻塞在read方法调用那里,直到有数据才返回;而如果是非阻塞IO的话,当数据没有就绪,read()方法应该返回一个标志信息,告知当前线程数据没有就绪,而不是一直在那里等待。
四、什么是同步IO? 什么是异步IO?
我们先来看一下同步IO和异步IO的定义,在《Unix网络编程》一书中对同步IO和异步IO的定义是这样的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes.
An asynchronous I/O operation does not cause the requesting process to be blocked.
从字面的意思可以看出:同步IO即 如果一个线程请求进行IO操作,在IO操作完成之前,该线程会被阻塞;
而异步IO为 如果一个线程请求进行IO操作,IO操作不会导致请求线程被阻塞。
事实上,同步IO和异步IO模型是针对用户线程和内核的交互来说的:
对于同步IO:当用户发出IO请求操作之后,如果数据没有就绪,需要通过用户线程或者内核不断地去轮询数据是否就绪,当数据就绪时,再将数据从内核拷贝到用户线程;
而异步IO:只有IO请求操作的发出是由用户线程来进行的,IO操作的两个阶段都是由内核自动完成,然后发送通知告知用户线程IO操作已经完成。也就是说在异步IO中,不会对用户线程产生任何阻塞。
这是同步IO和异步IO关键区别所在,同步IO和异步IO的关键区别反映在数据拷贝阶段是由用户线程完成还是内核完成。所以说异步IO必须要有操作系统的底层支持。
注意同步IO和异步IO与阻塞IO和非阻塞IO是不同的两组概念。
阻塞IO和非阻塞IO是反映在当用户请求IO操作时,如果数据没有就绪,是用户线程一直等待数据就绪,还是会收到一个标志信息这一点上面的。也就是说,阻塞IO和非阻塞IO是反映在IO操作的第一个阶段,在查看数据是否就绪时是如何处理的。
五、五种IO模型
在《Unix网络编程》一书中提到了五种IO模型,分别是:阻塞IO、非阻塞IO、多路复用IO、信号驱动IO以及异步IO。下面就分别来介绍一下这5种IO模型的异同。
阻塞IO模型
最传统的一种IO模型,即在读写数据过程中会发生阻塞现象。
当用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除block状态。
典型的阻塞IO模型的例子为:
data = socket.read();
如果数据没有就绪,就会一直阻塞在read方法。
非阻塞IO模型
当用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。
所以事实上,在非阻塞IO模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。
典型的非阻塞IO模型一般如下:
while(true){
data = socket.read();
if(data!= error){
处理数据
break;
}
}
但是对于非阻塞IO就有一个非常严重的问题,在while循环中需要不断地去询问内核数据是否就绪,这样会导致CPU占用率非常高,因此一般情况下很少使用while循环这种方式来读取数据。
多路复用IO模型
多路复用IO模型是目前使用得比较多的模型。Java NIO实际上就是多路复用IO。
在多路复用IO模型中,会有一个线程不断去轮询多个socket的状态,只有当socket真正有读写事件时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有socket读写事件进行时,才会使用IO资源,所以它大大减少了资源占用。
在Java NIO中,是通过selector.select()去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞。
也许有朋友会说,我可以采用 多线程+ 阻塞IO 达到类似的效果,但是由于在多线程 + 阻塞IO 中,每个socket对应一个线程,这样会造成很大的资源占用,并且尤其是对于长连接来说,线程的资源一直不会释放,如果后面陆续有很多连接的话,就会造成性能上的瓶颈。
而多路复用IO模式,通过一个线程就可以管理多个socket,只有当socket真正有读写事件发生才会占用资源来进行实际的读写操作。因此,多路复用IO比较适合连接数比较多的情况。
另外多路复用IO为何比非阻塞IO模型的效率高是因为在非阻塞IO中,不断地询问socket状态是通过用户线程去进行的,而在多路复用IO中,轮询每个socket状态是内核在进行的,这个效率要比用户线程要高的多。
不过要注意的是,多路复用IO模型是通过轮询的方式来检测是否有事件到达,并且对到达的事件逐一进行响应。因此对于多路复用IO模型来说,一旦事件响应体很大,那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询。
信号驱动IO模型
在信号驱动IO模型中,当用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。
异步IO模型
异步IO模型才是最理想的IO模型,在异步IO模型中,当用户线程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它收到一个asynchronous read之后,它会立刻返回,说明read请求已经成功发起了,因此不会对用户线程产生任何block。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它read操作完成了。也就说用户线程完全不需要知道实际的整个IO操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示IO操作已经完成,可以直接去使用数据了。
也就说在异步IO模型中,**IO操作的两个阶段都不会阻塞用户线程,这两个阶段都是由内核自动完成,然后发送一个信号告知用户线程操作已完成。**用户线程中不需要再次调用IO函数进行具体的读写。这点是和信号驱动模型有所不同的,在信号驱动模型中,当用户线程接收到信号表示数据已经就绪,然后需要用户线程调用IO函数进行实际的读写操作;而在异步IO模型中,收到信号表示IO操作已经完成,不需要再在用户线程中调用iO函数进行实际的读写操作。
注意,异步IO是需要操作系统的底层支持,在Java 7中,提供了Asynchronous IO。
前面四种IO模型实际上都属于同步IO,只有最后一种是真正的异步IO,因为无论是多路复用IO还是信号驱动模型,IO操作的第2个阶段都会引起用户线程阻塞,也就是内核进行数据拷贝的过程都会让用户线程阻塞。
六、两种高性能IO设计模式
在传统的网络服务设计模式中,有两种比较经典的模式:一种是 多线程,一种是线程池。对于多线程模式,也就说来了client,服务器就会新建一个线程来处理该client的读写事件,如下图所示:
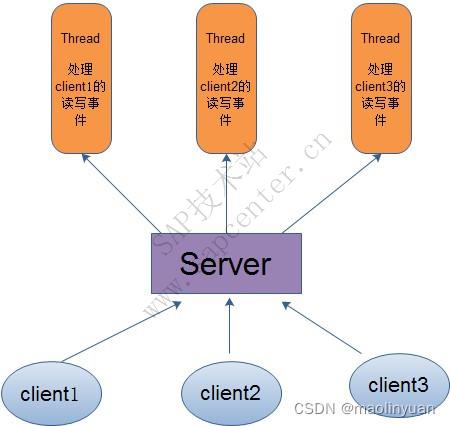
这种模式虽然处理起来简单方便,但是由于服务器为每个client的连接都采用一个线程去处理,使得资源占用非常大。因此,当连接数量达到上限时,再有用户请求连接,直接会导致资源瓶颈,严重的可能会直接导致服务器崩溃。
因此,为了解决这种一个线程对应一个客户端模式带来的问题,提出了采用线程池的方式,也就说创建一个固定大小的线程池,来一个客户端,就从线程池取一个空闲线程来处理,当客户端处理完读写操作之后,就交出对线程的占用。因此这样就避免为每一个客户端都要创建线程带来的资源浪费,使得线程可以重用。
但是线程池也有它的弊端,如果连接大多是长连接,因此可能会导致在一段时间内,线程池中的线程都被占用,那么当再有用户请求连接时,由于没有可用的空闲线程来处理,就会导致客户端连接失败,从而影响用户体验。因此,线程池比较适合大量的短连接应用。
因此便出现了下面的两种高性能IO设计模式:Reactor和Proactor。
在Reactor模式中,会先对每个client注册感兴趣的事件,然后有一个线程专门去轮询每个client是否有事件发生,当有事件发生时,便顺序处理每个事件,当所有事件处理完之后,便再转去继续轮询,如下图所示:
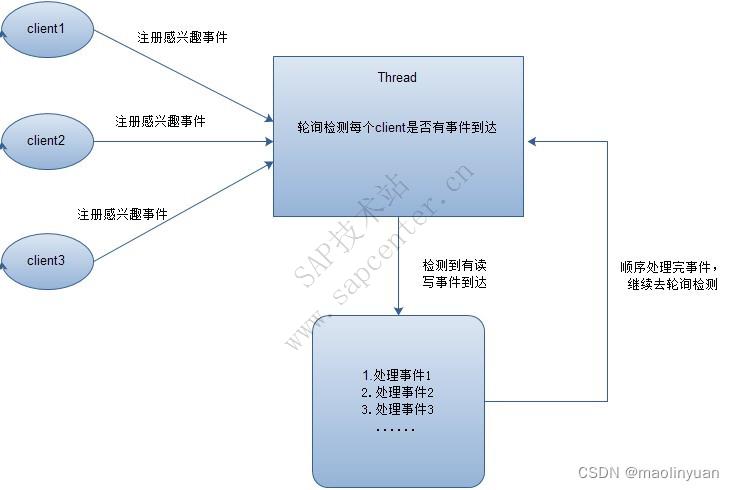
从这里可以看出,上面的五种IO模型中的多路复用IO就是采用Reactor模式。注意,上面的图中展示的 是顺序处理每个事件,当然为了提高事件处理速度,可以通过多线程或者线程池的方式来处理事件。
在Proactor模式中,当检测到有事件发生时,会新起一个异步操作,然后交由内核线程去处理,当内核线程完成IO操作之后,发送一个通知告知操作已完成,可以得知,异步IO模型采用的就是Proactor模式。
参考链接:
Redis的线程模型
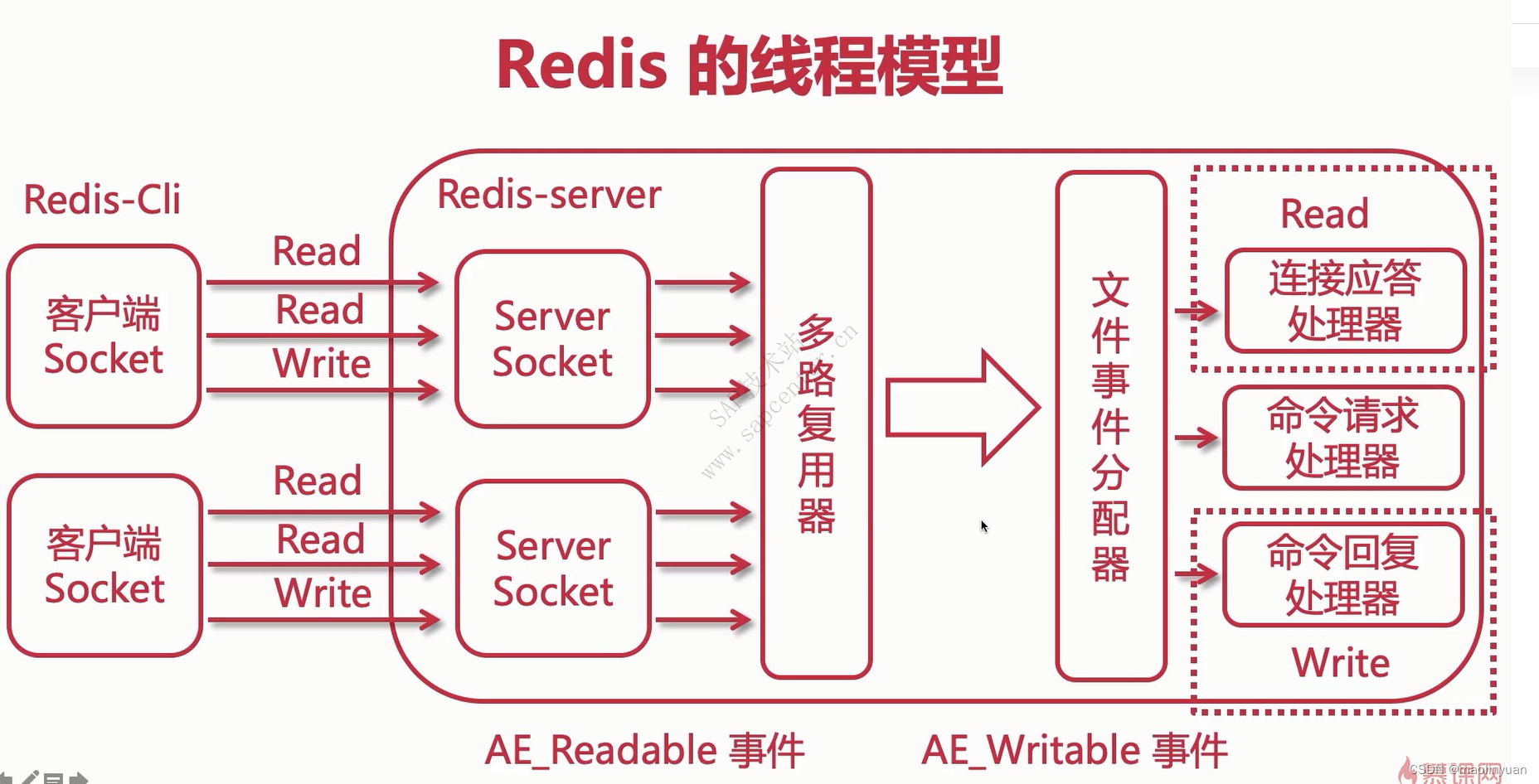
执行事件的流程
Redis 基于 Reactor 模式开发了自己的网络事件处理器 - 文件事件处理器(file event handler,后文简称为 FEH),而该处理器又是单线程的,所以redis设计为单线程模型。
- 采用I/O多路复用同时监听多个socket,根据socket当前执行的事件来为 socket 选择对应的事件处理器。
- 当被监听的socket准备好执行
accept、read、write、close等操作时,和操作对应的文件事件就会产生,这时FEH就会调用socket之前关联好的事件处理器来处理对应事件。
所以虽然FEH是单线程运行,但通过I/O多路复用监听多个socket,不仅实现高性能的网络通信模型,又能和 Redis 服务器中其它同样单线程运行的模块交互,保证了Redis内部单线程模型的简洁设计。
文件事件就是对socket操作的抽象, 每当一个 socket 准备好执行连接accept、read、write、close等操作时, 就会产生一个文件事件。 一个服务器通常会连接多个socket, 多个socket可能并发产生不同操作,每个操作对应不同文件事件。I/O 多路复用程序会负责监听多个socket。
尽管文件事件可能并发出现, 但 I/O 多路复用程序会将所有产生事件的socket放入队列, 通过该队列以有序、同步且每次一个socket的方式向文件事件分派器传送socket。当上一个socket产生的事件被对应事件处理器执行完后, I/O 多路复用程序才会向文件事件分派器传送下个socket。
文件事件分派器接收 I/O 多路复用程序传来的socket, 并根据socket产生的事件类型, 调用相应的事件处理器。服务器会为执行不同任务的套接字关联不同的事件处理器, 这些处理器是一个个函数, 它们定义了某个事件发生时, 服务器应该执行的动作。
Redis 为各种文件事件需求编写了多个处理器,若客户端:
- 连接Redis,对连接服务器的各个客户端进行应答,就需要将socket映射到连接应答处理器
- 写数据到Redis,接收客户端传来的命令请求,就需要映射到命令请求处理器
- 从Redis读数据,向客户端返回命令的执行结果,就需要映射到命令回复处理器
当主服务器和从服务器进行复制操作时, 主从服务器都需要映射到特别为复制功能编写的复制处理器。
值得注意的是,在执行命令阶段,由于Redis是单线程来处理命令的,所有每一条到达服务端的命令不会立刻执行,所有的命令都会进入一个队列中,然后逐个被执行。并且多个客户端发送的命令的执行顺序是不确定的。但是可以确定的是,不会有两条命令被同时执行,不会产生并行问题。
I/O 多路复用程序可以监听多个socket的 ae.h/AE_READABLE 事件和 ae.h/AE_WRITABLE 事件, 这两类事件和套接字操作之间的对应关系如下:
- 当socket可读(比如客户端对Redis执行
write/close操作),或有新的可应答的socket出现时(即客户端对Redis执行connect操作),socket就会产生一个AE_READABLE事件 - 当socket可写时(比如客户端对Redis执行read操作),socket会产生一个AE_WRITABLE事件。
I/O多路复用程序可以同时监听AE_REABLE和AE_WRITABLE两种事件,要是一个socket同时产生这两种事件,那么文件事件分派器优先处理AE_REABLE事件。即一个socket又可读又可写时, Redis服务器先读后写socket。
客户端和Redis服务器通信的整个过程:
Redis启动初始化时,将连接应答处理器跟AE_READABLE事件关联。
若一个客户端发起连接,会产生一个
AE_READABLE事件,然后由连接应答处理器负责和客户端建立连接,创建客户端对应的socket,同时将这个socket的AE_READABLE事件和命令请求处理器关联,使得客户端可以向主服务器发送命令请求。当客户端向Redis发请求时(不管读还是写请求),客户端socket都会产生一个
AE_READABLE事件,触发命令请求处理器。处理器读取客户端的命令内容, 然后传给相关程序执行。当Redis服务器准备好给客户端的响应数据后,会将socket的
AE_WRITABLE事件和命令回复处理器关联,当客户端准备好读取响应数据时,会在socket产生一个AE_WRITABLE事件,由对应命令回复处理器处理,即将准备好的响应数据写入socket,供客户端读取。命令回复处理器全部写完到 socket 后,就会删除该socket的
AE_WRITABLE事件和命令回复处理器的映射。
参考链接:
Redis客户端和服务端通信示例
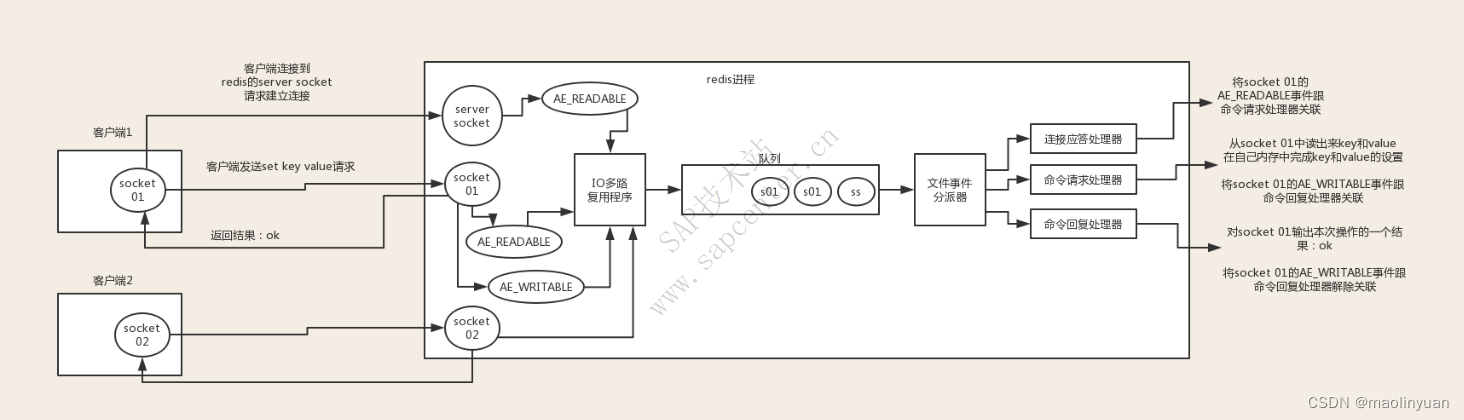
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
客户端socket01请求redis的server scoket建立连接,此时server socket生成AE_READABLE事件**,**IO多路复用程序监听到server socket产生的事件,并将该事件压入队列。
文件事件分派器从队列中拉取事件交给连接应答处理器,处理器同时生成一个与客户端通信的socket01,并将该scoket01的AE_READABLE事件与命令请求处理器关联
此时客户端scoket01发送一个set key value的请求,redis的scoket01接收到AE_READABLE事件,IO多路复用程序监听到事件,将事件压入队列,文件分派器取到事件,由于scoket01已经和命令请求处理器关联,所以命令请求处理器开始set key value,完毕后会将redis的scoket01的AE_WAITABLE事件关联到命令回复处理器
如果此时客户端准备好接收返回结果了,向redis中的socket01发起询问请求,那么 redis 中的 socket01 会产生一个
AE_WRITABLE事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对 socket01 输入本次操作的一个结果,比如ok,之后解除 socket01 的AE_WRITABLE事件与命令回复处理器的关联。
这样便完成了redis的一次通信。
参考链接:
Redis的事务机制
MULTI 、 EXEC 、 DISCARD 和 WATCH 是 Redis 事务相关的命令。事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
EXEC 命令负责触发并执行事务中的所有命令:
- 如果客户端在使用 MULTI 开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。
- 另一方面,如果客户端成功在开启事务之后执行 EXEC ,那么事务中的所有命令都会被执行。
由于Redis单线程的特性,所有的命令都是进入一个队列中,依次执行。因此不会有两条命令被同时执行,不会产生并行问题。这点和传统关系型数据库不一样,没有并行问题,也就没有像表锁、行锁这类锁竞争的问题了。
假设,客户端A提交的命令有A1、A2和A3 这三条,客户端B提交的命令有B1、B2和B3,在进入服务端队列后的顺序实际上很大部分是随机。假设是:A1、B1、B3、A3、B2、A2,可客户端A期望自己提交的是按照顺序一起执行的,它就可以使用事务实现:B2、A1、A2、A3、B1、B3,客户端B的命令执行顺序还是随机的,但是客户端A的命令执行顺序就保证了。
Redis 事务的本质是一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结说:Redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
Redis事务相关命令
WATCH key [key …]
起始版本:2.2.0
时间复杂度:O(1) for every key.
标记所有指定的key 被监视起来,在事务中有条件的执行(乐观锁)。
返回值
simple-string-reply: 总是 OK。
UNWATCH
起始版本:2.2.0
时间复杂度:O(1)
刷新一个事务中已被监视的所有key。
如果执行EXEC 或者DISCARD, 则不需要手动执行UNWATCH 。
返回值
simple-string-reply: 总是 OK。
MULTI
起始版本:1.2.0
标记一个事务块的开始。 随后的指令将在执行EXEC时作为一个原子执行。
返回值
simple-string-reply: 始终为OK
EXEC
起始版本:1.2.0
执行事务中所有在排队等待的指令并将链接状态恢复到正常 当使用WATCH 时,只有当被监视的键没有被修改,且允许检查设定机制时,EXEC会被执行
返回值
multi-bulk-reply: 每个元素与原子事务中的指令一一对应 当使用WATCH时,如果被终止,EXEC 则返回一个空的应答集合
DISCARD
起始版本:2.0.0
刷新一个事务中所有在排队等待的指令,并且将连接状态恢复到正常。
如果已使用WATCH,DISCARD将释放所有被WATCH的key。
返回值
status-reply:所有返回都是 OK
事务执行过程
multi命令可以将执行该命令的客户端从非事务状态切换至事务状态,执行后,后续的普通命令(非multi、watch、exec、discard的命令)都会被放在一个事务队列中,然后向客户端返回QUEUED回复。
事务队列是一个以先进先出(FIFO)的方式保存入队的命令,较先入队的命令会被放到数组的前面,而较后入队的命令则会被放到数组的后面。
当一个处于事务状态的客户端向服务器发送exec命令时,这个exec命令将立即被服务器执行。服务器会遍历这个客户端的事务队列,执行队列中保存的所有的命令,最后将执行命令所得的结果返回给客户端。
当一个处于事务状态的客户端向服务器发送discard命令时,表示事务取消,客户端从事务状态切换回非事务状态,对应的事务队列清空。
watch命令可被用作乐观锁。它可以在exec命令执行前,监视任意数量的数据库键,并在exec命令执行时,检查监视的键是否至少有一个已经被其他客户端修改过了,如果修改过了,服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复。而unwatch命令用于取消对所有键的监视。
要注意,watch是监视键被其他客户端修改过,即其他的会话连接中。如果你在同一个会话下自己watch自己改,是不生效的。
Redis事务的ACID分析
原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。
Redis 开始事务 multi 命令后,Redis 会为这个事务生成一个队列,每次操作的命令都会按照顺序插入到这个队列中。这个队列里面的命令不会被马上执行,直到 exec 命令提交事务,所有队列里面的命令会被一次性,并且排他的进行执行。
但是呢,当事务队列里面的命令执行报错时,会有两种情况:
一种错误类似于Java中的CheckedException,Redis执行器会检测出来,如果某个命令出现了这种错误,会自动取消事务,这是符合原子性的;
另一种错误类似于Java中的RuntimeExcpetion,Redis执行器检测不出来,当执行报错了已经来不及了,错误命令后续的命令依然会执行完毕,并不会回滚,因此不符合原子性。
一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
因为达不成原子性,其实严格上来讲,也就达不成一致性。
隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
回顾前面的基础,Redis 因为是单线程依次执行队列中的命令的,没有并发的操作,所以在隔离性上有天生的隔离机制。,当 Redis 执行事务时,Redis 的服务端保证在执行事务期间不会对事务进行中断,所以,Redis 事务总是以串行的方式运行,事务也具备隔离性。
持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
Redis 是否具备持久化,这个取决于 Redis 的持久化模式:
- 纯内存运行,不具备持久化,服务一旦停机,所有数据将丢失。
- RDB 模式,取决于 RDB 策略,只有在满足策略才会执行 Bgsave,异步执行并不能保证 Redis 具备持久化。
- AOF 模式,只有将 appendfsync 设置为 always,程序才会在执行命令同步保存到磁盘,这个模式下,Redis 具备持久化。(将 appendfsync 设置为 always,只是在理论上持久化可行,但一般不会这么操作)
简单总结
- Redis 具备了一定的原子性,但不支持回滚。
- Redis 不具备 ACID 中一致性的概念。(或者说 Redis 在设计时就无视这点)
- Redis 具备隔离性。
- Redis 通过一定策略可以保证持久性。
当然,我们也不应该拿传统关系型数据库事务的ACID特性去要求Redis,Redis设计更多的是追求简单与高性能,不会受制于传统 ACID 的束缚。
参考链接:
Redis 6.0前后版本分析比较
Redis 6.0版本前的单线程模型(网络线程模型)
Redis的核心网络模型选择用单线程来实现。正如redis官网上说,对于一个 DB 来说,CPU 通常不会是瓶颈,因为大多数请求不会是 CPU 密集型的,而是 I/O 密集型。具体到 Redis 的话,如果不考虑 RDB/AOF 等持久化方案,Redis 是完全的纯内存操作,执行速度是非常快的,因此这部分操作通常不会是性能瓶颈,Redis 真正的性能瓶颈在于网络 I/O,也就是客户端和服务端之间的网络传输延迟,因此 Redis 6.0版本前选择了单线程的 I/O 多路复用来实现它的核心网络模型。
使用单线程网络模型好处:
- 避免过多的上下文切换开销
多线程调度过程中必然需要在 CPU 之间切换线程上下文 context,而上下文的切换是有开销的。单线程则可以规避进程内频繁的线程切换开销,因为程序始终运行在进程中单个线程内,没有多线程切换的场景。 - 避免同步机制的开销
如果 Redis 选择多线程模型,势必涉及到底层数据同步的问题,必然会引入某些同步机制,比如锁,而我们知道 Redis 不仅仅提供了简单的 key-value 数据结构,还有 list、set 和 hash 等等其他丰富的数据结构,而不同的数据结构对同步访问的加锁粒度又不尽相同,可能会导致在操作数据过程中带来很多加锁解锁的开销,增加程序复杂度的同时还会降低性能。 - 简单可维护
Redis 的作者 Salvatore Sanfilippo (别称 antirez) 对 Redis 的设计和代码有着近乎偏执的简洁性理念。因此代码的简单可维护性必然是 Redis 早期的核心准则之一,而引入多线程必然会导致代码的复杂度上升和可维护性下降。前面我们提到引入多线程必须的同步机制,如果 Redis 使用多线程模式,那么所有的底层数据结构都必须实现成线程安全的,这无疑又使得 Redis 的实现变得更加复杂。总而言之,Redis 选择单线程可以说是多方博弈之后的一种权衡:在保证足够的性能表现之下,使用单线程保持代码的简单和可维护性。
在 v6.0 版本之前,Redis 的核心网络模型一直是一个典型的单 Reactor 模型:利用 epoll/select/kqueue 等多路复用技术,在单线程的事件循环中不断去处理事件(客户端请求),最后回写响应数据到客户端。
Redis 6.0后的多线程模型(网络线程模型)
事件处理器不再是单线程的事件循环,而是有多个线程(IO Thread)各自维护一个独立的事件循环。整体模型是由 Main 线程负责接收新连接,并分发给 IO Thread 去独立处理(解析请求命令),但是具体命令的执行还是使用main 线程来执行,最后使用IO 线程回写响应给客户端。
IO线程轮训socket列表读事件,然后解析为redis命令,并把解析好的命令放到全局待执行队列,然后主线程从全局待执行队列读取命令然后具体执行命令,最后把响应结果分配到不同IO线程,由IO线程来具体执行把响应结果写回客户端。
也就是具体命令执行还是由main线程所在的事件循环单线程处理,只是读写socket事件由IO线程来处理。
虽然多线程方案能提升1倍以上的性能,但整个方案仍然比较粗糙:
- 首先所有命令的执行仍然在主线程中进行,仍然存在性能瓶颈。
- 另外IO 读写为批处理读写,即所有 IO 线程先读取完请求数据并且解析为redis命令后,主线程才开始执行解析的命令;然后待主线程执行完所有的redis命令后,才让所有 IO 线程再一起回复所有响应;也就是说不同请求需要相互等待,效率不高。
- 最后在 IO 批处理读写和主线程处理时,使用线程自旋检测等待(如下代码),效率更是低下,即便任务很少,也很容易把 CPU 打满。
Redis任务多线程模型(异步任务,非网络线程模型)
Redis 在 v4.0 版本的时就已经引入了的多线程来做一些异步操作,这主要是为了解决一些非常耗时的命令,通过将这些命令的执行进行异步化,避免阻塞单线程网络模型的事件循环。
Redis 启动时,会创建三个任务队列,并对应构建 3 个 BIO 线程,三个 BIO 线程与 3 个任务队列之间一一对应。BIO 线程分别处理如下 3 种任务。
- close 关闭文件任务。rewriteaof 完成后,主线程需要关闭旧的 AOF 文件,就向 close 队列插入一个旧 AOF 文件的关闭任务。由 close 线程来处理。
- fysnc 任务。Redis 将 AOF 数据缓冲写入文件内核缓冲后,需要定期将系统内核缓冲数据写入磁盘,此时可以向 fsync 队列写入一个同步文件缓冲的任务,由 fsync 线程来处理。
- lazyfree 任务。Redis 在需要淘汰元素数大于 64 的聚合类数据类型时,如列表、集合、哈希等,就往延迟清理队列中写入待回收的对象,由 lazyfree 线程后续进行异步回收。
BIO 线程的整个处理流程如图所示。当主线程有慢任务需要异步处理时。就会向对应的任务队列提交任务。提交任务时,首先申请内存空间,构建 BIO 任务。然后对队列锁进行加锁,在队列尾部追加新的 BIO 任务,最后尝试唤醒正在等待任务的 BIO 线程。
BIO 线程启动时或持续处理完所有任务,发现任务队列为空后,就会阻塞,并等待新任务的到来。当主线程有新任务后,主线程会提交任务,并唤醒 BIO 线程。BIO 线程随后开始轮询获取新任务,并进行处理。当处理完所有 BIO 任务后,则再次进入阻塞,等待下一轮唤醒。
分析总结
在Redis6.0版本前,其提供单线程网络模型,使用单线程来处理socket的读写事件、命令解析、命令执行工作。
在Redis6.0版本后,提供了多线程模型逻辑,其中socket的读写事件、命令解析使用IO线程来处理,但是具体命令的执行还是使用单线程事件循环来进行处理。但是其实现并不优雅。
最后无论是单线程还是多线程网络模型,命令的具体执行还是靠单线程事件循环来执行的,如果要执行的命令非常耗时,则会阻塞事件循环的执行,使得其他命令得不到及时执行,所以Redis4.0时开始提供异步多线程任务来解决耗时比较长的命令的执行,将其异步化执行,使得主事件循环线程可以及时得到释放。
参考链接:
SpringBoot整合Redis
项目中添加依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>配置文件中配置Redis的信息
spring: # redis 配置 redis: # 地址 host: 192.168.44.88 # 端口,默认为6379 port: 6379 # 数据库索引 database: 0 # 密码 password: imooc # 连接超时时间 timeout: 10s lettuce: pool: # 连接池中的最小空闲连接 min-idle: 0 # 连接池中的最大空闲连接 max-idle: 8 # 连接池的最大数据库连接数 max-active: 8 # #连接池最大阻塞等待时间(使用负值表示没有限制) max-wait: -1ms项目中RedisConfig配置
import com.fasterxml.jackson.annotation.JsonAutoDetect; import com.fasterxml.jackson.annotation.JsonTypeInfo; import com.fasterxml.jackson.annotation.PropertyAccessor; import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator; import org.springframework.cache.annotation.CachingConfigurerSupport; import org.springframework.cache.annotation.EnableCaching; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.redis.connection.RedisConnectionFactory; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.core.script.DefaultRedisScript; import org.springframework.data.redis.serializer.StringRedisSerializer; /** * redis配置 */ @Configuration @EnableCaching public class RedisConfig extends CachingConfigurerSupport { @Bean @SuppressWarnings(value = {"unchecked", "rawtypes"}) public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) { RedisTemplate<Object, Object> template = new RedisTemplate<>(); template.setConnectionFactory(connectionFactory); // 序列化类可以按需更改 FastJson2JsonRedisSerializer serializer = new FastJson2JsonRedisSerializer(Object.class); ObjectMapper mapper = new ObjectMapper(); mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); mapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY); serializer.setObjectMapper(mapper); // 使用StringRedisSerializer来序列化和反序列化redis的key值 template.setKeySerializer(new StringRedisSerializer()); template.setValueSerializer(serializer); // Hash的key也采用StringRedisSerializer的序列化方式 template.setHashKeySerializer(new StringRedisSerializer()); template.setHashValueSerializer(serializer); template.afterPropertiesSet(); return template; } @Bean public DefaultRedisScript<Long> limitScript() { DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>(); redisScript.setScriptText(limitScriptText()); redisScript.setResultType(Long.class); return redisScript; } /** * 限流脚本 */ private String limitScriptText() { return "local key = KEYS[1]\n" + "local count = tonumber(ARGV[1])\n" + "local time = tonumber(ARGV[2])\n" + "local current = redis.call('get', key);\n" + "if current and tonumber(current) > count then\n" + " return tonumber(current);\n" + "end\n" + "current = redis.call('incr', key)\n" + "if tonumber(current) == 1 then\n" + " redis.call('expire', key, time)\n" + "end\n" + "return tonumber(current);"; } }也可以在项目中设置Redis配置
public class SimpleUtils { private static RedisTemplate<Object, Object> createRedisTemplate() { //redis配置 RedisConfiguration redisConfiguration = new RedisStandaloneConfiguration("192.168.44.88",6379); ((RedisStandaloneConfiguration) redisConfiguration).setDatabase(0); ((RedisStandaloneConfiguration) redisConfiguration).setPassword("123456"); //连接池配置 GenericObjectPoolConfig<?> genericObjectPoolConfig = new GenericObjectPoolConfig<>(); genericObjectPoolConfig.setMaxIdle(8); genericObjectPoolConfig.setMinIdle(0); genericObjectPoolConfig.setMaxTotal(8); genericObjectPoolConfig.setMaxWaitMillis(-1); //redis客户端配置 (有两种 Jedis和Lettuce SpringBoot中默认使用Lettuce) LettucePoolingClientConfiguration.LettucePoolingClientConfigurationBuilder builder = LettucePoolingClientConfiguration.builder(). commandTimeout(Duration.ofMillis(8)); builder.shutdownTimeout(Duration.ofMillis(8)); builder.poolConfig(genericObjectPoolConfig); LettuceClientConfiguration lettuceClientConfiguration = builder.build(); //根据配置和客户端配置创建连接 LettuceConnectionFactory lettuceConnectionFactory = new LettuceConnectionFactory(redisConfiguration,lettuceClientConfiguration); lettuceConnectionFactory .afterPropertiesSet(); RedisTemplate<Object, Object> template = new RedisTemplate<>(); template.setConnectionFactory(lettuceConnectionFactory); Jackson2JsonRedisSerializer<Object> serializer = new Jackson2JsonRedisSerializer<>(Object.class); ObjectMapper mapper = new ObjectMapper(); mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); mapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY); serializer.setObjectMapper(mapper); // 使用StringRedisSerializer来序列化和反序列化redis的key值 template.setKeySerializer(new StringRedisSerializer()); template.setValueSerializer(serializer); // Hash的key也采用StringRedisSerializer的序列化方式 template.setHashKeySerializer(new StringRedisSerializer()); template.setHashValueSerializer(serializer); template.afterPropertiesSet(); return template; } }使用RedisTemplate操作Redis
- 针对jedis客户端中大量api进行了归类封装,将同一类型操作封装为operation接口
- ValueOperations:简单K-V操作
- SetOperations:set类型数据操作
- ZSetOperations:zset类型数据操作
- HashOperations:针对map类型的数据操作
- ListOperations:针对list类型的数据操作
- 提供了对key的bound(绑定)便捷化操作API,可以通过bound封装指定的key,然后进行一系列的操作而无须“显式”的再次指定Key,即BoundKeyOperations
- BoundValueOperations
- BoundSetOperations
- BoundListOperations
- BoundSetOperations
- BoundHashOperations
- 将事务操作封装,有容器控制。
- 针对数据的“序列化/反序列化”,提供了多种可选择策略(RedisSerializer)
参考链接:
- 针对jedis客户端中大量api进行了归类封装,将同一类型操作封装为operation接口
使用Redis可视化管理工具进行管理
github : AnotherRedisDesktopManager
gitee : AnotherRedisDesktopManager
虚拟机克隆方案(解决克隆之后无法联网)
创建克隆虚拟机,选择全量克隆
克隆之后因为网卡配置、固件序列号和之前虚拟机一模一样,可能会出现IP飘逸等问题
运行克隆的虚拟机
查看ip信息,拷贝并保存网卡的mac地址以备后用
ip addr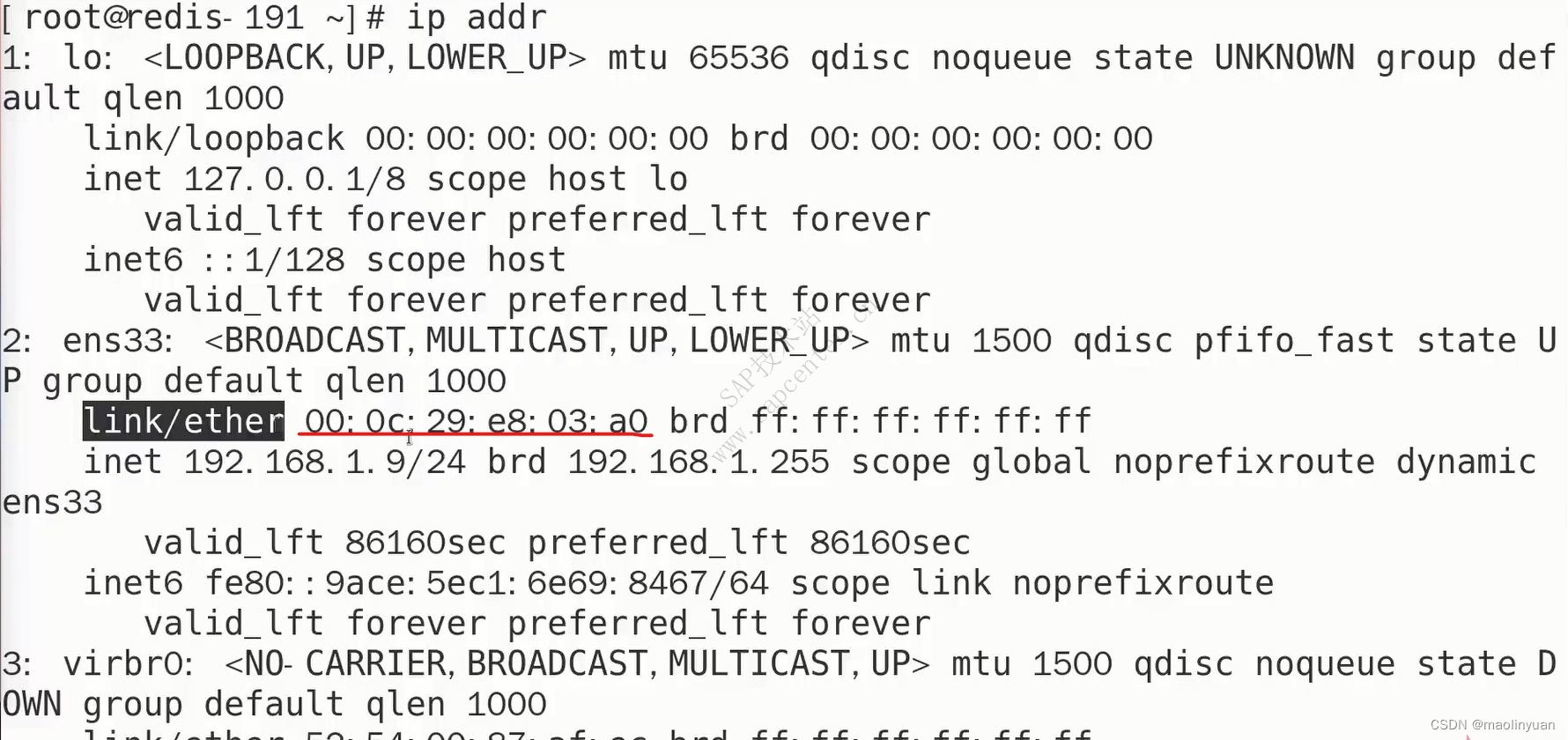
修改rules文件中网卡mac地址内容
vim /etc/udev/rules.d/70-persistent-ipoib.rules
修改虚拟机ip配置文件中的IP和网卡mac地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33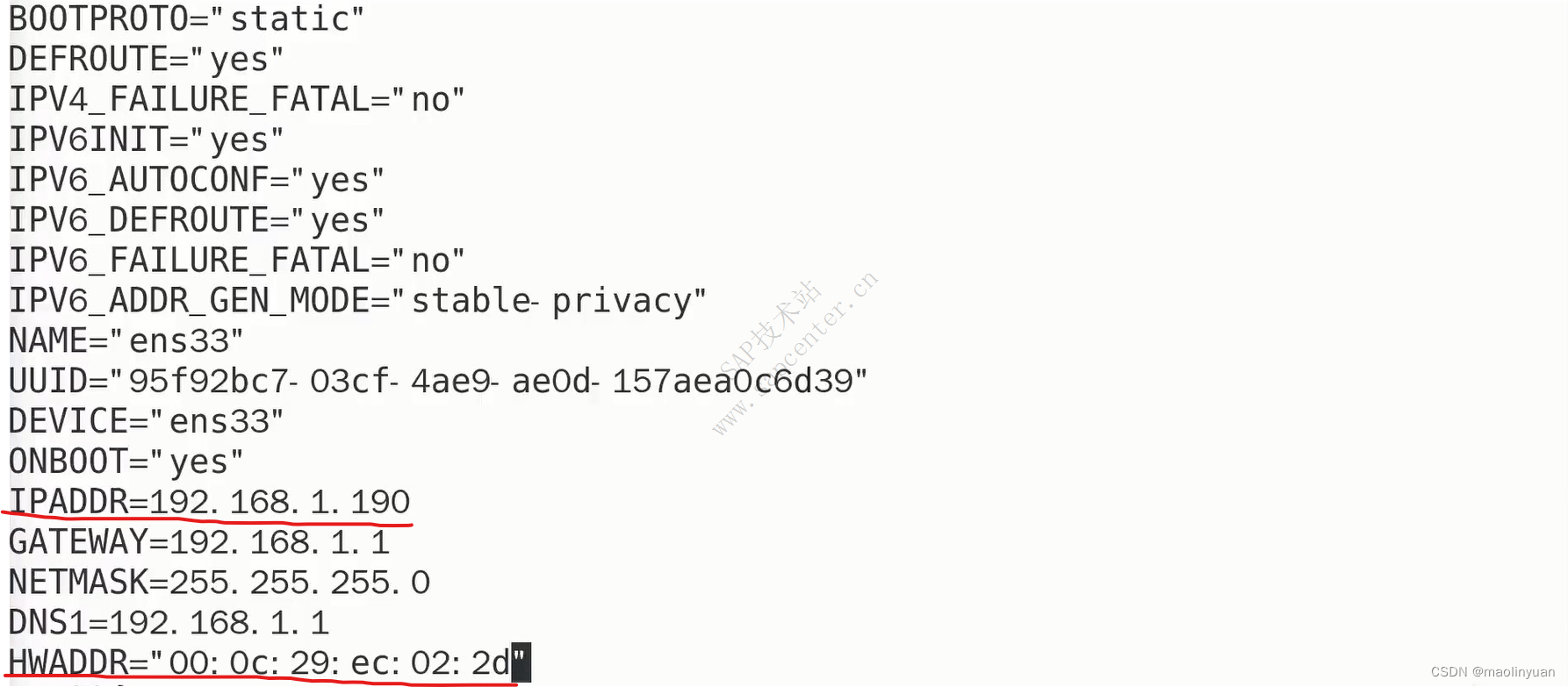
重启虚拟机或重启网卡
reboot # 重启 service network restart # 重启网卡
Redis发布订阅和stream类型
订阅,取消订阅和发布实现了发布/订阅消息范式(引自wikipedia),发送者(发布者)不是计划发送消息给特定的接收者(订阅者)。而是发布的消息分到不同的频道,不需要知道什么样的订阅者订阅。订阅者对一个或多个频道感兴趣,只需接收感兴趣的消息,不需要知道什么样的发布者发布的。这种发布者和订阅者的解耦合可以带来更大的扩展性和更加动态的网络拓扑。
Redis发布订阅相关命令
PSUBSCRIBE pattern [pattern …]
起始版本:2.0.0
时间复杂度:O(N) 其中N是客户端已订阅的模式数。
订阅给定的模式(patterns)。
支持的模式(patterns)有:
h?llosubscribes tohello,halloandhxlloh*llosubscribes tohlloandheeeelloh[ae]llosubscribes tohelloandhallo,but nothillo
如果想输入普通的字符,可以在前面添加\
[PUBSUB subcommand argument [argument …]]
起始版本:2.8.0
时间复杂度:O(N) 对于CHANNELS子命令,其中N是活动通道的数量,并假设恒定时间模式匹配(相对较短的通道和模式)。O(N)表示NUMSUB子命令,其中N是请求的通道数。O(1)代表NUMPAT小组委员会。
PUBSUB 是自省命令,能够检测PUB/SUB子系统的状态。它由分别详细描述的子命令组成。通用格式如下:
PUBSUB <subcommand> ... args ...
PUBSUB CHANNELS [pattern]
列出当前active channels.活跃是指信道含有一个或多个订阅者(不包括从模式接收订阅的客户端) 如果pattern未提供,所有的信道都被列出,否则只列出匹配上指定全局-类型模式的信道被列出.
返回值
array-reply: 活跃的信道列表,或者符合指定模式的信道
PUBSUB NUMSUB [channel-1 … channel-N]
列出指定信道的订阅者个数(不包括订阅模式的客户端订阅者)
返回值
array-reply: 信道的列表和每个列表中订阅者的个数. 格式为 信道,个数,信道,个数,… 简单的列表.
注意,不给定任何频道而直接调用这个命令也是可以的, 在这种情况下,命令只返回一个空列表.
PUBSUB NUMPAT
返回订阅模式的数量(使用命令PSUBSCRIBE实现).注意, 这个命令返回的不是订阅模式的客户端的数量, 而是客户端订阅的所有模式的数量总和。
PUBLISH channel message
起始版本:2.0.0
时间复杂度:O(N+M) 其中N是订阅接收信道的客户端数量,M是订阅模式的总数(由任何客户端)。
将信息 message 发送到指定的频道 channel
返回值
integer-reply: 收到消息的客户端数量。
[PUNSUBSCRIBE pattern [pattern …]]
起始版本:2.0.0
时间复杂度:O(N+M) 其中N是订阅接收信道的客户端数量,M是订阅模式的总数(由任何客户端)。
指示客户端退订指定模式,若果没有提供模式则退出所有模式。
如果没有模式被指定,即一个无参数的 PUNSUBSCRIBE 调用被执行,那么客户端使用 PSUBSCRIBE 命令订阅的所有模式都会被退订。 在这种情况下,命令会返回一个信息,告知客户端所有被退订的模式。
SUBSCRIBE channel [channel …]
起始版本:2.0.0
时间复杂度:O(N) 这里的N是要订阅的通道数
订阅给指定频道的信息。
一旦客户端进入订阅状态,客户端就只可接受订阅相关的命令SUBSCRIBE、PSUBSCRIBE、UNSUBSCRIBE和PUNSUBSCRIBE除了这些命令,其他命令一律失效。
[UNSUBSCRIBE channel [channel …]]
起始版本:2.0.0
时间复杂度:O(N) 这里N是客户端已经订阅的通道数
指示客户端退订给定的频道,若没有指定频道,则退订所有频道.
如果没有频道被指定,即,一个无参数的 UNSUBSCRIBE 调用被执行,那么客户端使用 SUBSCRIBE 命令订阅的所有频道都会被退订。 在这种情况下,命令会返回一个信息,告知客户端所有被退订的频道。
简单发布订阅命令的使用
- 开启本地 Redis 服务,开启两个 redis-cli 客户端。
- 在第一个 redis-cli 客户端输入 SUBSCRIBE runoobChat,意思是订阅
runoobChat频道。 - 在第二个 redis-cli 客户端输入 PUBLISH runoobChat “Redis PUBLISH test” 往 runoobChat 频道发送消息,这个时候在第一个 redis-cli 客户端就会看到由第二个 redis-cli 客户端发送的测试消息。
Stream类型介绍和使用
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
Stream是Redis5.0版本中新增加的数据结构,是一个包含零个或任意多个流元素的有序队列,队列中的每个元素都包含一个ID和任意多个键值对,这些元素会根据ID的大小在流中有序的进行排列。
通过将元素ID与时间进行关联,并强制要求新元素的ID必须大于旧元素的ID,Redis从逻辑上将流变成了一种只执行追加操作(append only)的数据结构,这种特性对于使用流实现消息队列和事件系统来说是非常重要的:可以确信,新的消息和事件只会出现在已有消息和事件之后,就像现实世界里新事件总是发生在已有事件之后一样,一切都是有序进行的。
Stream图解
消费者组:Consumer Group,即使用XGROUP CREATE命令创建的,一个消费者组中可以存在多个消费者,这些消费者之间是竞争关系。
- 同一条消息,只能被这个消费者组中的某个消费者获取。
- 多个消费者之间是相互独立的,互不干扰。
消费者: Consumer 消费消息。last_delivered_id: 这个id保证了在同一个消费者组中,一个消息只能被一个消费者获取。每当消费者组的某个消费者读取到了这个消息后,这个last_delivered_id的值会往后移动一位,保证消费者不会读取到重复的消息。pending_ids:记录了消费者读取到的消息id列表,但是这些消息可能还没有处理,如果认为某个消息处理,需要调用ack命令。这样就确保了某个消息一定会被执行一次。消息内容:是一个键值对的格式。Stream中消息的ID:默认情况下,ID使用*,redis可以自动生成一个,格式为时间戳-序列号,也可以自己指定,一般使用默认生成的即可,且后生成的id号要比之前生成的大。
Stream的特点
- 是可持久化的,可以保证数据不丢失。
- 支持消息的多播、分组消费。
- 支持消息的有序性
参考链接:
消息队列相关命令
总览
- XADD - 添加消息到末尾
- XTRIM - 对流进行修剪,限制长度
- XDEL - 删除消息
- XLEN - 获取流包含的元素数量,即消息长度
- XRANGE - 获取消息列表,会自动过滤已经删除的消息
- XREVRANGE - 反向获取消息列表,ID 从大到小
- XREAD - 以阻塞或非阻塞方式获取消息列表
XADD key ID field string [field string …]
起始版本:5.0.0
时间复杂度:O(log(N)) N是已经进入流的项目数。
将指定的流条目追加到指定key的流中。 如果key不存在,作为运行这个命令的副作用,将使用流的条目自动创建key。
一个条目是由一组键值对组成的,它基本上是一个小的字典。 键值对以用户给定的顺序存储,并且读取流的命令(如XRANGE 或者 XREAD) 可以保证按照通过XADD添加的顺序返回。
XADD是唯一可以向流添加数据的Redis命令,但是还有其他命令, 例如XDEL和XTRIM,他们能够从流中删除数据。
将Stream ID指定为参数
流条目ID标识流内的给定条目。 如果指定的ID参数是字符*(星号ASCII字符),XADD命令会自动为您生成一个唯一的ID。 但是,也可以指定一个良好格式的ID,以便新的条目以指定的ID准确存储, 虽然仅在极少数情况下有用。
ID是由-隔开的两个数字组成的:
1526919030474-55
两个部分数字都是64位的,当自动生成ID时,第一部分是生成ID的Redis实例的毫秒格式的Unix时间。 第二部分只是一个序列号,以及是用来区分同一毫秒内生成的ID的。
ID保证始终是递增的:如果比较刚插入的条目的ID,它将大于其他任何过去的ID, 因此条目在流中是完全排序的。为了保证这个特性,如果流中当前最大的ID的时间 大于实例的当前本地时间,将会使用前者,并将ID的序列部分递增。例如, 本地始终回调了,或者在故障转移之后新主机具有不同的绝对时间,则可能发生这种情况。
当用户为XADD命令指定显式ID时,最小有效的ID是0-1, 并且用户必须指定一个比当前流中的任何ID都要大的ID,否则命令将失败。 通常使用特定ID仅在您有另一个系统生成唯一ID(例如SQL表), 并且您确实希望Redis流ID与该另一个系统的ID匹配时才有用。
上限流
可以使用MAXLEN选项来限制流中的最大元素数量。
与使用XADD添加条目相比较,使用MAXLEN修整会很昂贵: 流由宏节点表示为基数树,以便非常节省内存。改变由几十个元素组成的单个宏节点不是最佳的。 因此可以使用以下特殊形式提供命令:
XADD mystream MAXLEN ~ 1000 * ... entry fields here ...
在选项MAXLEN和实际计数中间的参数~的意思是,用户不是真的需要精确的1000个项目。 它可以多几十个条目,但决不能少于1000个。通过使用这个参数,仅当我们移除整个节点的时候才执行修整。 这使得命令更高效,而且这也是我们通常想要的。
有关流的其他信息
更多关于Redis流的信息请参阅我们的Redis Streams介绍文档。
返回值
bulk-string-reply:该命令返回添加的条目的ID。如果ID参数传的是*,那么ID是自动生成的, 否则,命令仅返回用户在插入期间指定的相同的ID。
例子
redis> XADD mystream * name Sara surname OConnor
"1539863454486-0"
redis> XADD mystream * field1 value1 field2 value2 field3 value3
"1539863454486-1"
redis> XLEN mystream
(integer) 2
redis> XRANGE mystream - +
1) 1) "1539863454486-0"
2) 1) "name"
2) "Sara"
3) "surname"
4) "OConnor"
2) 1) "1539863454486-1"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
redis>
XTRIM key MAXLEN [~] count
起始版本:5.0.0
时间复杂度:O(log(N)) + M ,N是修剪前流中的条目数,M是被逐出的条目数。但是,M常量时间非常小,因为条目被组织在包含多个条目的宏节点中,这些条目可以通过一次释放释放。
XTRIM将流裁剪为指定数量的项目,如有需要,将驱逐旧的项目(ID较小的项目)。此命令被设想为接受多种修整策略,但目前只实现了一种,即MAXLEN,并且与XADD中的MAXLEN选项完全相同。
例如,下面的命令会将流裁剪到最新的1000个项目:
XTRIM mystream MAXLEN 1000
可以使用以下特殊形式提供命令,以提高其效率:
XTRIM mystream MAXLEN ~ 1000
在选项MAXLEN和实际计数中间的参数~的意思是,用户不是真的需要精确的1000个项目。它可以多几十个条目,但决不能少于1000个。通过使用这个参数,仅当我们移除整个节点的时候才执行修整。这使得命令更高效,而且这也是我们通常想要的。
返回值
integer-reply:该命令返回从流中删除的条目数。
例子
redis> XADD mystream * field1 A field2 B field3 C field4 D
"1539863719429-0"
redis> XTRIM mystream MAXLEN 2
ERR Unknown or disabled command 'XTRIM'
redis> XRANGE mystream - +
1) 1) "1539863719429-0"
2) 1) "field1"
2) "A"
3) "field2"
4) "B"
5) "field3"
6) "C"
7) "field4"
8) "D"
redis>
XDEL key ID [ID …]
起始版本:5.0.0
时间复杂度:O(log(N)) N是流中的项目数。
从指定流中移除指定的条目,并返回成功删除的条目的数量,在传递的ID不存在的情况下, 返回的数量可能与传递的ID数量不同。
通常,你可能将Redis流想象为一个仅附加的数据结构,但是Redis流是存在于内存中的, 所以我们也可以删除条目。这也许会有用,例如,为了遵守特定的隐私策略。
理解删除条目的底层细节
Redis流以一种使其内存高效的方式表示:使用基数树来索引包含线性数十个Stream条目的宏节点。 通常,当你从Stream中删除一个条目的时候,条目并没有真正被驱逐,只是被标记为删除。
最终,如果宏节点中的所有条目都被标记为删除,则会销毁整个节点,并回收内存。 这意味着如果你从Stream里删除大量的条目,比如超过50%的条目,则每一个条目的内存占用可能会增加, 因为Stream将会开始变得碎片化。然而,流的表现将保持不变。
在Redis未来的版本中,当一个宏节点内删除条目达到一定数量的时候,我们有可能会触发节点垃圾回收机制。 目前,根据我们对这种数据结构的预期用途,还不太适合增加这样的复杂度。
返回值
例子
> XADD mystream * a 1
1538561698944-0
> XADD mystream * b 2
1538561700640-0
> XADD mystream * c 3
1538561701744-0
> XDEL mystream 1538561700640-0
(integer) 1
127.0.0.1:6379> XRANGE mystream - +
1) 1) 1538561698944-0
2) 1) "a"
2) "1"
2) 1) 1538561701744-0
2) 1) "c"
2) "3"
XLEN key
起始版本:5.0.0
时间复杂度:O(1)
返回流中的条目数。如果指定的key不存在,则此命令返回0,就好像该流为空。 但是请注意,与其他的Redis类型不同,零长度流是可能的,所以你应该调用TYPE 或者 EXISTS 来检查一个key是否存在。
一旦内部没有任何的条目(例如调用XDEL后),流不会被自动删除,因为可能还存在与其相关联的消费者组。
返回值
例子
redis> XADD mystream * item 1
"1539863829481-0"
redis> XADD mystream * item 2
"1539863829482-0"
redis> XADD mystream * item 3
"1539863829482-1"
redis> XLEN mystream
(integer) 3
redis>
XRANGE key start end [COUNT count]
起始版本:5.0.0
时间复杂度:O(log(N)+M) N是流中的元素数,M是返回的元素数。如果M是常数(例如总是要求计数的前10个元素),你可以考虑它O(log(n))。
此命令返回流中满足给定ID范围的条目。范围由最小和最大ID指定。所有ID在指定的两个ID之间或与其中一个ID相等(闭合区间)的条目将会被返回。
XRANGE命令有许多用途:
- 返回特定时间范围的项目。这是可能的,因为流的ID与时间相关。
- 增量迭代流,每次迭代只返回几个项目。但它在语义上比
SCAN函数族强大很多。 - 从流中获取单个条目,提供要获取两次的条目的ID:作为查询间隔的开始和结束。
该命令还有一个倒序命令,以相反的顺序返回项目,叫做XREVRANGE,除了返回顺序相反以外,它们是完全相同的。
特殊ID:- 和 +
特殊ID-和+分别表示流中可能的最小ID和最大ID,因此,以下命令将会返回流中的每一个条目:
> XRANGE somestream - +
1) 1) 1526985054069-0
2) 1) "duration"
2) "72"
3) "event-id"
4) "9"
5) "user-id"
6) "839248"
2) 1) 1526985069902-0
2) 1) "duration"
2) "415"
3) "event-id"
4) "2"
5) "user-id"
6) "772213"
... other entries here ...
- ID实际上与指定0-0完全一样,而+则相当于18446744073709551615-18446744073709551615,但是它们更适合输入。
不完全ID
流的ID由两部分组成,一个Unix毫秒时间戳和一个为同一毫秒插入的序列号。使用XRANGE仅指定ID的第一部分是可能的,即毫秒时间部分,如下面的例子所示:
> XRANGE somestream 1526985054069 1526985055069
在这种情况中,XRANGE将会使用-0自动补全开始ID,以及使用-18446744073709551615自动补全结束ID,以便返回所有在两个毫秒值之间生成的条目。这同样意味着,重复两个相同的毫秒时间,我们将会得到在这一毫秒内产生的所有条目,因为序列号范围将从0到最大值。
以这种方式使用XRANGE用作范围查询命令以在指定时间内获取条目。这非常方便,以便访问流中过去事件的历史记录。
返回最大条目数
使用COUNT选项可以减少报告的条目数。这是一个非常重要的特性,虽然它看起来很边缘,因为它允许,例如,模型操作,比如给我大于或等于以下ID的条目:
> XRANGE somestream 1526985054069-0 + COUNT 1
1) 1) 1526985054069-0
2) 1) "duration"
2) "72"
3) "event-id"
4) "9"
5) "user-id"
6) "839248"
在上面的例子中,条目1526985054069-0存在,否则服务器将发送给我们下一个条目。使用COUNT也是使用XRANGE作为迭代器的基础。
迭代流
为了迭代流,我们可以如下进行。让我们假设每次迭代我们需要两个元素。我们开始获取前两个元素,这是微不足道的:
> XRANGE writers - + COUNT 2
1) 1) 1526985676425-0
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) 1526985685298-0
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
然后,不是从-再次开始迭代,我们使用前一次XRANGE调用中返回的最后的条目ID作为范围的开始,将ID的序列部分加1。
最后一个条目的ID是1526985685298-0,所以我们只需要在序列中加1以获得1526985685298-1,并继续我们的迭代:
> XRANGE writers 1526985685298-1 + COUNT 2
1) 1) 1526985691746-0
2) 1) "name"
2) "Toni"
3) "surname"
4) "Morris"
2) 1) 1526985712947-0
2) 1) "name"
2) "Agatha"
3) "surname"
4) "Christie"
依此类推,最终,这将允许访问流中的所有条目。很明显,我们可以从任意ID开始迭代,或者甚至从特定的时间开始,通过提供一个不完整的开始ID。此外,我们可以限制迭代到一个给定的ID或时间安,通过提供一个结束ID或不完整ID而不是+。
XREAD命令同样可以迭代流。XREVRANGE命令可以反向迭代流,从较高的ID(或时间)到较低的ID(或时间)。
获取单个项目
如果你在查找一个XGET命令,你将会失望,因为XRANGE实际上就是从流中获取单个条目的方式。所有你需要做的,就是在XRANGE的参数中指定ID两次:
> XRANGE mystream 1526984818136-0 1526984818136-0
1) 1) 1526984818136-0
2) 1) "duration"
2) "1532"
3) "event-id"
4) "5"
5) "user-id"
6) "7782813"
有关流的其他信息
更多有关Redis流的信息,请参阅我们的Redis Streams介绍文档。
返回值
array-reply:该命令返回ID与指定范围匹配的条目。返回的条目是完整的,这意味着ID和所有组成条目的字段都将返回。此外,返回的条目及其字段和值的顺序与使用XADD添加它们的顺序完全一致。
例子
redis> XADD writers * name Virginia surname Woolf
"1539863591459-0"
redis> XADD writers * name Jane surname Austen
"1539863591460-0"
redis> XADD writers * name Toni surname Morris
"1539863591460-1"
redis> XADD writers * name Agatha surname Christie
"1539863591461-0"
redis> XADD writers * name Ngozi surname Adichie
"1539863591462-0"
redis> XLEN writers
(integer) 5
redis> XRANGE writers - + COUNT 2
1) 1) "1539863591459-0"
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) "1539863591460-0"
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
redis>
XREVRANGE key end start [COUNT count]
起始版本:5.0.0
时间复杂度:O(log(N)+M) N是流中的元素数,M是返回的元素数。如果M是常数(例如总是要求计数的前10个元素),你可以考虑它O(log(n))。
此命令与XRANGE完全相同,但显著的区别是以相反的顺序返回条目,并以相反的顺序获取开始-结束参数:在XREVRANGE中,你需要先指定结束ID,再指定开始ID,该命令就会从结束ID侧开始生成两个ID之间(或完全相同)的所有元素。
因此,例如,要获得从较高ID到较低ID的所有元素,可以使用:
XREVRANGE + -
类似于只获取添加到流中的最后一个元素,可以使用:
XREVRANGE + - COUNT 1
使用XREVRANGE迭代
与XRANGE一样,此命令可以用于迭代整个流的内容,但请注意,在这种情况中,下一个命令调用应该使用最后一个条目的ID,序列号减1。但如果序列号已经是0,则ID的时间部分应该减1,且序列号部分应该设置成最大可能的序列号,即18446744073709551615,或者可以完全省略,命令将自动假设它是这样一个数字(有关不完整ID的更多信息,请参阅XRANGE)。
例子:
> XREVRANGE writers + - COUNT 2
1) 1) 1526985723355-0
2) 1) "name"
2) "Ngozi"
3) "surname"
4) "Adichie"
2) 1) 1526985712947-0
2) 1) "name"
2) "Agatha"
3) "surname"
4) "Christie"
返回的最后ID是1526985712947-0,因为序列号已经是0,下一个ID我将不使用特殊ID+,而是1526985712946-18446744073709551615,或者只是18446744073709551615:
> XREVRANGE writers 1526985712946-18446744073709551615 - COUNT 2
1) 1) 1526985691746-0
2) 1) "name"
2) "Toni"
3) "surname"
4) "Morris"
2) 1) 1526985685298-0
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
所以直到迭代完成并且没有返回结果。更多有关迭代的信息,请参阅XRANGE页面。
返回值
array-reply:此命令返回ID在指定区间的条目,从较高的ID到较低的ID中匹配。 返回的条目是完整的,这意味着将返回ID及其组成的所有字段。 此外,返回的条目及其字段和值的顺序与以使用XADD添加的完全相同。
例子
redis> XADD writers * name Virginia surname Woolf
"1539863673862-0"
redis> XADD writers * name Jane surname Austen
"1539863673863-0"
redis> XADD writers * name Toni surname Morris
"1539863673865-0"
redis> XADD writers * name Agatha surname Christie
"1539863673866-0"
redis> XADD writers * name Ngozi surname Adichie
"1539863673867-0"
redis> XLEN writers
(integer) 5
redis> XREVRANGE writers + - COUNT 1
1) 1) "1539863673867-0"
2) 1) "name"
2) "Ngozi"
3) "surname"
4) "Adichie"
redis>
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key …] ID [ID …]
起始版本:5.0.0
时间复杂度:对于提到的每个流:O(log(N)+M),N是流中的元素数,M是返回的元素数。如果M是常数(例如总是要求计数的前10个元素),你可以考虑它O(log(n))。另一方面,XADD将支付O(N)时间,以便为流上被阻止的N个客户端提供服务,以获取新数据。
从一个或者多个流中读取数据,仅返回ID大于调用者报告的最后接收ID的条目。此命令有一个阻塞选项,用于等待可用的项目,类似于BRPOP或者BZPOPMIN等等。
请注意,在阅读本页之前,如果你不了解Stream,我们推荐先阅读我们的Redis Streams介绍。
非阻塞使用
如果未提供BLOCK选项,此命令是同步的,并可以认为与XRANGE有些相关:它将会返回流中的一系列项目,但与XRANGE相比它有两个基本差异(如果我们只考虑同步使用):
- 如果我们想要从多个键同时读取,则可以使用多个流调用此命令。这是
XREAD的一个关键特性,因为特别是在使用BLOCK进行阻塞时,能够通过单个连接监听多个键是一个至关重要的特性。 XRANGE返回一组ID中的项目,XREAD更适合用于从第一个条目(比我们到目前为止看到的任何其他条目都要大)开始使用流。因此,我们传递给XREAD的是,对于每个流,我们从该流接收的最后一个条目的ID。
例如,如果我有两个流mystream和writers,并且我希望同时从这两个流中读取数据(从它们的第一个元素开始), 我可以像下面这样调用XREAD:
请注意:我们在例子中使用了COUNT选项,因此对于每一个流,调用将返回每个流最多两个元素。
> XREAD COUNT 2 STREAMS mystream writers 0-0 0-0
1) 1) "mystream"
2) 1) 1) 1526984818136-0
2) 1) "duration"
2) "1532"
3) "event-id"
4) "5"
5) "user-id"
6) "7782813"
2) 1) 1526999352406-0
2) 1) "duration"
2) "812"
3) "event-id"
4) "9"
5) "user-id"
6) "388234"
2) 1) "writers"
2) 1) 1) 1526985676425-0
2) 1) "name"
2) "Virginia"
3) "surname"
4) "Woolf"
2) 1) 1526985685298-0
2) 1) "name"
2) "Jane"
3) "surname"
4) "Austen"
STREAMS选项是强制的,并且必须是最后一个选项,因为此选项以下列格式获取可变长度的参数:
STREAMS key_1 key_2 key_3 ... key_N ID_1 ID_2 ID_3 ... ID_N
所以我们以一组流的key开始,并在后面跟着所有关联的ID,表示我们从该流中获取的最后ID,以便调用仅为我们提供同一流中具有更大ID的条目。
例如,在上面的例子中,我们从流mystream中接收的最后项目的ID是1526999352406-0,而对于流writers,我们接收的最后项目的ID是1526985685298-0。
要继续迭代这两个流,我将调用:
> XREAD COUNT 2 STREAMS mystream writers 1526999352406-0 1526985685298-0
1) 1) "mystream"
2) 1) 1) 1526999626221-0
2) 1) "duration"
2) "911"
3) "event-id"
4) "7"
5) "user-id"
6) "9488232"
2) 1) "writers"
2) 1) 1) 1526985691746-0
2) 1) "name"
2) "Toni"
3) "surname"
4) "Morris"
2) 1) 1526985712947-0
2) 1) "name"
2) "Agatha"
3) "surname"
4) "Christie"
以此类推,最终,调用不再返回任何项目,只返回一个空数组,然后我们就知道我们的流中没有更多数据可以获取了(我们必须重试该操作,因此该命令也支持阻塞模式)。
不完全ID
使用不完整的ID是有效的,就像它对XRANGE一样有效。但是这里ID的序列号部分,如果缺少,将总是被解释为0,所以命令:
> XREAD COUNT 2 STREAMS mystream writers 0 0
完全等同于
> XREAD COUNT 2 STREAMS mystream writers 0-0 0-0
阻塞数据
在同步形式中,只要有更多可用项,该命令就可以获取新数据。但是,有些时候,我们不得不等待数据生产者使用XADD向我们消费的流中推送新条目。为了避免使用固定或自适应间隔获取数据,如果命令根据指定的流和ID不能返回任何数据,则该命令能够阻塞,并且一旦请求的key之一接收了数据,就会自动解除阻塞。
重要的是需要理解这个命令是扇形分发到所有正在等待相同ID范围的客户端,因此每个消费者都将得到一份数据副本,这与使用阻塞列表pop操作时发生的情况不同。
为了阻塞,使用BLOCK选项,以及我们希望在超时前阻塞的毫秒数。通常Redis阻塞命令的超时时间单位是秒,但此命令拥有一个毫秒超时时间,虽然通常服务器的超时时间精度大概在0.1秒左右。这可以在某些用例中阻塞更短的时间,并且如果服务器内部结构随着时间的推移而改善,它的超时精度可能也会有提升。
当传递了BLOCK选项,但是在传递的流中没有任何流有数据返回,那么该命令是同步执行的,就像没有指定BLOCK选项一样。
这是阻塞调用的例子,其中命令稍后将返回空回复(nil),因为超时时间已到但没有新数据到达:
> XREAD BLOCK 1000 STREAMS mystream 1526999626221-0
(nil)
特殊的ID$
有时阻塞我们只希望接收从我们阻塞的那一刻开始通过XADD添加到流的条目。在这种情况下,我们对已经添加条目的历史不感兴趣。对于这个用例,我们不得不检查流的最大元素ID,并使在XREAD命令行中使用这个ID。这不纯粹并且需要调用其他命令,因此可以使用特殊的ID$来表明我们只想要流中的新条目。
你应该仅在第一次调用XREAD时使用$,理解这一点非常重要。后面的ID你应该使用前一次报告的项目中最后一项的ID,否则你将会丢失所有添加到这中间的条目。
这是典型的XREAD调用(在想要仅消费新条目的消费者的第一次迭代)看起来的样子:
> XREAD BLOCK 5000 COUNT 100 STREAMS mystream $
一旦我们得到了一些回复,下一次调用会是像这样的:
> XREAD BLOCK 5000 COUNT 100 STREAMS mystream 1526999644174-3
依此类推。
如何在单个流上阻止多个客户端
列表或有序集合上的阻塞列表操作有pop行为。基本上,元素将从列表或有序集合中删除,以便返回给客户端。 在这种场景下,你希望项目以公平的方式被消费,具体取决于客户端在给定key上阻止的时刻到达。通常在这种用例中,Redis使用FIFO语义。
但请注意,对于流这不是问题:当服务客户端时,不会从流中删除条目,因此只要XADD命令向流提供数据,就会提供给每个等待的客户端。
返回值
array-reply:该命令返回一个结果数组:返回数组的每个元素都是一个由两个元素组成的数组(键名和为该键报告的条目)。报告的条目是完整的流条目,具有ID以及所有字段和值的列表。返回的条目及其字段和值的顺序与使用XADD添加它们的顺序完全一致。
当使用BLOCK时,超时时将返回一个空回复(nil)。
为了更多地了解流的整体行为和语义,强烈建议阅读Redis Streams介绍。
消费者组相关命令
总览
- XGROUP CREATE - 创建消费者组
- XREADGROUP GROUP - 读取消费者组中的消息
- XACK - 将消息标记为"已处理"
- XGROUP SETID - 为消费者组设置新的最后递送消息ID
- XGROUP DELCONSUMER - 删除消费者
- XGROUP DESTROY - 删除消费者组
- XPENDING - 显示待处理消息的相关信息
- XCLAIM - 转移消息的归属权
- XINFO - 查看流和消费者组的相关信息
- XINFO GROUPS - 打印消费者组的信息
- XINFO STREAM - 打印流信息
XGROUP [CREATE key groupname id-or- ] [ S E T I D k e y i d − o r − ] [SETID key id-or- ][SETIDkeyid−or−] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
起始版本:5.0.0
时间复杂度:O(log N) 对于所有子命令,N是流中注册的消费者组的数量,但销毁子命令除外,它需要额外的O(M)时间才能删除消费者组待定条目列表(PEL)中的M个条目。
该命令用于管理流数据结构关联的消费者组。使用XGROUP你可以:
- 创建与流关联的新消费者组。
- 销毁一个消费者组。
- 从消费者组中移除指定的消费者。
- 将消费者组的最后交付ID设置为其他内容。
要创建一个新的消费者组,请使用以下格式:
XGROUP CREATE mystream consumer-group-name $
最后一个参数是要考虑已传递的流中最后一项的ID。 在上面的例子中,我们使用了特殊的ID ‘$’(这表示:流中最后一项的ID)。 在这种情况下,从该消费者组获取数据的消费者只能看到到达流的新元素。
但如果你希望消费者组获取整个流的历史记录,使用0作为消费者组的开始ID:
XGROUP CREATE mystream consumer-group-name 0
当然,可以使用任何其他有效的ID。如果指定的消费者组已经存在,则该命令将返回-BUSYGROUP错误。 否则将执行该操作并返回OK。你可以为给定的流关联无限多的消费者组,没有硬性限制。
可以使用以下形式完全销毁消费者:
XGROUP DESTROY mystream some-consumer-group
即使存在活动的消费者和待处理消息,消费者组也将被销毁,因此请确保仅在真正需要时才调用此命令。
要仅从消费者组中移除给定的消费者,使用以下命令格式:
XGROUP DELCONSUMER mystream consumergrouo myconsumer123
每当某个命令提到新的消费者名称时,就会自动创建消费者组中的消费者。 但有时候删除旧的消费者可能会有用,因为他们已经不再使用。 以上格式的命令返回消费者在被删除之前所拥有的待处理消息数量。
最后,可以使用SETID子命令设置要传递的下一条消息。 通常情况下,在消费者创建时设置下一个ID,作为XGROUP CREATE的最后一个参数。 但是使用这种形式,可以在以后修改下一个ID,而无需再次删除和创建使用者组。 例如,如果你希望消费者组中的消费者重新处理流中的所有消息,你可能希望将其下一个ID设置为0:
XGROUP SETID mystream my-consumer-group 0
最后,如果您不记得语法,请使用HELP子命令:
XGROUP HELP
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] STREAMS key [key …] ID [ID …]
起始版本:5.0.0
时间复杂度:对于提到的每个流:O(log(N)+M),N是流中的元素数,M是返回的元素数。如果M是常数(例如总是要求计数的前10个元素),你可以考虑它O(log(n))。另一方面,XADD将支付O(N)时间,以便为流上被阻止的N个客户端提供服务,以获取新数据。
XREADGROUP命令是XREAD命令的特殊版本,支持消费者组。在阅读本页之前,你可能必须先理解XREAD命令才有意义。
此外,如果你是Stream新手,我们建议阅读我们的Redis Streams简介。 确保在介绍中理解消费者组的概念,以便遵循此命令的工作原理将更加简单。
快速了解消费者组
此命令与XREAD的区别是它支持消费者组。
如果没有消费者组,仅使用XREAD,所有客户端都将获得所有到达流的条目。相反,如果使用带有XREADGROUP的消费者组,则可以创建不同的客户端组来消费到达给定流的不同的部分。例如,如果流获得新的条目A,B和C,并且有两个消费者通过消费者组读取流,其中一个客户端将会得到例如,消息A和C,另外一个客户端得到消息B,等等,以此类推。
在消费者组中,给定的消费者(即从流中消费消息的客户端)必须使用唯一的消费者名称进行标识。名称只是一个字符串。
消费者组的保证之一是,给定的消费者只能看到发送给它的历史消息,因此每条消息只有一个所有者。然而,还有一个特殊的特性叫做消息认领,其允许其他消费者在某些消费者无法恢复时认领消息。为了实现这样的语义,消费者组要求消费者使用XACK命令显式确认已成功处理的消息。这是必要的,因为流将为每个消费者组跟踪哪个消费者正在处理什么消息。
这是如何理解您是否要使用消费者组:
- 如果你有一个流和多个客户端,并且你希望所有的客户端都获取到完整的信息,那么你不需要使用消费者组。
- 如果你有一个流和多个客户端,并且你希望在你的客户端上对流进行分区或共享,以便每个客户端都能获得一个到达流的消息的子集,那么你需要使用消费者组。
XREAD和XREADGROUP之间的差异
从语法的角度来看,这两个命令几乎是相同的,但是XREADGROUP需要一个特殊和强制的选项:
GROUP <group-name> <consumer-name>
组名只是关联到流的消费者组的名称。该组是使用XGROUP命令创建的。消费者名称是客户端用于在消费者组内标识自己的字符串。消费者会在第一次出现在消费者组内时被自动创建。不同的消费者应该选择不同的消费者名称。
当你使用XREADGROUP读取时,服务器将会记住某个给定的消息已经传递给你:消息会被存储在消费者组内的待处理条目列表(PEL)中,即已送达但尚未确认的消息ID列表。
客户端必须使用XACK确认消息处理,以便从待处理条目列表中删除待处理条目。可以使用XPENDING命令检查待处理条目列表。
使用XREADGROUP时在STREAMS选项中指定的ID可以是以下两种之一:
- 特殊ID
>,意味着消费者希望只接收从未发送给任何其他消费者的消息。这意思是说,请给我新的消息。 - 任意其他的ID,即0或任意其他有效ID或不完整的ID(只有毫秒时间部分),将具有返回发送命令的消费者的待处理条目的效果。所以,基本上如果ID不是
>,命令将让客户端访问它的待处理条目(已发送给它,但尚未确认的条目)。
就像XREAD,XREADGROUP命令也可以以阻塞的方式使用。在这方面没有区别。
当消息被传递给消费者时,会发生什么?
两件事:
- 如果消息从未被发送给其他消费者,也即,如果我们正在谈论新消息,则创建待处理条目列表(PEL)。
- 相反,如果该消息已经发送给该消费者,并且它只是再次重新获取相同的消息,那么最后送达时间会被更新为当前时间,并且送达次数会加1。你可以使用
XPENDING命令访问这些消息属性。
用法示例
通常,你使用这样的命令来获取新消息并处理它们。在伪代码中:
WHILE true
entries = XREADGROUP $GroupName $ConsumerName BLOCK 2000 COUNT 10 STREAMS mystream >
if entries == nil
puts "Timeout... try again"
CONTINUE
end
FOREACH entries AS stream_entries
FOREACH stream_entries as message
process_message(message.id,message.fields)
# ACK the message as processed
XACK mystream $GroupName message.id
END
END
END
通过这种方式,例子中的消费者代码将会只获取新消息,处理它们,以及通过XACK确认它们。 但是以上案例的代码是不完整的,因为它没有处理崩溃后的恢复事宜。如果我们在处理消息的过程中崩溃了, 则我们的消息将继续保留在待处理条目列表中,因此我们可以通过给XREADGROUP初始ID为0并执行相同的循环来访问我们的消息历史。 一旦提供的ID为0并且回复是一组空的消息,我们就知道我们已经处理并确认完了所有的待处理消息: 我们可以开始使用>作为ID,以便获取新消息并重新加入正在处理新消息的消费者。
要查看命令实际回复的方式,请参阅XREAD命令页面。
XACK key group ID [ID …]
起始版本:5.0.0
时间复杂度:O(log N) 对于处理的每个消息ID。
XACK命令用于从流的消费者组的待处理条目列表(简称PEL)中删除一条或多条消息。 当一条消息交付到某个消费者时,它将被存储在PEL中等待处理, 这通常出现在作为调用XREADGROUP命令的副作用,或者一个消费者通过调用XCLAIM命令接管消息的时候。 待处理消息被交付到某些消费者,但是服务器尚不确定它是否至少被处理了一次。 因此对新调用XREADGROUP来获取消费者的消息历史记录(比如用0作为ID)将返回此类消息。 类似地,待处理的消息将由检查PEL的XPENDING命令列出。
一旦消费者成功地处理完一条消息,它应该调用XACK,这样这个消息就不会被再次处理, 且作为一个副作用,关于此消息的PEL条目也会被清除,从Redis服务器释放内存。
返回值
integer-reply:该命令返回成功确认的消息数。 某些消息ID可能不再是PEL的一部分(例如因为它们已经被确认), 而且XACK不会把他们算到成功确认的数量中。
redis> XACK mystream mygroup 1526569495631-0
ERR Unknown or disabled command 'XACK'
redis>
XPENDING key group [start end count] [consumer]
起始版本:5.0.0
时间复杂度:O(log(N)+M) N是消费者组待定条目列表中的元素数,M是返回的元素数。当命令仅返回摘要时,假设使用者列表很小,它将在O(1)时间内运行,否则需要额外的O(N)时间来迭代每个使用者。
通过消费者组从流中获取数据,而不是确认这些数据,具有创建待处理条目的效果。这在XREADGROUP命令中已有详尽的说明,在我们的Redis Streams介绍中更好。XACK命令会立即从待处理条目列表(PEL)中移除待处理条目,因为一旦消息被成功处理,消费者组就不再需要跟踪它并记住消息的当前所有者。
XPENDING命令是检查待处理消息列表的接口,因此它是一个非常重要的命令,用于观察和了解消费者组正在发生的事情:哪些客户端是活跃的,哪些消息在等待消费,或者查看是否有空闲的消息。此外,该命令与XCLAIM一起使用,用于实现长时间故障的消费者的恢复,因此不处理某些消息:不同的消费者可以认领该消息并继续处理。这在Redis Streams介绍和XCLAIM命令页面中有更好的解释,这里不再介绍。
XPENDING命令格式总结
当只使用键名和消费者组名调用XPENDING时,其只输出有关给定消费组的待处理消息的概要。在以下例子中,我们创建一个使用过的消费者组,并通过使用XREADGROUP从组中读取来立即创建待处理消息。
> XGROUP CREATE mystream group55 0-0
OK
> XREADGROUP GROUP group55 consumer-123 COUNT 1 STREAMS mystream >
1) 1) "mystream"
2) 1) 1) 1526984818136-0
2) 1) "duration"
2) "1532"
3) "event-id"
4) "5"
5) "user-id"
6) "7782813"
我们希望消费者组group55的待处理条目列表立即拥有一条消息:消费者consumer-123获取了一条消息,且没有确认消息。简单的XPENDING形式会给我们提供以下信息:
> XPENDING mystream group55
1) (integer) 1
2) 1526984818136-0
3) 1526984818136-0
4) 1) 1) "consumer-123"
2) "1"
在这种形式中,此命令输出该消费者组的待处理消息的数量(即1),然后是待处理消息的最小和最大ID,然后列出消费者组中每一个至少一条待处理消息的消费者,以及他的待处理消息数量。
这是一个很好的概述,但有时候我们对细节感兴趣。为了查看具有更多相关信息的所有待处理消息,我们还需要传递一系列ID,与我们使用XRANGE时类似,以及一个非可选的count参数,限制每一次调用返回的消息数量:
> XPENDING mystream group55 - + 10
1) 1) 1526984818136-0
2) "consumer-123"
3) (integer) 196415
4) (integer) 1
在扩展的形式中,我们不再看到概要信息,而是在待处理消息列表中有每一条消息的详细信息。对于每条消息,返回四个属性:
- 消息的ID。
- 获取并仍然要确认消息的消费者名称,我们称之为消息的当前所有者。
- 自上次将此消息传递给该消费者以来,经过的毫秒数。
- 该消息被传递的次数。
交付计数器,即数组中的第四个元素,当其他消费者使用XCLAIM声明消息时,或当通过XREADGROUP再次传递消息时,当访问消费者组中的消费者历史时(更多信息请参阅XREADGROUP页面)递增。
最后,还可以向该命令传递一个额外的参数,以便查看具有特定所有者的消息:
> XPENDING mystream group55 - + 10 consumer-123
但在上面的例子中,输出将是相同的,因为我们只有一个消费者有待处理消息。然而,我们需要记住重要的一点是,即使来自许多消费者的许多待处理消息,由特定消费者过滤的这种操作效率也不高:我们在全局和每个消费者都有待处理条目数据结构,所以我们可以非常高效地显示单个消费者的待处理消息。
返回值
array-reply:该命令以不同的格式返回数据,具体取决于它的调用方式,如本文前面所述。但是,返回值始终是一组项目。
XCLAIM key group consumer min-idle-time ID [ID …] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] [FORCE] [JUSTID]
起始版本:5.0.0
时间复杂度:O(log N) N是消费者组的PEL中的消息数。
在流的消费者组上下文中,此命令改变待处理消息的所有权, 因此新的所有者是在命令参数中指定的消费者。通常是这样的:
- 假设有一个具有关联消费者组的流。
- 某个消费者A在消费者组的上下文中通过
XREADGROUP从流中读取一条消息。 - 作为读取消息的副作用,消费者组的待处理条目列表(PEL)中创建了一个待处理消息条目:这意味着这条消息已传递给给定的消费者,但是尚未通过
XACK确认。 - 突然这个消费者出现故障,且永远无法恢复。
- 其他消费者可以使用
XPENDING检查已经过时很长时间的待处理消息列表,为了继续处理这些消息,他们使用XCLAIM来获得消息的所有权,并继续处理。
Stream介绍文档中清楚的解释了这种动态。
请注意,消息只有在其空闲时间大于我们通过XCLAIM指定的空闲时间的时才会被认领。 因为作为一个副作用,XCLAIM也会重置消息的空闲时间(因为这是处理消息的一次新尝试), 两个试图同时认领消息的消费者将永远不会成功:只有一个消费者能成功认领消息。 这避免了我们用微不足道的方式多次处理给定的消息(虽然一般情况下无法完全避免多次处理)。
此外,作为副作用,XCLAIM会增加消息的尝试交付次数。通过这种方式, 由于某些原因而无法处理的消息(例如因为消费者在尝试处理期间崩溃),将开始具有更大的计数器, 并可以在系统内部被检测到。
命令选项
该命令有多个选项,但是大部分主要用于内部使用,以便将XCLAIM或其他命令的结果传递到AOF文件, 以及传递相同的结果到从节点,并且不太可能对普通用户有用:
IDLE <ms>: 设置消息的空闲时间(自最后一次交付到目前的时间)。如果没有指定IDLE,则假设IDLE值为0,即时间计数被重置,因为消息现在有新的所有者来尝试处理它。TIME <ms-unix-time>: 这个命令与IDLE相同,但它不是设置相对的毫秒数,而是将空闲时间设置为一个指定的Unix时间(以毫秒为单位)。这对于重写生成XCLAIM命令的AOF文件很有用。RETRYCOUNT <count>: 将重试计数器设置为指定的值。这个计数器在每一次消息被交付的时候递增。通常,XCLAIM不会更改这个计数器,它只在调用XPENDING命令时提供给客户端:这样客户端可以检测到异常,例如在大量传递尝试后由于某种原因从未处理过的消息。FORCE: 在待处理条目列表(PEL)中创建待处理消息条目,即使某些指定的ID尚未在分配给不同客户端的待处理条目列表(PEL)中。但是消息必须存在于流中,否则不存在的消息ID将会被忽略。JUSTID: 只返回成功认领的消息ID数组,不返回实际的消息。
返回值
array-reply:此命令以XRANGE相同的格式返回所有成功认领的消息。但如果指定了JUSTID选项, 则只返回消息的ID,不包括实际的消息。
例子
> XCLAIM mystream mygroup Alice 3600000 1526569498055-0
1) 1) 1526569498055-0
2) 1) "message"
2) "orange"
在上面的例子中,我们认领ID为1526569498055-0的消息,仅当消息闲置至少一小时且没有原始消费者或其他消费者进行推进(确认或认领它)时,并将所有权分配给消费者Alice。
XINFO [CONSUMERS key groupname] key key [HELP]
起始版本:5.0.0
时间复杂度:O(N) N是子命令使用者和组返回的项目数。STREAM子命令是O(logn),N是流中的项数。
这是一个内省命令,用于检索关于流和关联的消费者组的不同的信息。有三种可能的形式:
XINFO STREAM <key>
在这种形式下,此命令返回有关存储在特定键的流的一般信息。
> XINFO STREAM mystream
1) length
2) (integer) 2
3) radix-tree-keys
4) (integer) 1
5) radix-tree-nodes
6) (integer) 2
7) groups
8) (integer) 2
9) last-generated-id
10) 1538385846314-0
11) first-entry
12) 1) 1538385820729-0
2) 1) "foo"
2) "bar"
13) last-entry
14) 1) 1538385846314-0
2) 1) "field"
2) "value"
在以上例子中,你可以看到报告的信息是流的元素的数量,有关表示流的基数树的详细信息(主要用于优化和调试任务),与流关联的消费者组的数量,最后生成的ID(某些条目被删除时,此ID可能与最后一个条目的ID不同),最后显示了流中完整的第一个和最后一个条目,以便了解流的内容是什么。
XINFO GROUPS <key>
在这种形式中,我们只获得与流关联的所有消费者组的输出:
> XINFO GROUPS mystream
1) 1) name
2) "mygroup"
3) consumers
4) (integer) 2
5) pending
6) (integer) 2
2) 1) name
2) "some-other-group"
3) consumers
4) (integer) 1
5) pending
6) (integer) 0
对每一个列出的消费者组,该命令还显示该组中已知的消费者数量,以及该组中的待处理消息(已传递但尚未确认)数量。
XINFO CONSUMERS <key> <group>
最后,还可以取得指定消费者组中的消费者列表:
> XINFO CONSUMERS mystream mygroup
1) 1) name
2) "Alice"
3) pending
4) (integer) 1
5) idle
6) (integer) 9104628
2) 1) name
2) "Bob"
3) pending
4) (integer) 1
5) idle
6) (integer) 83841983
我们可以看到这个消费者的空闲毫秒时间(最后一个字段)以及消费者名称和待处理消息数量。
请注意,你不应该依赖字段的确切位置,也不应该依赖字段的数量,因为将来可能会增加新的字段。因此,表现良好的客户端应该获取整个列表,并将其报告给用户,例如,作为字典数据结构。低级客户端(例如C客户端,其中项目可能以线性数组报告)应该注明顺序是不确定的。
最后,通过使用HELP子命令,可以从命令获得帮助,以防用户无法记住确切的语法:
> XINFO HELP
1) XINFO <subcommand> arg arg ... arg. Subcommands are:
2) CONSUMERS <key> <groupname> -- Show consumer groups of group <groupname>.
3) GROUPS <key> -- Show the stream consumer groups.
4) STREAM <key> -- Show information about the stream.
5) HELP
参考链接:
Redis的持久化
Redis 提供了不同级别的持久化方式:
- RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储.
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.
- 如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
- 你也可以同时开启两种持久化方式, 在这种情况下, 当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
RDB的优点
- RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集.
- RDB是一个紧凑的单一文件,很方便传送到另一个远端数据中心或者亚马逊的S3(可能加密),非常适用于灾难恢复.
- RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
- 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
RDB的缺点
- 如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适合你.虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据.
- RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求.如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度.
RDB相关配置
#######SNAPSHOTTING#######
dir /usr/local/redis/db # 数据库工作目录,db文件保存的位置
dbfilename dump.rdb # 数据库文件名
# save <seconds> <changes> 可以定义多个
save 900 1 # 在900s之前有1个key发生更改则保存一次
save 300 10 # 在300s之前有10个key发生更改则保存一次
save 60 10000 # 在60s之前有10000个key发生更改则保存一次
stop-writes-on-bgsave-error yes # 在写入文件的时候报错则停止保存 推荐yes 否则可能会出现数据不一致
rdbcompression yes # 是否开启压缩 使用LZF的压缩方式 若想要节省cpu消耗则可以选择关闭 但是生成的文件可能比较大
rdbchecksum yes # 是否开启检查rdb文件 在保存和加载rdb文件时会有10%的性能损耗
AOF的优点
- 使用AOF 会让你的Redis更加耐久: 你可以使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据.
- AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也也可使用redis-check-aof工具修复这些问题.
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF的缺点
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
AOF相关配置
#########APPEND ONLY MODE#########
# 默认使用的是rdb模式
appendonly yes # 是否开启aof备份 默认是no
appendfilename "appendonly.aof" # 生成的aof文件的文件名
appendfsync everysec # 备份策略 默认是1s备份一次 还有always(总是,最慢最安全)和 no(不备份,最快最不安全)可选
no-appendfsync-on-rewrite no # 重写的时候不要做同步 推荐no
# 触发重写的条件 当新的aof文件超过上一次aof文件的100% 并且大于64m时将会开始重写
auto-aof-rewrite-percentage 100 # 设置重写比例
auto-aof-rewrite-min-size 64mb # 设置最小重写的大小 默认是64mb 按需修改
如何选择使用哪种持久化方式?
一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
Note: 因为以上提到的种种原因, 未来我们可能会将 AOF 和 RDB 整合成单个持久化模型。 (这是一个长期计划。) 接下来的几个小节将介绍 RDB 和 AOF 的更多细节。
快照
在默认情况下, Redis 将数据库快照保存在名字为 dump.rdb的二进制文件中。你可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动保存一次数据集。你也可以通过调用 SAVE或者 BGSAVE , 手动让 Redis 进行数据集保存操作。
比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 1000 个键被改动”这一条件时, 自动保存一次数据集:
save 60 1000
这种持久化方式被称为快照 snapshotting.
工作方式
当 Redis 需要保存 dump.rdb 文件时, 服务器执行以下操作:
- Redis 调用forks. 同时拥有父进程和子进程。
- 子进程将数据集写入到一个临时 RDB 文件中。
- 当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益。
只追加操作的文件(Append-only file,AOF)
快照功能并不是非常耐久(dura ble): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。 从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化。
你可以在配置文件中打开AOF方式:
appendonly yes
从现在开始, 每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到 AOF 文件的末尾。这样的话, 当 Redis 重新启时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
日志重写
因为 AOF 的运作方式是不断地将命令追加到文件的末尾, 所以随着写入命令的不断增加, AOF 文件的体积也会变得越来越大。举个例子, 如果你对一个计数器调用了 100 次 INCR , 那么仅仅是为了保存这个计数器的当前值, AOF 文件就需要使用 100 条记录(entry)。然而在实际上, 只使用一条 SET 命令已经足以保存计数器的当前值了, 其余 99 条记录实际上都是多余的。
为了处理这种情况, Redis 支持一种有趣的特性: 可以在不打断服务客户端的情况下, 对 AOF 文件进行重建(rebuild)。执行 BGREWRITEAOF 命令, Redis 将生成一个新的 AOF 文件, 这个文件包含重建当前数据集所需的最少命令。Redis 2.2 需要自己手动执行 BGREWRITEAOF 命令; Redis 2.4 则可以自动触发 AOF 重写, 具体信息请查看 2.4 的示例配置文件。
AOF有多耐用?
你可以配置 Redis 多久才将数据 fsync 到磁盘一次。有三种方式:
- 每次有新命令追加到 AOF 文件时就执行一次 fsync :非常慢,也非常安全
- 每秒 fsync 一次:足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据。
- 从不 fsync :将数据交给操作系统来处理。更快,也更不安全的选择。
- 推荐(并且也是默认)的措施为每秒 fsync 一次, 这种 fsync 策略可以兼顾速度和安全性。
如果AOF文件损坏了怎么办?
服务器可能在程序正在对 AOF 文件进行写入时停机, 如果停机造成了 AOF 文件出错(corrupt), 那么 Redis 在重启时会拒绝载入这个 AOF 文件, 从而确保数据的一致性不会被破坏。当发生这种情况时, 可以用以下方法来修复出错的 AOF 文件:
为现有的 AOF 文件创建一个备份。
使用 Redis 附带的 redis-check-aof 程序,对原来的 AOF 文件进行修复:
$ redis-check-aof –fix
(可选)使用 diff -u 对比修复后的 AOF 文件和原始 AOF 文件的备份,查看两个文件之间的不同之处。
重启 Redis 服务器,等待服务器载入修复后的 AOF 文件,并进行数据恢复。
工作原理
AOF 重写和 RDB 创建快照一样,都巧妙地利用了写时复制机制:
- Redis 执行 fork() ,现在同时拥有父进程和子进程。
- 子进程开始将新 AOF 文件的内容写入到临时文件。
- 对于所有新执行的写入命令,父进程一边将它们累积到一个内存缓存中,一边将这些改动追加到现有 AOF 文件的末尾,这样样即使在重写的中途发生停机,现有的 AOF 文件也还是安全的。
- 当子进程完成重写工作时,它给父进程发送一个信号,父进程在接收到信号之后,将内存缓存中的所有数据追加到新 AOF 文件的末尾。
- 搞定!现在 Redis 原子地用新文件替换旧文件,之后所有命令都会直接追加到新 AOF 文件的末尾。
怎样从RDB方式切换为AOF方式
在 Redis 2.2 或以上版本,可以在不重启的情况下,从 RDB 切换到 AOF :
- 为最新的 dump.rdb 文件创建一个备份。
- 将备份放到一个安全的地方。
- 执行以下两条命令:
- redis-cli config set appendonly yes
- redis-cli config set save “”
- 确保写命令会被正确地追加到 AOF 文件的末尾。
- 执行的第一条命令开启了 AOF 功能: Redis 会阻塞直到初始 AOF 文件创建完成为止, 之后 Redis 会继续处理命令请求, 并开始将写入命令追加到 AOF 文件末尾。
执行的第二条命令用于关闭 RDB 功能。 这一步是可选的, 如果你愿意的话, 也可以同时使用 RDB 和 AOF 这两种持久化功能。
重要:别忘了在 redis.conf 中打开 AOF 功能! 否则的话, 服务器重启之后, 之前通过 CONFIG SET 设置的配置就会被遗忘, 程序会按原来的配置来启动服务器。
AOF和RDB之间的相互作用
在版本号大于等于 2.4 的 Redis 中, BGSAVE 执行的过程中, 不可以执行 BGREWRITEAOF 。 反过来说, 在 BGREWRITEAOF 执行的过程中, 也不可以执行 BGSAVE。这可以防止两个 Redis 后台进程同时对磁盘进行大量的 I/O 操作。
如果 BGSAVE 正在执行, 并且用户显示地调用 BGREWRITEAOF 命令, 那么服务器将向用户回复一个 OK 状态, 并告知用户, BGREWRITEAOF 已经被预定执行: 一旦 BGSAVE 执行完毕, BGREWRITEAOF 就会正式开始。 当 Redis 启动时, 如果 RDB 持久化和 AOF 持久化都被打开了, 那么程序会优先使用 AOF 文件来恢复数据集, 因为 AOF 文件所保存的数据通常是最完整的。
备份redis数据
在阅读这个小节前, 请牢记下面这句话: 确保你的数据由完整的备份. 磁盘故障, 节点失效, 诸如此类的问题都可能让你的数据消失不见, 不进行备份是非常危险的。
Redis 对于数据备份是非常友好的, 因为你可以在服务器运行的时候对 RDB 文件进行复制: RDB 文件一旦被创建, 就不会进行任何修改。 当服务器要创建一个新的 RDB 文件时, 它先将文件的内容保存在一个临时文件里面, 当临时文件写入完毕时, 程序才使用 rename(2) 原子地用临时文件替换原来的 RDB 文件。
这也就是说, 无论何时, 复制 RDB 文件都是绝对安全的。
- 创建一个定期任务(cron job), 每小时将一个 RDB 文件备份到一个文件夹, 并且每天将一个 RDB 文件备份到另一个文件夹。
- 确保快照的备份都带有相应的日期和时间信息, 每次执行定期任务脚本时, 使用 find 命令来删除过期的快照: 比如说, 你可以保留最近 48 小时内的每小时快照, 还可以保留最近一两个月的每日快照。
- 至少每天一次, 将 RDB 备份到你的数据中心之外, 或者至少是备份到你运行 Redis 服务器的物理机器之外。
容灾备份
Redis 的容灾备份基本上就是对数据进行备份, 并将这些备份传送到多个不同的外部数据中心。容灾备份可以在 Redis 运行并产生快照的主数据中心发生严重的问题时, 仍然让数据处于安全状态。
因为很多 Redis 用户都是创业者, 他们没有大把大把的钱可以浪费, 所以下面介绍的都是一些实用又便宜的容灾备份方法:
- Amazon S3 ,以及其他类似 S3 的服务,是一个构建灾难备份系统的好地方。 最简单的方法就是将你的每小时或者每日 RDB 备份加密并传送到 S3 。 对数据的加密可以通过 gpg -c 命令来完成(对称加密模式)。 记得把你的密码放到几个不同的、安全的地方去(比如你可以把密码复制给你组织里最重要的人物)。 同时使用多个储存服务来保存数据文件,可以提升数据的安全性。
- 传送快照可以使用 SCP 来完成(SSH 的组件)。 以下是简单并且安全的传送方法: 买一个离你的数据中心非常远的 VPS , 装上 SSH , 创建一个无口令的 SSH 客户端 key , 并将这个 key 添加到 VPS 的 authorized_keys 文件中, 这样就可以向这个 VPS 传送快照备份文件了。 为了达到最好的数据安全性,至少要从两个不同的提供商那里各购买一个 VPS 来进行数据容灾备份。
- 需要注意的是, 这类容灾系统如果没有小心地进行处理的话, 是很容易失效的。最低限度下, 你应该在文件传送完毕之后, 检查所传送备份文件的体积和原始快照文件的体积是否相同。 如果你使用的是 VPS , 那么还可以通过比对文件的 SHA1 校验和来确认文件是否传送完整。
另外, 你还需要一个独立的警报系统, 让它在负责传送备份文件的传送器(transfer)失灵时通知你。
Redis主从架构
Redis单示例部署会有性能瓶颈,可以使用主从模式横向扩展来实现Redis的高可用,提高性能上限,企业中使用较多的是一主二从。
主从库之间采用的是「读写分离」的方式。
- 读操作:主库、从库都可以接收;
- 写操作:首先到主库执行,然后,主库将写操作同步给从库。
假如从库数量较多,则会出现两个问题
- 主库忙于 fork 子进程生成 RDB 文件,进行数据全量同步,fork 这个操作会阻塞主线程处理正常请求,从而导致主库响应应用程序的请求速度变慢。
- 生成 RDB 文件 需要耗费主服务器大量的CPU,内存和磁盘I/O资源。传输 RDB 文件也会占用主库的网络带宽,并对主服务器响应命令请求的时间产生影响。
解决方案为主-从-从模式:我们在部署主从集群的时候,可以手动选择一个从库(比如选择内存资源配置较高的从库),用于级联其他的从库。 然后,我们可以再选择一些从库(例如三分之一的从库),让它们和刚才所选的从库,建立起主从关系。
这样一来,这些从库就会知道,在进行同步时,不用再和主库进行交互了,只要和级联的从库进行写操作同步就行了,这就可以减轻主库上的压力,如下图所示:
主从模式同步数据流程
主从库间建立连接、协商同步的过程,主要是为全量复制做准备
PSYNC <runid> <offset>具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。 psync 命令包含了主库的 runID 和复制进度 offset 两个参数。
psync 是 Redis 2.8 版本提供的命令,用于解决 sync 「断线后重复制」的低效问题。
runID:是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。 当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。
offset:复制偏移量,此时设为 -1,表示第一次复制。
PSYNC ? -1 # 表示全量复制。主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:「主库 runID」 和主库目前的「复制进度 offset」,返回给从库。 从库收到响应后,会记录下这两个参数,在下一次发送psync 命令时使用。
需要注意的是,FULLRESYNC 响应表示「第一次复制采用的全量复制」,也就是说,主库会把当前所有的数据都复制给从库。如果主服务器返回的是 +CONTINUE 则表示需要进行「部分同步」。
主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载
主库收到完整重同步请求后,会在后台执行
bgsave命令,生成 RDB 文件,并使用一个「缓冲区:replication buffer」记录「从现在开始所有的写命令」。当
bgsave命令执行完毕,主服务会将 RDB 文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。为什么要有清空的动作?
这是因为从库在通过slaveof命令开始和主库同步前,可能保存了其他数据。为了避免之前数据的影响,从库需要先把当前数据库清空。在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。 否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。 为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer ( 复制缓冲区),记录 RDB 文件生成后收到的所有写操作。
主库会把第二阶段执行过程中新收到的写命令,再发送给从库
当主库完成 RDB 文件发送后,就会把此时
replication buffer中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。PSYN2.0
PSYN2.0 是 Redis 4.0 的 其中一个新特性。相比原来的 PSYN 功能,最大的变化就是支持两种场景下的部分重同步。- slave 节点提升为 master 节点后,其他 slave 节点可以从新提升的 master 进行部分重同步;
- 另外一个场景就是slave重启后,可以进行部分重同步。
一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库, 这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
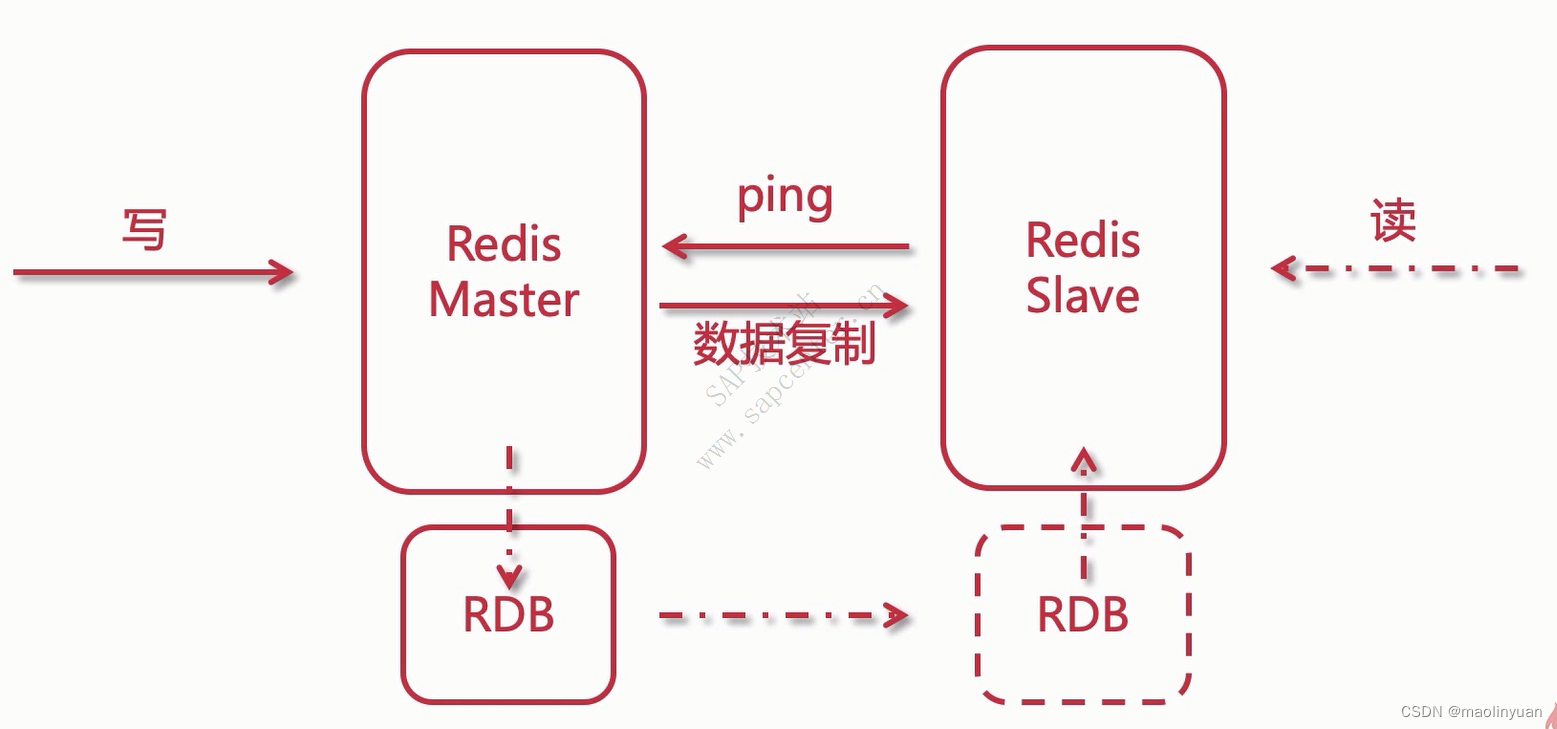
但不可忽视的是,这个过程中存在着风险点,最常见的就是网络断连或阻塞。如果网络断连,主从库之间就无法进行命令传播了, 从库的数据自然也就没办法和主库保持一致了,客户端就可能从从库读到旧数据。
参考链接:
Redis主从模式搭建
虚拟机或服务器准备
- 主节点:192.168.1.191
- 从节点:192.168.1.192,192.168.1.193
主从配置并演示
启动3台虚拟机的Redis,使用redis-cli客户端命令连接到redis-server,使用命令查看三台Redis主从配置信息
info replication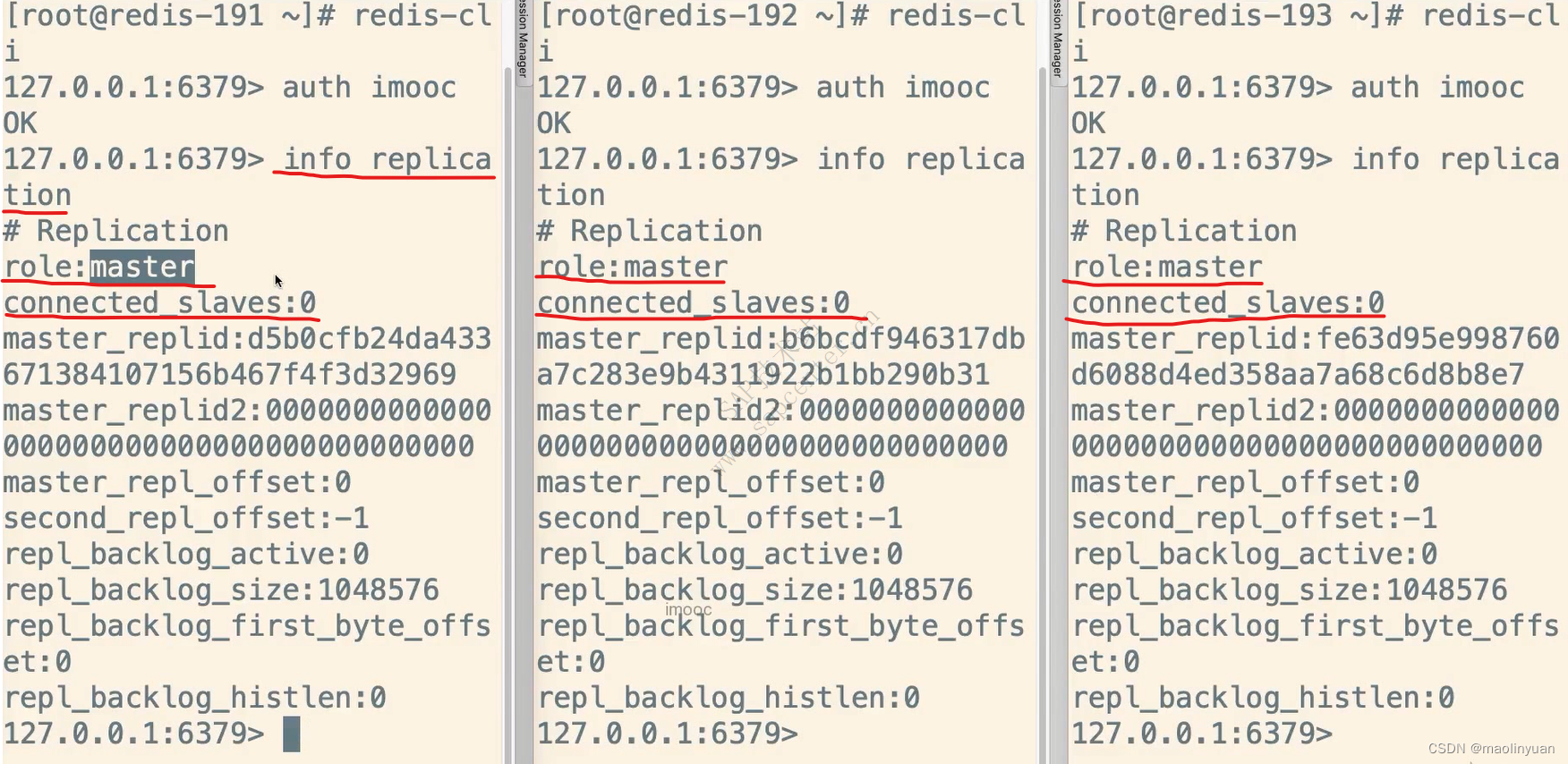
role redis当前角色,默认都是master
connected_slaves 连接到的从节点数量
Redis启动后默认就是主节点,所以主要是修改从节点的配置文件,找到从节点192配置文件并打开
vim /usr/local/redis/redis.conf找到配置文件中REPLICATION配置部分,修改对应配置

#######REPLICATION####### # replicaof <masterip> <masterport> 配置master节点的ip和端口 replicaof 192.168.1.191 6379 # masterauth <master-password> 配置主节点认证密码 masterauth imooc # replica-read-only yes 从节点默认只能读取数据,这个配置可以做到主从的读写分离 replica-read-only yes(可以不做)删除从节点的持久化文件
cd /usr/local/redis/db # 进入从节点持久化文件保存的目录 rm -rf *.aof *.rdb # 删除文件重启当前配置的从节点Redis
# 这里使用脚本启停(若没有配置脚本可以使用kill命令 然后再找到redis-server 启动) /etc/init.d/redis_init_script stop # 停止 /etc/init.d/redis_init_script start # 启动查看从节点持久化文件目录中的内容,发现又生成的对应的文件,此文件是通过主从同步同步过来的文件
ls -al /usr/local/redis/db登录redis-server查看里面的内容,可以看到其内容和主节点一模一样
redis-cli AUTH imooc keys *使用命令查看子节点redis-server属性信息
info replication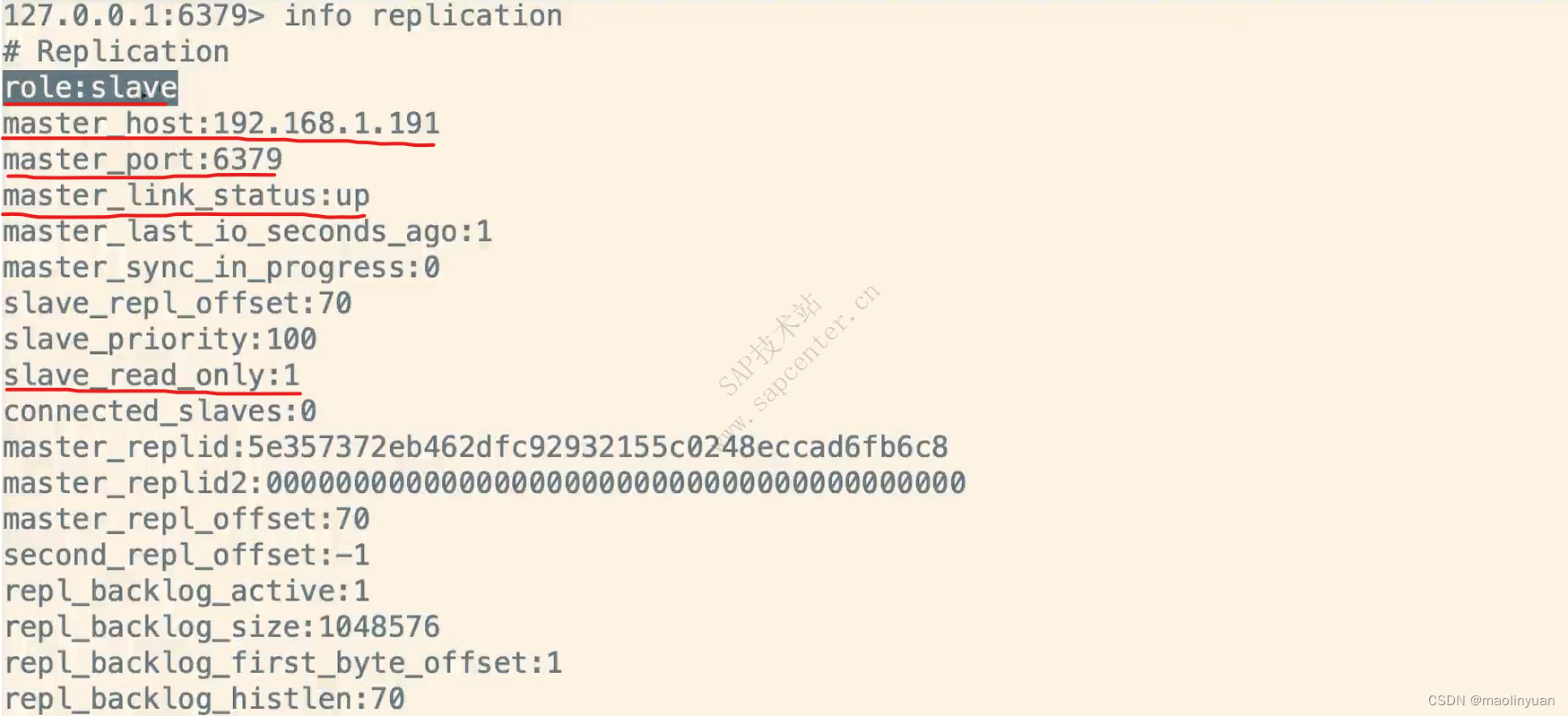
master_host 主节点地址
master_port 主节点端口
master_link_status 主节点状态
slave_read_only 是不是只能读取数据
查看主节点属性信息,发现从节点数量已经增加,而且还有从节点的必要信息
info replication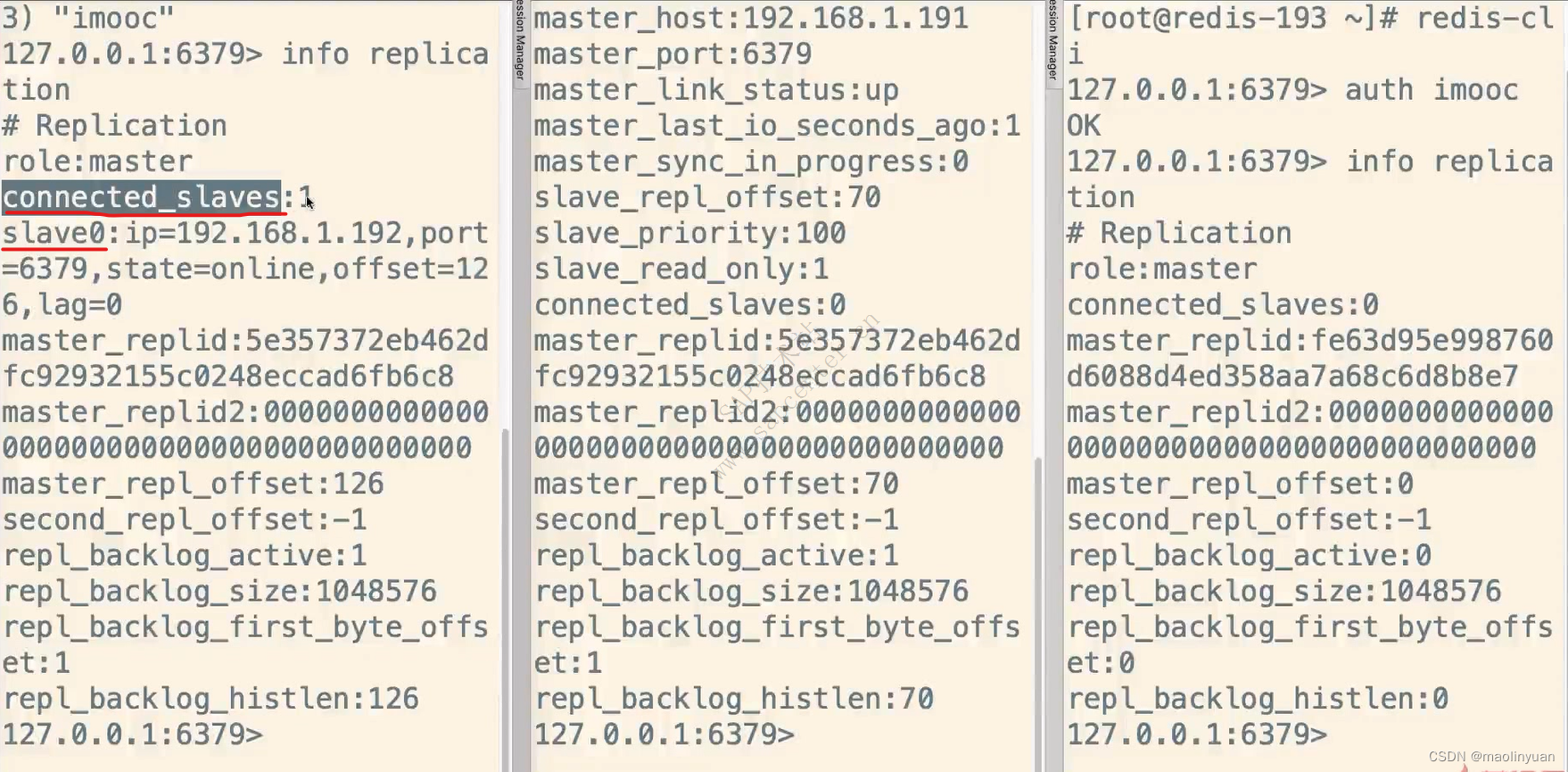
在主节点设置新的key-value信息,再在从节点查看,可以发现通过主从同步已经把最新的数据同步过来了
尝试在从节点写入数据,将会报错,所以slave只能做读取操作不能做写操作
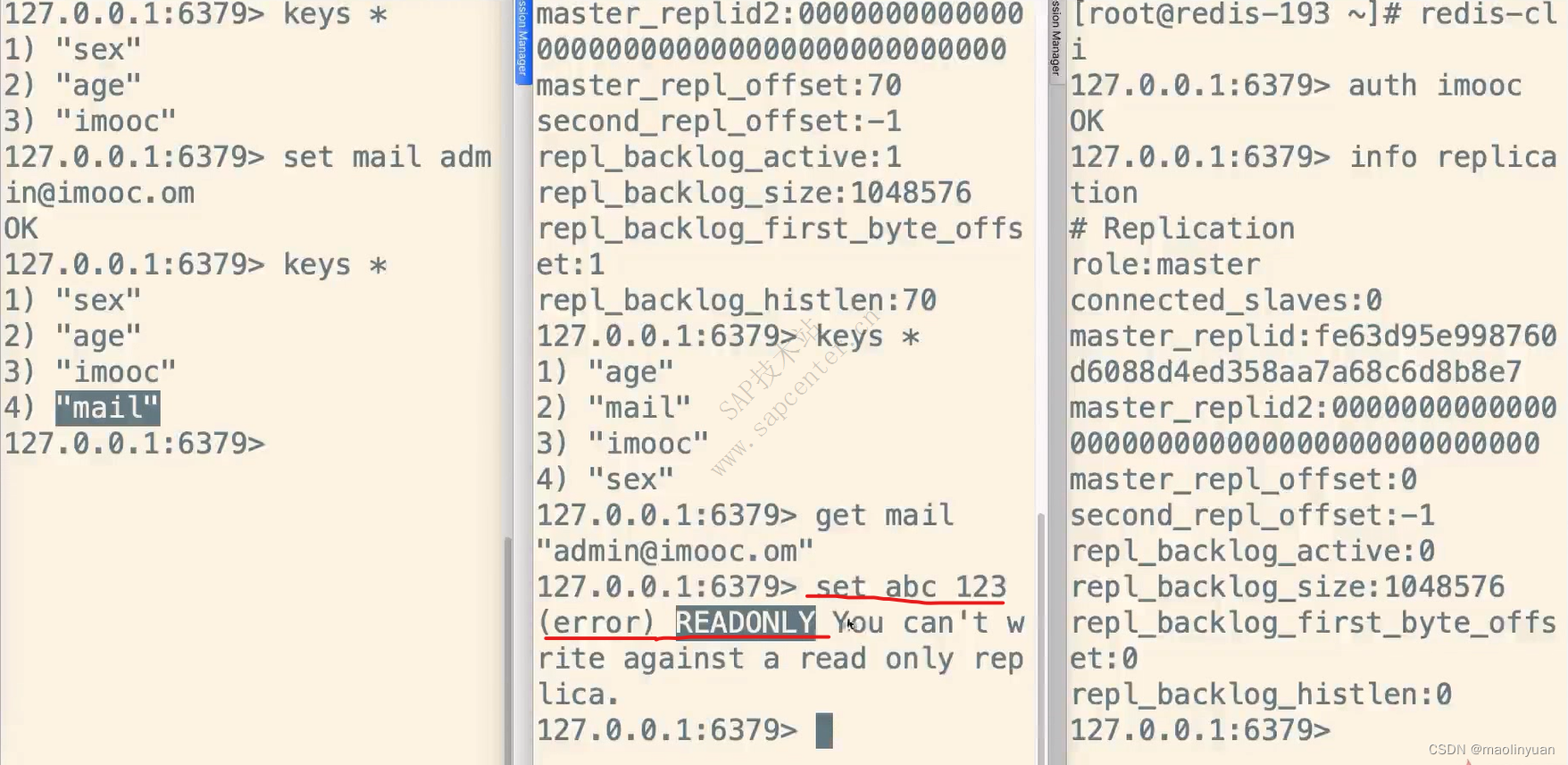
修改第二台从节点193配置
vim /usr/local/redis/redis.conf # 配置相同内容 replicaof 192.168.1.191 6379 masterauth imooc replica-read-only yes # 重启redis-server /etc/init.d/redis_init_script stop /etc/init.d/redis_init_script start使用此节点的redis-cli工具连接到redis-server,并查看主从属性
info replication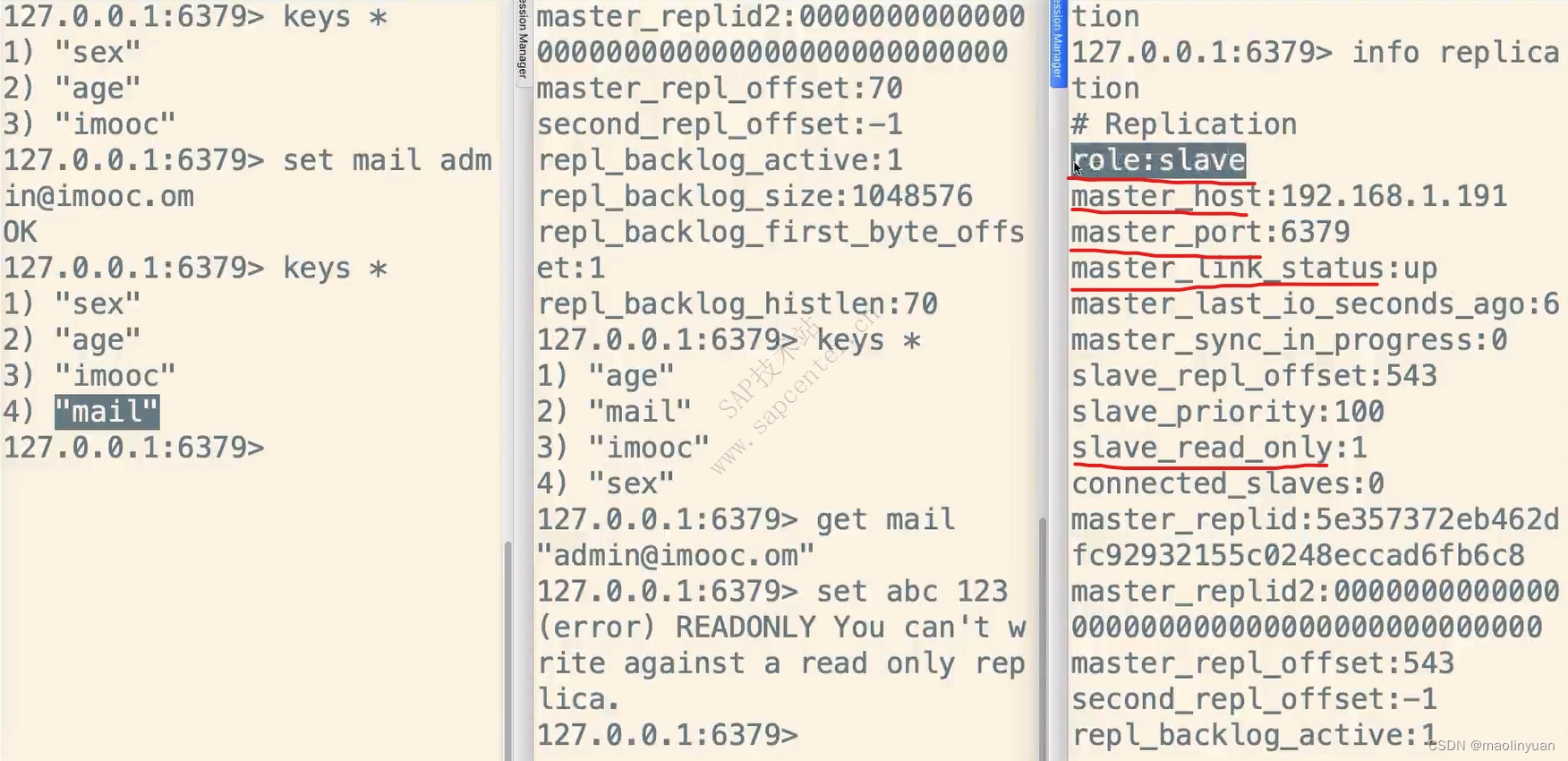
通过keys命令可以查看到主节点所有的内容都已经同步过来了
keys *查看主节点的主从属性内容,可以看到从节点数量已经变成了2,而且还能看到两台从节点的基本属性
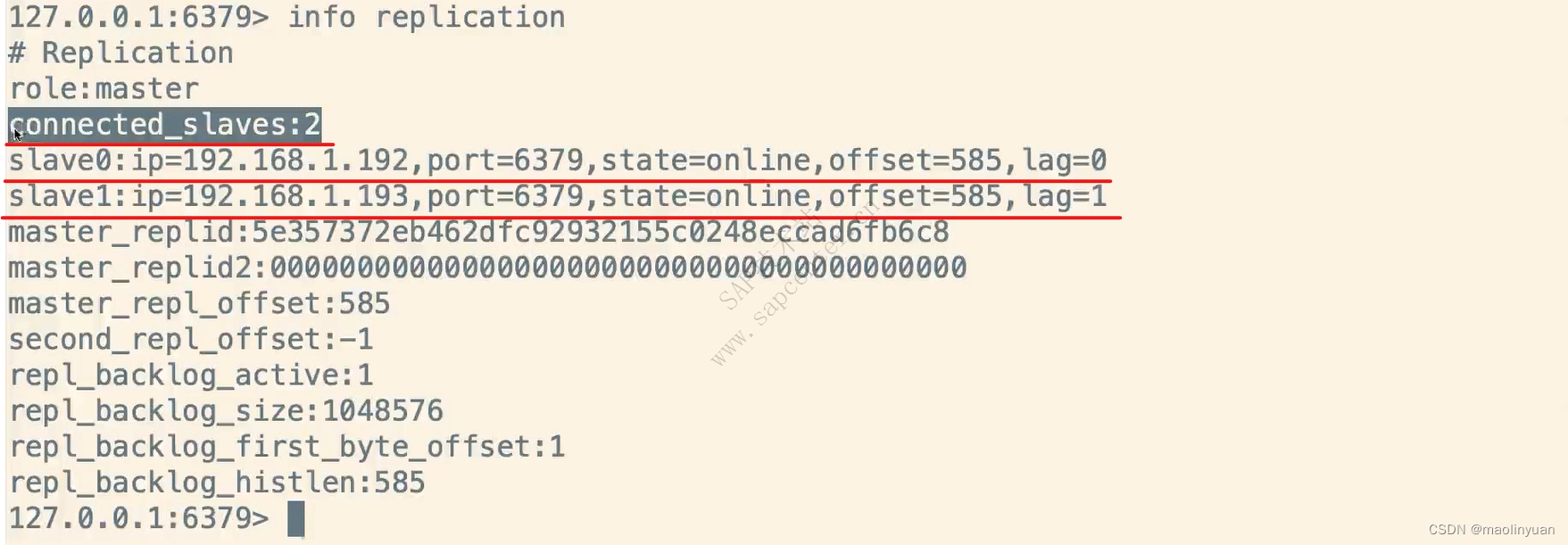
若关闭其中任意一个从节点的redis,可以看到主节点的redis的主从信息会发生相应变化,若在主节点中写入新的key-value,剩下的那台从节点还是可以进行同步;随之重启之前关闭的从节点的redis,可以看到重启之后最新数据照样被同步过来了
若关闭主节点的redis,查看从节点属性可以看到master_link_status从up变成了down,而且从节点不会自动选举变成一个master,保持原样不动,等待master重新上线
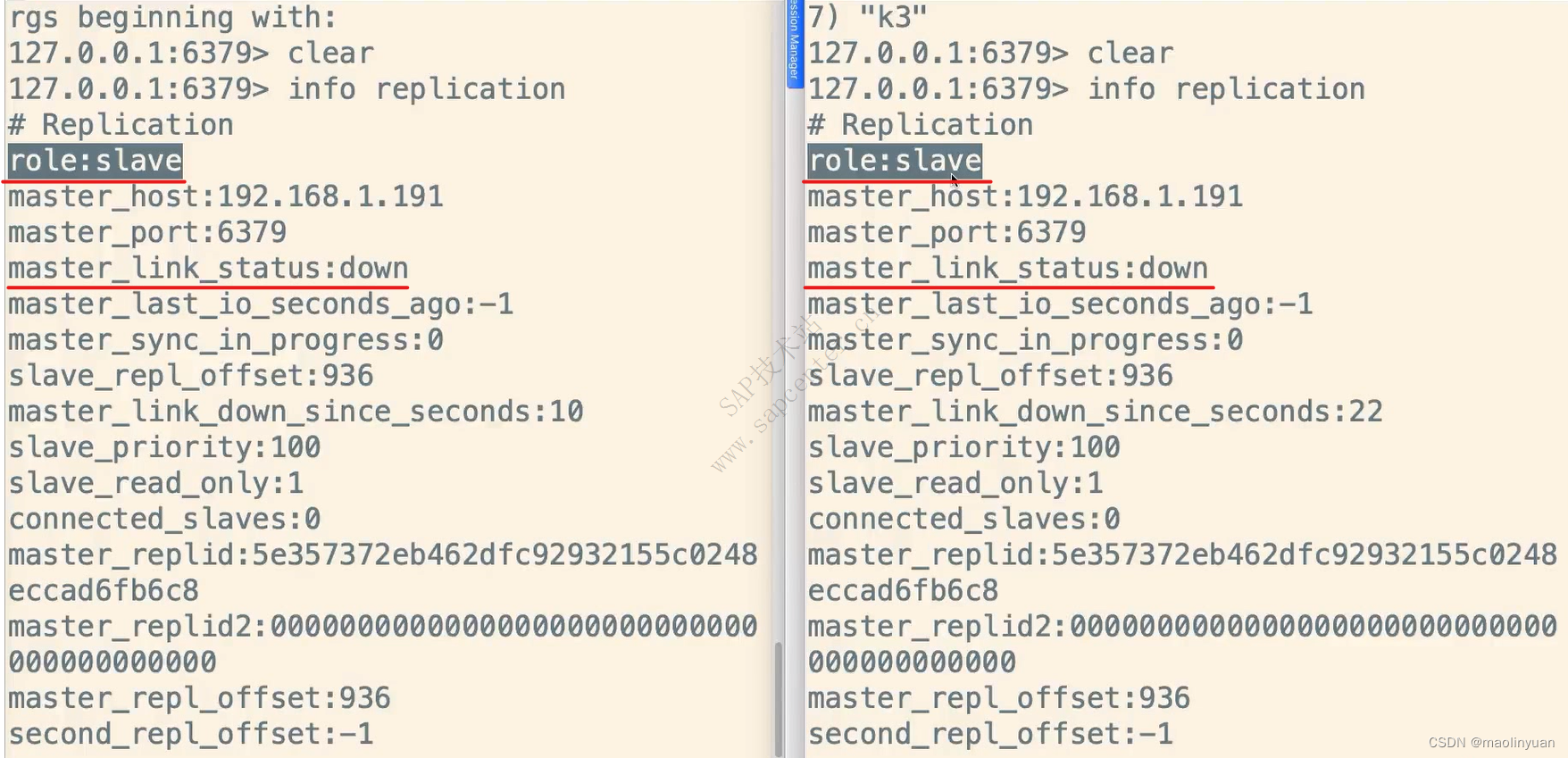
无磁盘化复制
Redis数据同步的策略有两种,一种是磁盘,另一种就是socket
- 磁盘方式:master节点将会创建一个新的进程将rdb文件写到磁盘中,随后这个文件将会被传输到各个从节点上
- socket方式:master节点将创建一个新的进程将rdb文件写到socket中,从来不会去接触磁盘
当服务器硬盘读写速度很低但是网络带宽很高则可以使用此方式,它直接把RDB文件写入到socket,通过主从之间的socket连接来同步数据,此配置是试验阶段,默认是关闭的
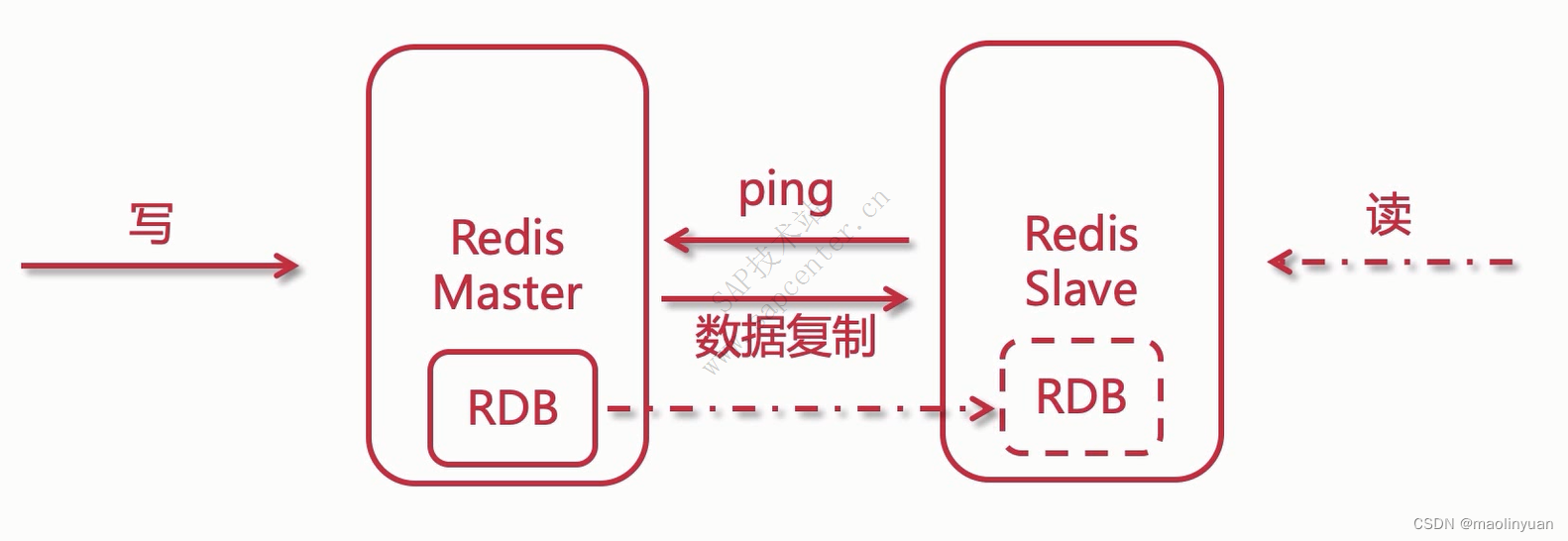
# 相关配置
repl-diskless-sync no # 是否开启无磁盘化复制 默认是关闭 需要使用时改为yes
repl-diskless-sync-delay 5 # 延时时间 等待从节点准备的时间
Redis缓存过期机制和内存淘汰机制
主动过期和被动过期
Redis keys过期有两种方式:被动(惰性删除)和主动(定期删除)方式。
当一些客户端尝试访问它时,key会被发现并主动的过期。
当然,这样是不够的,因为有些过期的keys,永远不会访问他们。 无论如何,这些keys应该过期,所以定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
- 测试随机的20个keys进行相关过期检测。
- 删除所有已经过期的keys。
- 如果有多于25%的keys过期,重复步奏1.
这是一个简单的概率算法,基本上的假设是,我们的样本是这个密钥控件,并且我们不断重复过期检测,直到过期的keys的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期keys。
在复制AOF文件时如何处理过期
为了获得正确的行为而不牺牲一致性,当一个key过期,
DEL将会随着AOF文字一起合成到所有附加的slaves。在master实例中,这种方法是集中的,并且不存在一致性错误的机会。然而,当slaves连接到master时,不会独立过期keys(会等到master执行DEL命令),他们任然会在数据集里面存在,所以当slave当选为master时淘汰keys会独立执行,然后成为master。
hz 10 # 每秒钟检测的次数 范围是1-500 超过100就并不是很好
内存管理
为了存储用户数据,当设置了maxmemory后Redis会分配几乎和maxmemory一样大的内存(然而也有可能还会有其他方面的一些内存分配).
精确的值可以在配置文件中设置,或者在启动后通过 CONFIG SET 命令设置(see Using memory as an LRU cache for more info). Redis内存管理方面,你需要注意以下几点:
- 当某些缓存被删除后Redis并不是总是立即将内存归还给操作系统。这并不是redis所特有的,而是函数malloc()的特性。例如你缓存了5G的数据,然后删除了2G数据,从操作系统看,redis可能仍然占用了5G的内存(这个内存叫RSS,后面会用到这个概念),即使redis已经明确声明只使用了3G的空间。这是因为redis使用的底层内存分配器不会这么简单的就把内存归还给操作系统,可能是因为已经删除的key和没有删除的key在同一个页面(page),这样就不能把完整的一页归还给操作系统.
- 上面的一点意味着,你应该基于你可能会用到的 最大内存 来指定redis的最大内存。如果你的程序时不时的需要10G内存,即便在大多数情况是使用5G内存,你也需要指定最大内存为10G.
- 内存分配器是智能的,可以复用用户已经释放的内存。所以当使用的内存从5G降低到3G时,你可以重新添加更多的key,而不需要再向操作系统申请内存。分配器将复用之前已经释放的2G内存.
- 因为这些,当redis的peak内存非常高于平时的内存使用时,碎片所占可用内存的比例就会波动很大。当前使用的内存除以实际使用的物理内存(RSS)就是fragmentation;因为RSS就是peak memory,所以当大部分key被释放的时候,此时内存的
mem_used / RSS就比较高.
如果 maxmemory 没有设置,redis就会一直向OS申请内存,直到OS的所有内存都被使用完。所以通常建议设置上redis的内存限制。或许你也想设置 maxmemory-policy 的值为 noeviction(不推荐)
设置了maxmemory后,当redis的内存达到内存限制后,再向redis发送写指令,会返回一个内存耗尽的错误。错误通常会触发一个应用程序错误,但是不会导致整台机器宕掉.
########## MEMORY MANAGEMENT ##########
maxmemory 4294967296 # 最大内存 单位是byte 这里设置4G
maxmemory-policy allkeys-lru # 到达最大内存后清理的策略 默认是 noeviction
maxmemory-policy
LRU:Least Recently Used 最近最少使用
LFU:Least Frequently Used 最少被访问
- noeviction:旧缓存永不过期,新缓存设置不了,返回错误
- allkeys-lru:清除最少用的旧缓存,然后保存新的缓存(推荐使用)
- allkeys-random:在所有的缓存中随机删除(不推荐)
- volatile-lru:在那些设置了expire过期时间的缓存中,清除最少用的旧缓存,然后保存新的缓存
- volatile-random:在那些设置了expire过期时间的缓存中,随机删除缓存
- volatile-ttl:在那些设置了expire过期时间的缓存中,删除即将过期的
Redis哨兵模式
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
解决主节点离线之后,主从架构中从节点等待主节点恢复时,此时整个架构只能进行读取数据,而不能进行写入数据的问题。
哨兵会做到让从节点晋升为主节点,从而代替原来失效的主节点,其他的从节点会自动成为新主节点的从节点,旧主节点恢复连接之后会自动变为从节点连接到主从架构之中。
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
Redis Sentinel 是一个分布式系统, 你可以在一个架构中运行多个 Sentinel 进程(progress), 这些进程使用流言协议(gossip protocols)来接收关于主服务器是否下线的信息, 并使用投票协议(agreement protocols)来决定是否执行自动故障迁移, 以及选择哪个从服务器作为新的主服务器。
虽然 Redis Sentinel 释出为一个单独的可执行文件 redis-sentinel , 但实际上它只是一个运行在特殊模式下的 Redis 服务器, 你可以在启动一个普通 Redis 服务器时通过给定 –sentinel 选项来启动 Redis Sentinel 。
启动 Sentinel有两种方法
对于 redis-sentinel 程序, 你可以用以下命令来启动 Sentinel 系统:
redis-sentinel /path/to/sentinel.conf对于 redis-server 程序, 你可以用以下命令来启动一个运行在 Sentinel 模式下的 Redis 服务器:
redis-server /path/to/sentinel.conf --sentinel
启动 Sentinel 实例必须指定相应的配置文件, 系统会使用配置文件来保存 Sentinel 的当前状态, 并在 Sentinel 重启时通过载入配置文件来进行状态还原。
如果启动 Sentinel 时没有指定相应的配置文件, 或者指定的配置文件不可写(not writable), 那么 Sentinel 会拒绝启动。
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
用文字描述一下故障切换(failover)的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
哨兵配置并演示
基于之前主从架构的三台虚拟机进行设置
找到安装包中的sentinel.conf文件,拷贝此配置文件到redis.conf文件同一目录下方便管理
cp ./sentinel.conf /usr/local/redis/
进入目标文件夹,编辑拷贝过来的配置文件
cd /usr/local/redis/ # 进入目标文件夹 vim sentinel.conf # 编辑文件变更配置
########## IMPORTANT ########## # bind 127.0.0.1 192.168.1.1 # 绑定的ip 默认是注释掉的 表示哪些ip可以访问sentinel protected-mode no # 保护模式 为了方便测试 这里选择关闭 默认是注释掉的 port 26379 # 端口号 默认是26379 daemonize yes # 后台启动模式 默认是no 这里改成yes pidfile /var/run/redis-sentinel.pid # 进程pid文件所在的位置 sentinel是一个单独的进程 所以要有个pid文件 使用默认的 logfile /usr/local/redis/sentinel/redis-sentinel.log # 指定日志文件的地址 默认是"" dir /usr/local/redis/sentinel # sentinel的工作目录 默认是/tmp # 配置监控master的信息 sentinel monitor <master-name> <ip> <port> <quorum> # master-name: 给master指定一个别名 命名只能由字符A-z 0-9 .-_ 组成 # ip: master的ip # port: master的端口 # quorum: 配置多少个sentinel统一认为master节点离线 那么这时客观上认为主节点离线 # 默认是sentinel monitor mymaster 127.0.0.1 6379 2 sentinel monitor imooc-master 192.168.1.191 6379 2 # 配置密码 sentinel auth-pass <master-name> <password> # master-name: 别名 需要和之前统一 # password: 监控的redis-server的密码 注意:所有主从需要设置一样的密码 sentinel auth-pass imooc-master imooc # 配置master离线多少毫秒后sentinel会认为其主观下线 sentinel down-after-milliseconds <master-name> <milliseconds> # master-name: 别名 需要和之前统一 # milliseconds: 毫秒数 sentinel down-after-milliseconds imooc-master 30000 # 配置同步的并行数 sentinel parallel-syncs <master-name> <numreplicas> # 当有一个slave被选举为新的master之后,其他原来的slave和新的master之间要同步数据,指定同一时刻可以进行同步的slave数量;这个数字越小failover所需的时间就越长,但是这个数字越大,就意味着越多的slave因为replication而不可用,可以通过设置值为1来保证每次只有一个slave处于不能处理命令的状态 # master-name: 别名 需要和之前统一 sentinel parallel-syncs imooc-master 1 # 配置sentinel故障转移超时时间 sentinel failover-timeout <master-name> <milliseconds> # 可以应用到以下方面: # 1. 同一个sentinel对同一个master两次failover之间的间隔时间 # 2. 当一个slave从一个错误的master那里同步数据开始计算时间,直到slave被纠正为向正确的master那里同步数据的时间 # 3. 当想要取消一个正在进行的failover所需要的时间 # 4. 当进行failover时,配置所有slave指向新的master所需要的最大时间。不过,即使过了这个时间,slave依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了 # master-name: 别名 需要和之前统一 # milliseconds: 毫秒数 默认三分钟 sentinel failover-timeout imooc-master 180000 ########## SCRIPTS EXECUTION ########## # sentinel notification-script <master-name> <script-path> # 配置当某一事件发生时需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发送邮件通知相关人员 # 对于脚本的运行结果有以下规则: # 1. 若脚本执行之后返回1,那么脚本稍后会被重复执行,重复次数目前默认为10 # 2. 若脚本执行之后返回2,或者比2更高的一个返回值,脚本将不会重复执行 # 3. 若脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同 # 4. 一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行 # 通知型脚本:当sentinel有任何警告级别的事件发生时(例如redis实例的主观失效和客观失效等),将回去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式通知系统管理员系统不正常运行的信息。调用该脚本时,将传递给脚本两个参数,一个是事件类型,一个是事件描述。如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且必须是可执行的,否则sentinel无法正常启动 sentinel notification-script imooc-master /var/redis/notify.sh # sentinel client-reconfig-script <master-name> <script-path> # 客户端重新配置主节点参数脚本 # 当一个master由于故障转移而发生改变时,这个脚本将会被调用,通知相关客户端关于master地址已经发生改变的信息。 # 以下参数将会在调用脚本时传给脚本 # <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port> # 目前<state>总是"failover" # <role>是"leader"或者"observer"中的一个 # 参数<from-ip> <from-port> <to-ip> <to-port>是用来和旧的master和新的master(原来是slave)通信的 # 这个脚本应该是通用的,能被多次调用,不是针对性的 sentinel client-reconfig-script imooc-master /var/redis/reconfig.sh使用到的配置一览
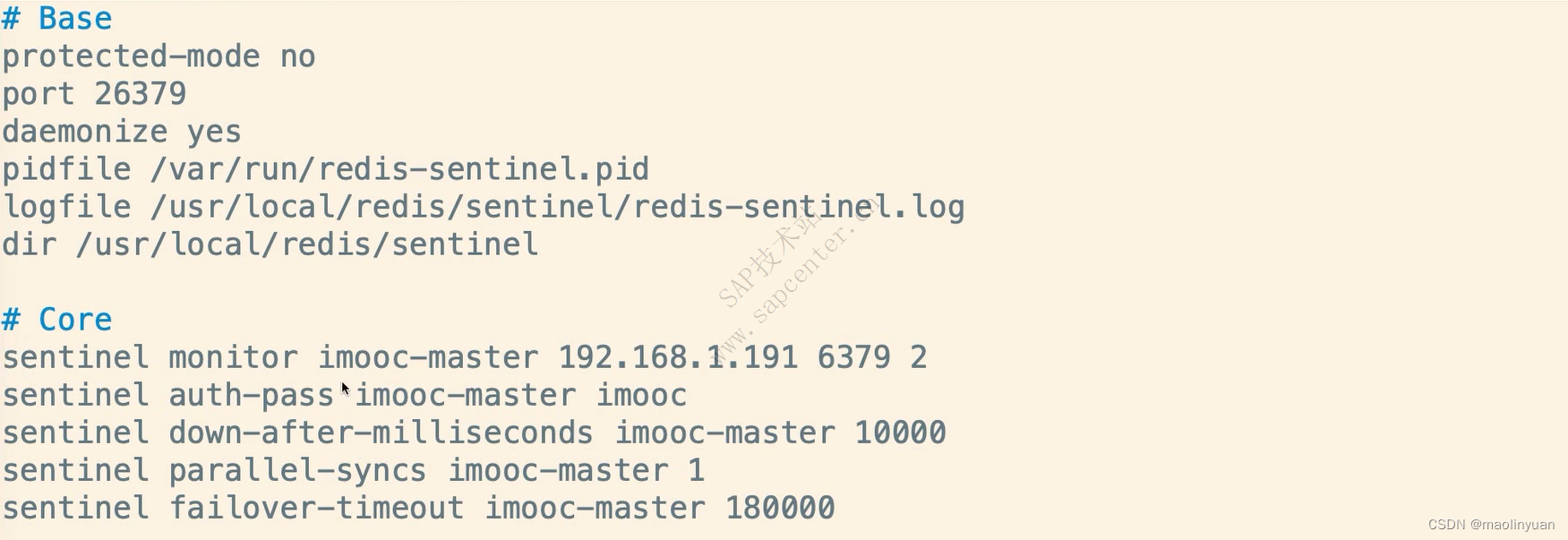
三个redis-server节点都需要配置一个哨兵,这样就形成了一个哨兵集群,但是配置都是一样的,所以可以通过远程拷贝命令把此配置文件发送给别的节点
# 指定要拷贝的文件夹 远程登录的用户名 远程ip 目标地址 执行之后若提示是否继续 输入yes 然后需要输入远程主机的密码 scp sentinel.conf root@192.168.1.192:/usr/local/redis/ scp sentinel.conf root@192.168.1.193:/usr/local/redis/给三个节点创建配置文件中配置的log文件所在的目录
mkdir /usr/local/redis/sentinel -p查看redis-sentinel命令所在的位置
whereis redis-sentinel # 查看命令所在的位置
三个节点启动哨兵
redis-sentinel sentinel.conf # 若不指定配置文件 则会启动之后立刻退出启动成功后查看进程
ps -ef | grep redis
查看日志文件,可以发现191是主节点,192 、193是从节点
cd /usr/local/redis/sentinel tail -f redis-sentinel.log # 查看日志文件
启动模式是一个sentinel
一个master和两个slave受到此sentinel的监控
启动192节点和193节点的sentinel,日志会提示新增了两个sentinel的监控
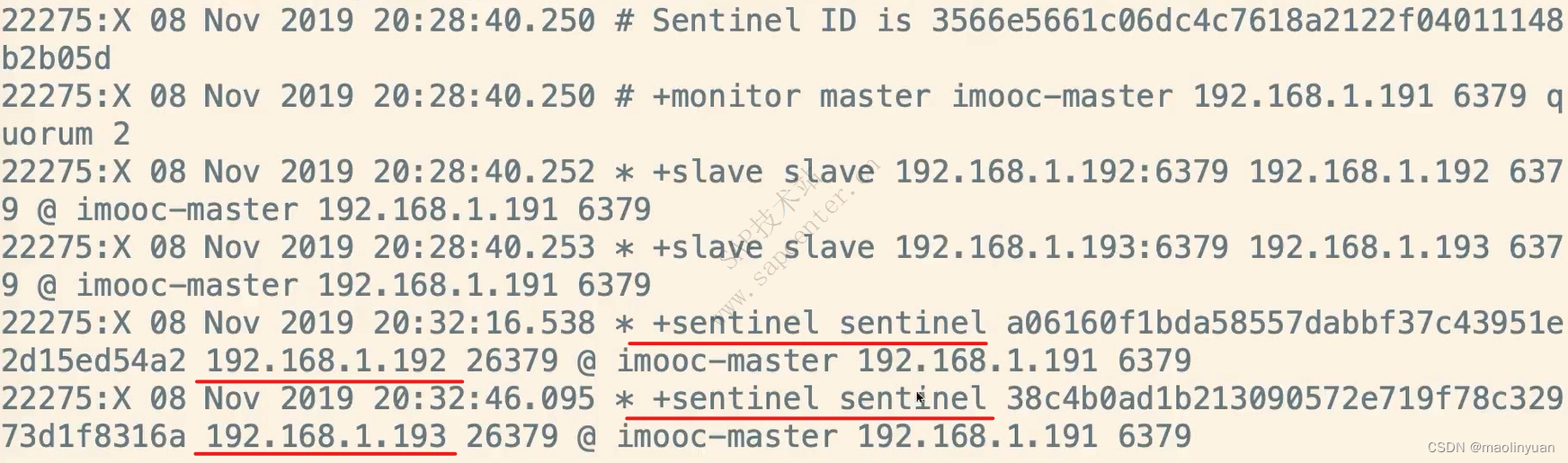
客户端可以将 Sentinel 看作是一个只提供了订阅功能的 Redis 服务器: 你不可以使用 PUBLISH 命令向这个服务器发送信息, 但你可以用 SUBSCRIBE 命令或者 PSUBSCRIBE 命令, 通过订阅给定的频道来获取相应的事件提醒。
一个频道能够接收和这个频道的名字相同的事件。 比如说, 名为 +sdown 的频道就可以接收所有实例进入主观下线(SDOWN)状态的事件。
通过执行 PSUBSCRIBE * 命令可以接收所有事件信息。
以下列出的是客户端可以通过订阅来获得的频道和信息的格式: 第一个英文单词是频道/事件的名字, 其余的是数据的格式。
注意, 当格式中包含 instance details 字样时, 表示频道所返回的信息中包含了以下用于识别目标实例的内容:
<instance-type> <name> <ip> <port> @ <master-name> <master-ip> <master-port>@ 字符之后的内容用于指定主服务器, 这些内容是可选的, 它们仅在 @ 字符之前的内容指定的实例不是主服务器时使用。
- +reset-master :主服务器已被重置。
- +slave :一个新的从服务器已经被 Sentinel 识别并关联。
- +failover-state-reconf-slaves :故障转移状态切换到了 reconf-slaves 状态。
- +failover-detected :另一个 Sentinel 开始了一次故障转移操作,或者一个从服务器转换成了主服务器。
- +slave-reconf-sent :领头(leader)的 Sentinel 向实例发送了 SLAVEOF 命令,为实例设置新的主服务器。
- +slave-reconf-inprog :实例正在将自己设置为指定主服务器的从服务器,但相应的同步过程仍未完成。
- +slave-reconf-done :从服务器已经成功完成对新主服务器的同步。
- -dup-sentinel :对给定主服务器进行监视的一个或多个 Sentinel 已经因为重复出现而被移除 —— 当 Sentinel 实例重启的时候,就会出现这种情况。
- +sentinel :一个监视给定主服务器的新 Sentinel 已经被识别并添加。
- +sdown :给定的实例现在处于主观下线状态。
- -sdown :给定的实例已经不再处于主观下线状态。
- +odown :给定的实例现在处于客观下线状态。
- -odown :给定的实例已经不再处于客观下线状态。
- +new-epoch :当前的纪元(epoch)已经被更新。
- +try-failover :一个新的故障迁移操作正在执行中,等待被大多数 Sentinel 选中(waiting to be elected by the majority)。
- +elected-leader :赢得指定纪元的选举,可以进行故障迁移操作了。
- +failover-state-select-slave :故障转移操作现在处于 select-slave 状态 —— Sentinel 正在寻找可以升级为主服务器的从服务器。
- no-good-slave :Sentinel 操作未能找到适合进行升级的从服务器。Sentinel 会在一段时间之后再次尝试寻找合适的从服务器来进行升级,又或者直接放弃执行故障转移操作。
- selected-slave :Sentinel 顺利找到适合进行升级的从服务器。
- failover-state-send-slaveof-noone :Sentinel 正在将指定的从服务器升级为主服务器,等待升级功能完成。
- failover-end-for-timeout :故障转移因为超时而中止,不过最终所有从服务器都会开始复制新的主服务器(slaves will eventually be configured to replicate with the new master anyway)。
- failover-end :故障转移操作顺利完成。所有从服务器都开始复制新的主服务器了。
- +switch-master :配置变更,主服务器的 IP 和地址已经改变。 这是绝大多数外部用户都关心的信息。
- +tilt :进入 tilt 模式。
- -tilt :退出 tilt 模式。
关闭master节点的redis-server,可以看到sentinel会进行故障转移让一个slave转变为master
/etc/init.d/redis_init_script stop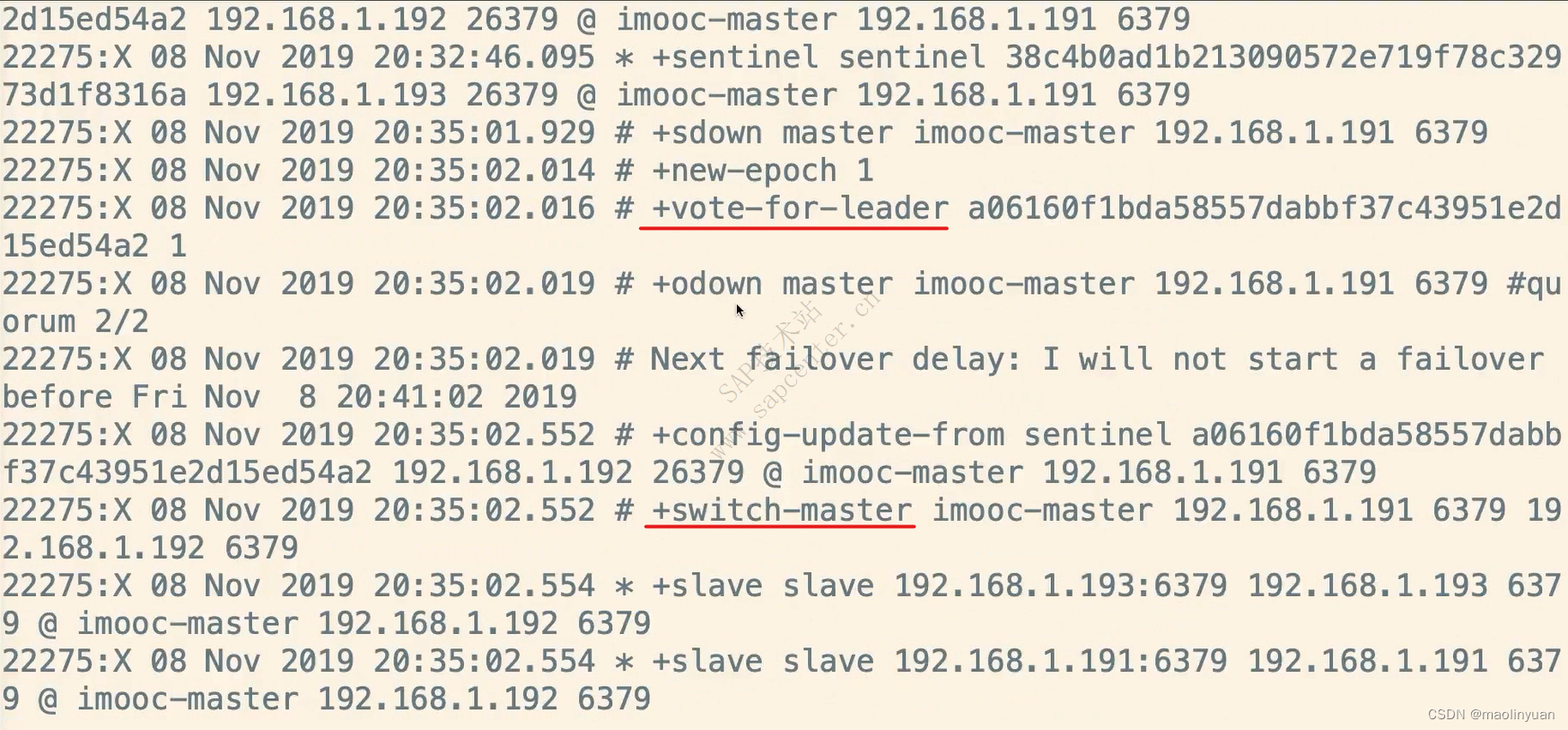
查看192节点的角色已经变成了master,并且有一个从节点是193,说明192和193组成了一个新的主从
redic-cli AUTH imooc info replication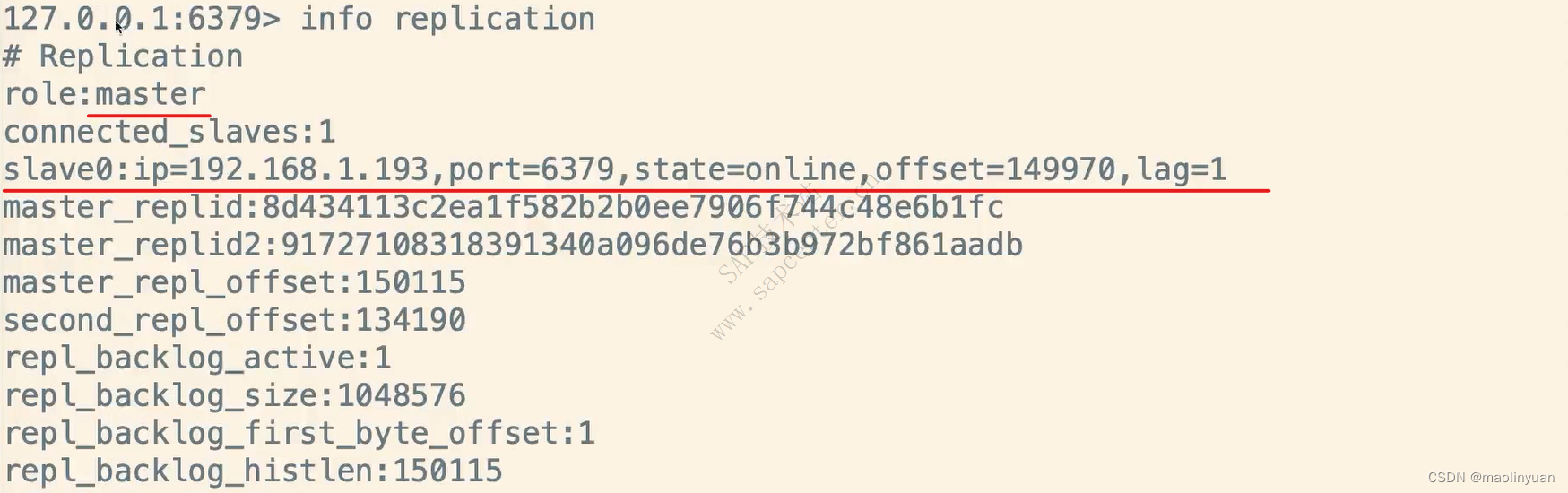
恢复191节点,191将会被转换为slave节点添加到原来的主从结构中
/etc/init.d/redis_init_script start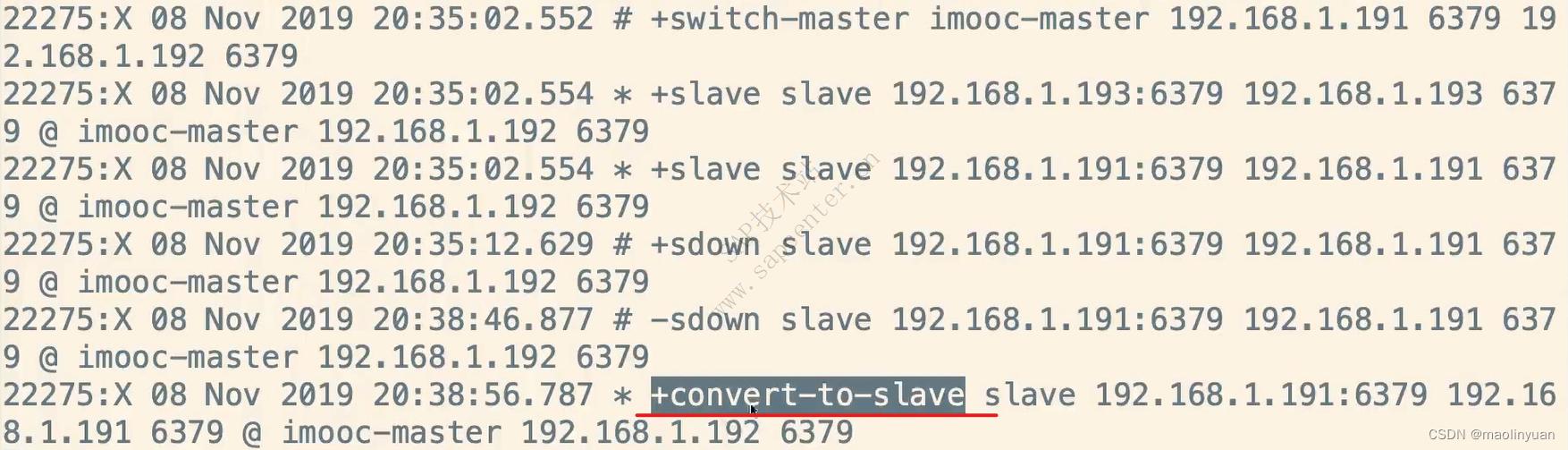
参考链接:
SpringBoot整合redis-sentinel
spring:
# redis 配置
redis:
# 数据库索引
database: 0
# 密码
password: imooc
# sentinel配置
sentinel:
# master节点的别名
master: imooc-master
# 哨兵节点的地址 相当于sentinel对redis-server进行了托管 所以配置sentinel的端口而不是redis-server的端口
nodes: 192.168.1.191:26379,192.168.1.192:26379,192.168.1.193:26379
lettuce:
pool:
# 连接池中的最小空闲连接
min-idle: 0
# 连接池中的最大空闲连接
max-idle: 8
# 连接池的最大数据库连接数
max-active: 8
# #连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1ms
Redis多主多从集群
主从结构(一主二从):读写分离模型,写入数据从主库中写入,异步同步数据到从库,从库可以处理读取请求。主节点离线时候,从节点将会等待主节点重新恢复,此时将只能处理读取请求。
哨兵模式(一主二从三哨兵):在主从模式上新增了哨兵来监控主从模型各个节点的状态,可以在主节点离线之后进行故障转移。重新将一个原来的从节点选举为一个主节点,其他的从节点将会成为新主节点下的从节点,主节点恢复之后将会被转换为从节点,连接到新主节点的下级。因此,此模型在任意时刻都可以处理读写请求。
集群模式(三主三从):因为不管是哨兵模型还是主从模型,都只有一个主节点处理写入请求,所以性能总会有上限。而且,主从同步数据时是异步的,数据的瞬时一致性无法保证。主节点宕机时,新的从节点被转换为主节点,原来主节点宕机时未同步完成的数据将会丢失。集群模式相当于对所有数据进行了分片,写入数据时先对key进行hash计算16384的槽位,算出要将数据存储的节点,然后再存储到某一个主节点中,每个主节点只存放一部分数据,从节点将会同步自己主节点中的所有数据,提高了写入性能和容灾能力,并且易于水平扩展。
参考链接:
Redis集群介绍
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集,集群之间各个节点是可以互相通信的。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令. Redis 集群的优势:
- 自动分割数据到不同的节点上。
- 整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
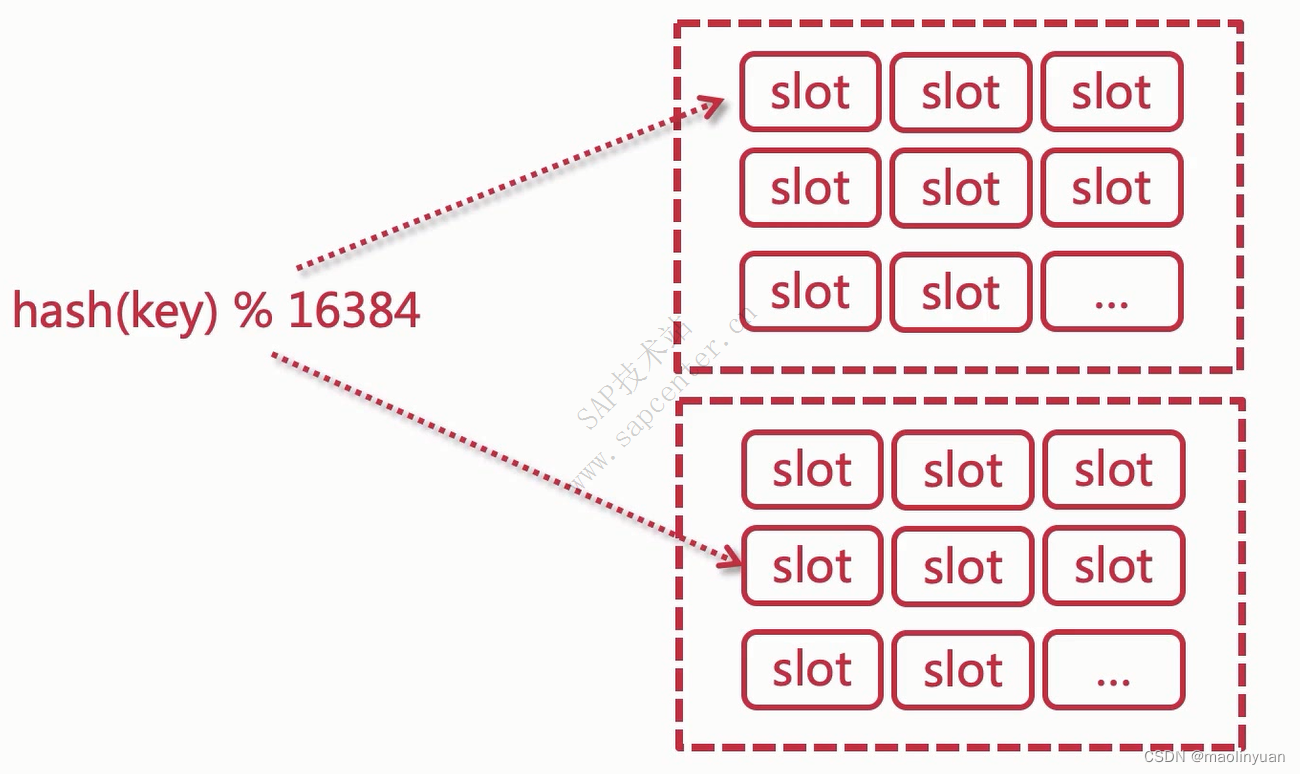
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5500号哈希槽.
- 节点 B 包含5501 到 11000 号哈希槽.
- 节点 C 包含11001 到 16383号哈希槽.
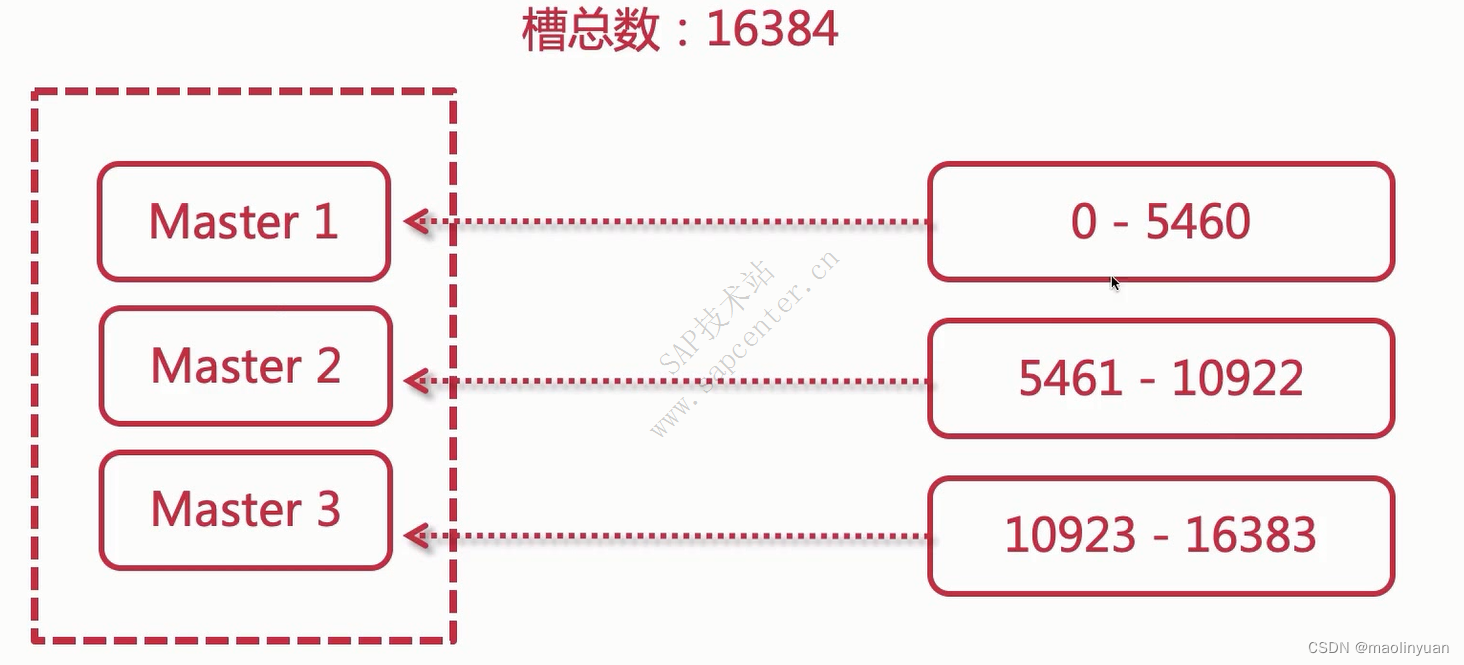
注意:槽只会分配给master节点,不会分配给slave节点,slave节点只是做自己master节点的备份
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
Redis 一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
- 客户端向主节点B写入一条命令.
- 主节点B向客户端回复命令状态.
- 主节点将写操作复制给他得从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项.
三主三从集群设计
基于基本的单实例Redis的配置,克隆六个虚拟机作为集群中的六个节点
虚拟机或服务器准备
- 主节点:192.168.1.201,192.168.1.202,192.168.1.203
- 从节点:192.168.1.204,192.168.1.205,192.168.1.206
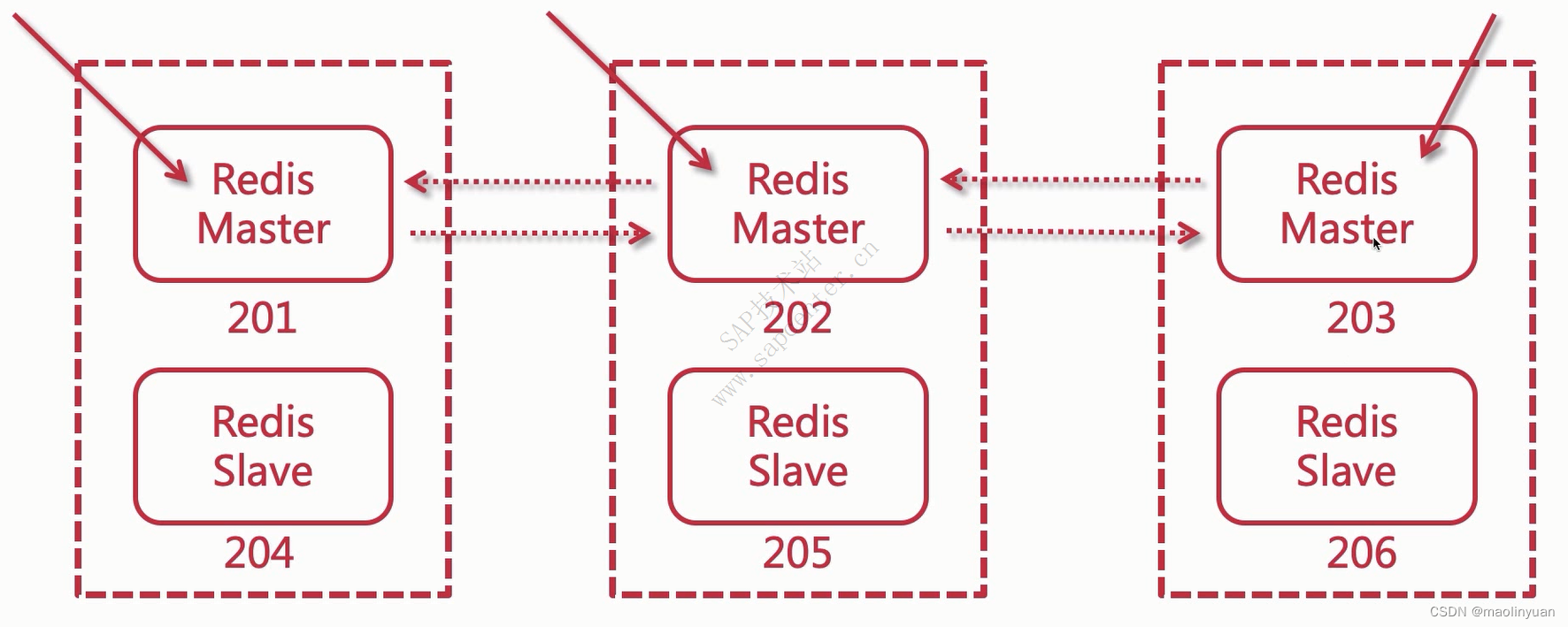
集群配置并演示
进入201节点,找到并打开Redis配置文件
cd /usr/local/redis/ vim redis.conf找到cluster部分,修改配置文件
########## REDIS CLUSTER ########## cluster-enabled yes # 是否开启cluster 默认是被注释的 cluster-config-file node-6379.conf # 配置cluster生成的配置文件的路径 是由redis本身去生成和管理的 默认是被注释掉的 直接放开就行了 不用修改内容 cluster-node-timeout 15000 # 配置节点连接超时的时间 超过这个时间之后可以进行主备切换 appendonly yes # 保持aof开启进去Redis的工作目录,删除之前Redis持久化的文件内容,保证Redis内部没有数据。因为此文件是单机单实例情况下生成的,所以如果有这两个文件在集群方式下会报错。
cd /usr/local/redis/db/ rm -rf dump.rdb appendonly.aof重新启动201的Redis实例,并查看进程信息,可以看到它有一个cluster的标识
在202,203,204,205,206节点上的Redis重复以上步骤配置一遍并启动
如果Redis是在早期的版本,则还要构建一个ruby的环境,通过使用 Redis 集群命令行工具 redis-trib , 编写节点配置文件的工作可以非常容易地完成: redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作。
现阶段可以使用redis-cli命令加入参数构建集群
# 使用 redis-cli --cluster help 命令可以查看帮助 # a之后跟密码(每个节点的密码最好一样) create之后跟每个节点的ip和端口 cluster-replicas之后是主节点和从节点的比例 redis-cli -a imooc --cluster create 192.168.1.201:6379 192.168.1.202:6379 192.168.1.203:6379 192.168.1.204:6379 192.168.1.205:6379 192.168.1.206:6379 --cluster-replicas 1确认是否使用这个配置,输入yes,集群创建成功
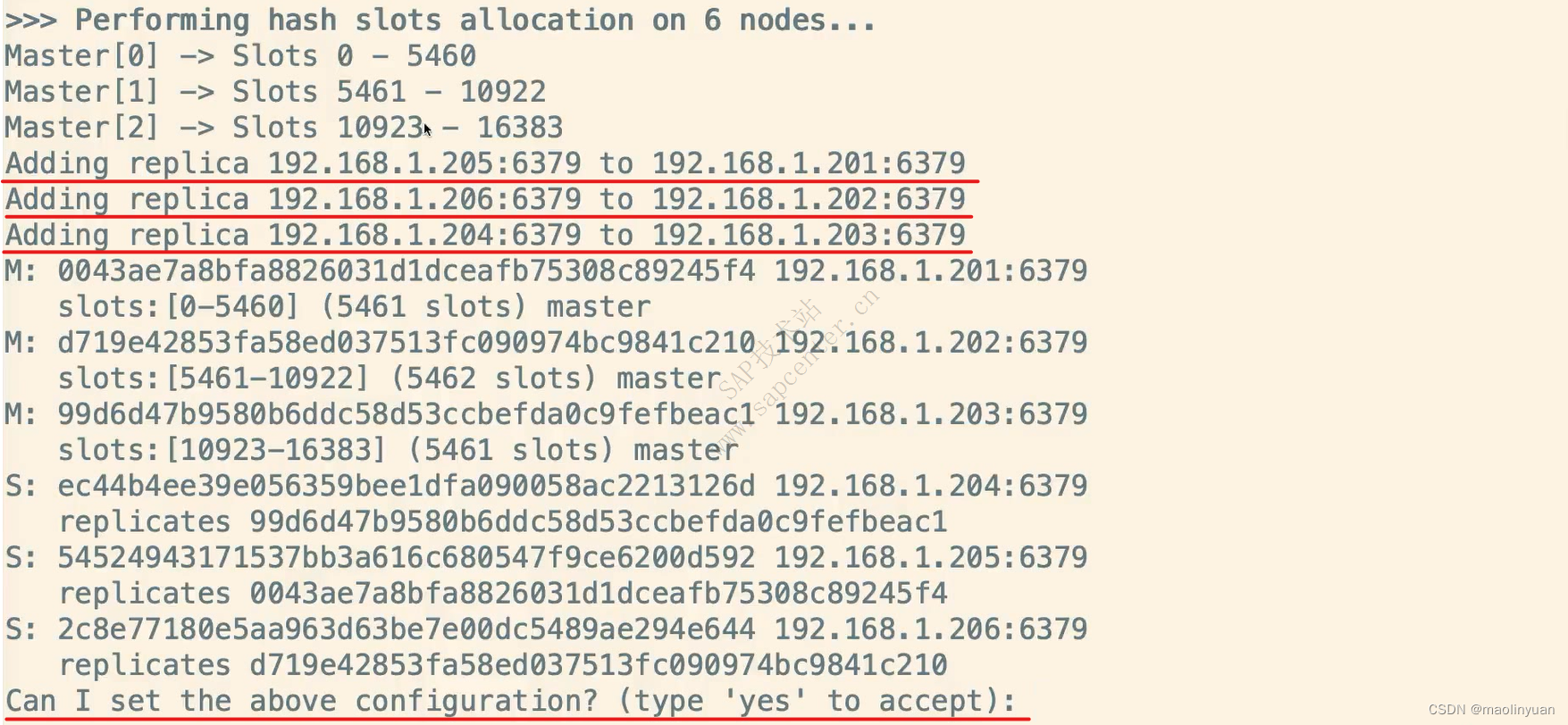
M 代表mster
S 代表slave
添加 205 作为 201 的从节点,201 分配了 0-5460 个槽(slots)
添加 206 作为 202 的从节点,202 分配了 5461-10922 个槽(slots)
添加 204 作为 203 的从节点,203 分配了 10922-16383 个槽(slots)
因为是Redis构建时自动分配的,所以和之前的规划有区别。

检查集群中某一个节点的信息,将会上一步看到的配置信息
redis-cli -a imooc --cluster check 192.168.1.201:6379使用redis-cli命令连接集群,并查看集群信息
redis-cli -c -a imooc -h 192.168.1.202 -p 6379 cluster info # 查看集群信息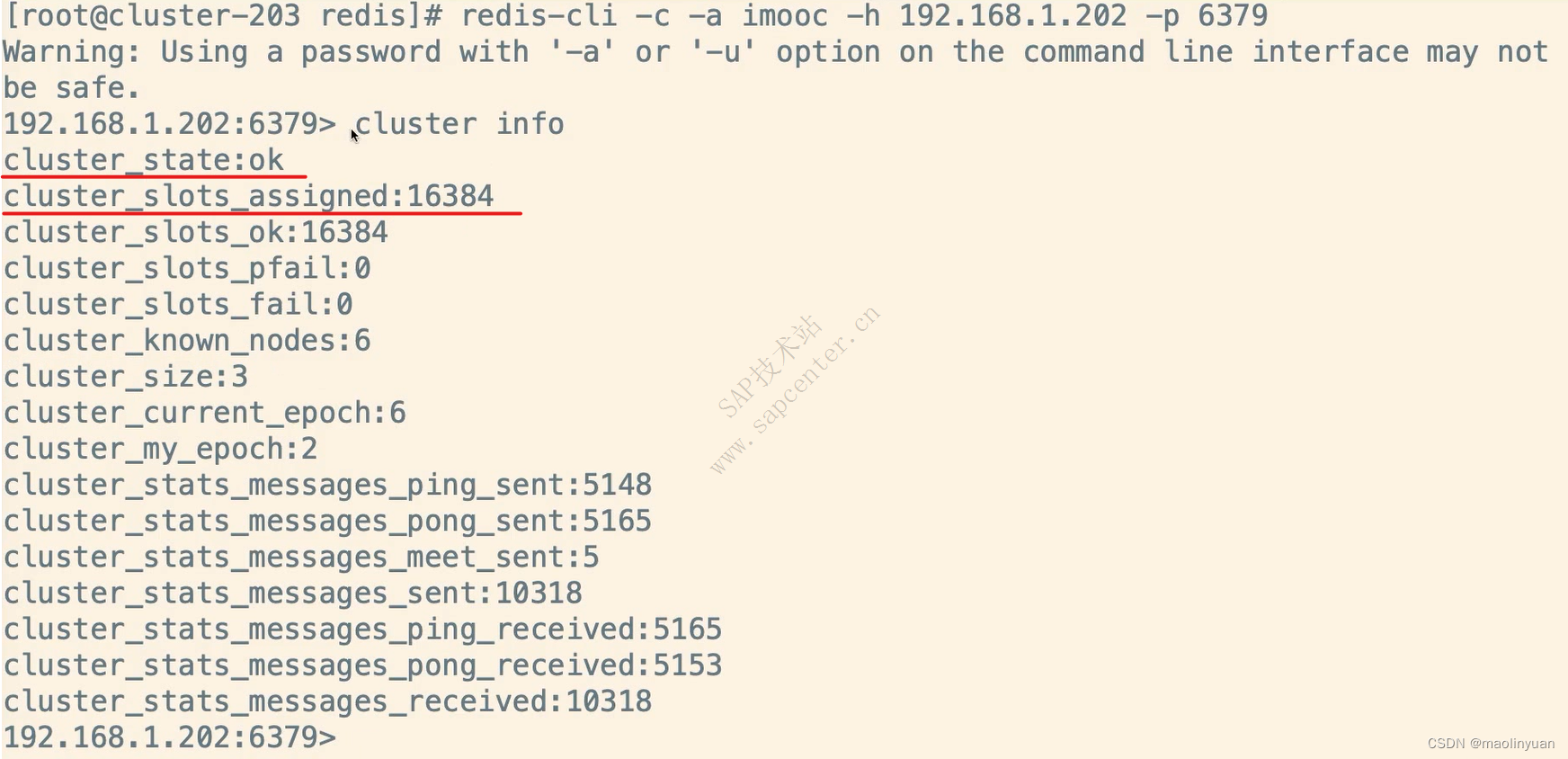
cluster nodes # 查看节点信息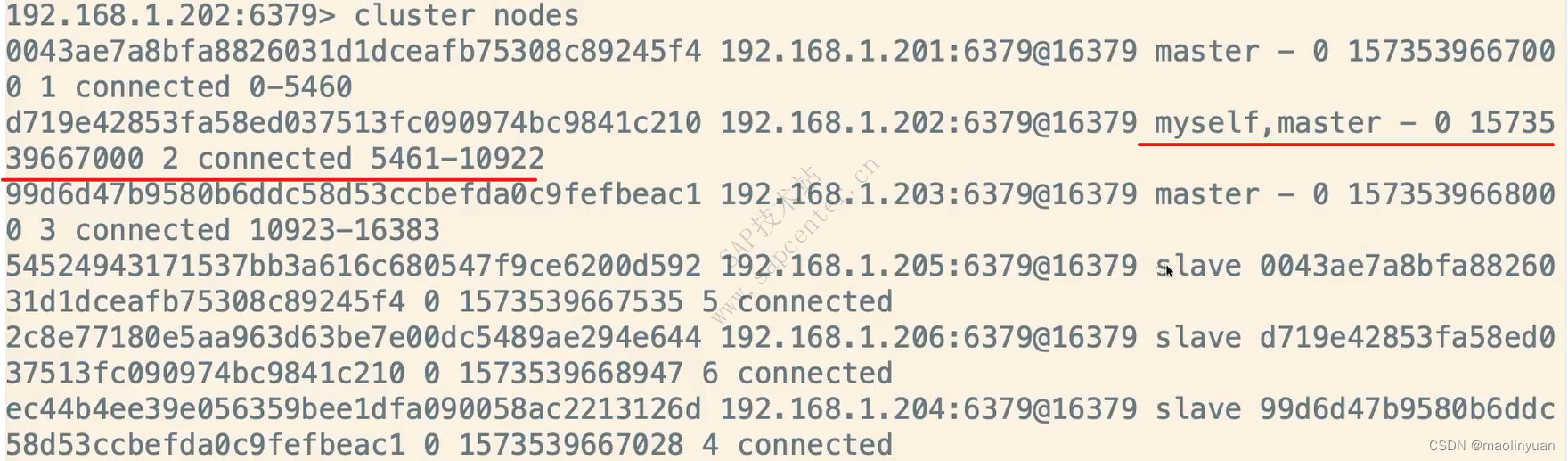
使用redis-cli命令向集群中设置key-value时,会发现在设置某些key时会提示Redirected(重定向),说明这个key被hash之后所得到的槽编号属于此集群中的另外的节点,这时它会重定向连接到那个节点。
# 当在集群某一个节点上使用keys * 并不会返回集群中所有的key 只会返回这个节点所拥有的key keys *
SpringBoot整合redis-cluster
spring:
# redis 配置
redis:
# 密码
password: imooc
# cluster配置
cluster:
# 所有节点的ip端口
nodes: 192.168.1.201:6379,192.168.1.202:6379,192.168.1.203:6379,192.168.1.204:6379,192.168.1.205:6379,192.168.1.206:6379
lettuce:
pool:
# 连接池中的最小空闲连接
min-idle: 0
# 连接池中的最大空闲连接
max-idle: 8
# 连接池的最大数据库连接数
max-active: 8
# #连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1ms
缓存穿透、击穿、雪崩解决方案
缓存穿透
定义
指查询一个缓存和数据库都不存在的数据,导致尽管数据不存在但是每次都会到数据库查询。在访问量大时可能DB就会挂掉。如果有人利用不存在的key频繁攻击,则这就形成了漏洞。
解决方案
接口请求参数的校验。对请求的接口进行鉴权,数据合法性的校验等;比如查询的userId不能是负值或者包含非法字符等。
如果一个查询返回的数据为空,我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
布隆过滤器。使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。(会有一定的出错率,过滤器长度越短出错率越高)
布隆过滤器是防止缓存穿透的方案之一,放在缓存之后数据库之前。布隆过滤器主要是解决大规模数据下不需要精确过滤的业务场景,如检查垃圾邮件地址,爬虫URL地址去重, 解决缓存穿透问题等。
布隆过滤器:在一个存在一定数量的集合中过滤一个对应的元素,判断该元素是否一定不在集合中或者可能在集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; /** * @program: SortDemo * @author: weidd * @date: 2021-02-27 18:58 **/ public class TestBloomFilter { //测试使用布隆过滤器解决缓存穿透问题 //需引入:guava包 private static final int capacity = 10000000; private static final int key = 9222222; private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), capacity); static { for (int i = 0; i < capacity; i++) { bloomFilter.put(i); } } public static void main(String[] args) { long star=System.nanoTime();//微秒: 1 秒=1000000 微秒 if(bloomFilter.mightContain(key)){ System.out.println("布隆过滤器过滤到"+key); } long end=System.nanoTime();//微秒: 1 秒=1000000 微秒 System.out.println("过滤消耗时间:"+(end-star)+"微秒"); } }
缓存击穿
定义
某个热点 key,在缓存过期的一瞬间,同时有大量的请求打进来,由于此时缓存过期了,所以请求最终都会走到数据库,造成瞬时数据库请求量大、压力骤增,导致数据库存在被打挂的风险。
解决方案
设置缓存不过期或者后台有线程一直给热点数据续期。
加互斥锁。当热点key过期后,大量的请求涌入时,只有第一个请求能获取锁并且其他请求获取不到锁就阻塞,此时该请求查询数据库,并将查询结果写入redis后释放锁。后续的请求直接走缓存。
这个流程大概如下:
- 请求到达Redis,发现Redis Key过期,查看有没有锁,没有锁的话回到队列后面排队
- 设置锁,注意,这儿应该是setnx(),而不是set(),因为可能有其他线程已经设置锁了
- 获取锁,拿到锁了就去数据库取数据,请求返回后释放锁。
但是引出了一个新的问题,如果拿到锁去拿数据的请求然后挂了怎么办?
也就是锁没有释放,其他进程都在等锁,解决办法是:
对锁设置一个过期时间,如果到达了过期时间还没释放就自动释放,问题又来了,锁挂了好说,但是如果是锁超时呢?
也就是在设定的时间里数据没有取出来,但是锁由过期了,常见的思路是,锁过期时间值递增,但是想想不靠谱,因为第一个请求可能超时,如果后面的也超时呢,接连多次超时之后,锁过期时间值势必特别大了,这样做弊端太多。
另外一个思路是,再开启一个线程,进行监控,如果取数据的线程没有挂的话,就适当延迟锁的过期时间。
缓存雪崩
定义
雪崩,和击穿类似,不同的是击穿是一个热点Key某时刻失效,而雪崩是大量的热点Key在一瞬间失效,造成瞬时数据库请求量大、压力骤增,引起雪崩,导致数据库存在被打挂的风险。
解决方案
将热点数据的过期时间打散。给热点数据设置过期时间时加个随机值。
首先要看看这个Key过期是不是时点性有关,时点性无关的话,可以随机过期时间解决。如果是时点性有关,那么就要利用强依赖击穿方案,策略是先过去的线程更新一下所有key。
在后台更新热点key的同时,业务层将进来的请求延时一下,例如短暂的睡几毫秒或者秒,给后面的更新热点key分散压力。
加互斥锁。当热点key过期后,大量的请求涌入时,只有第一个请求能获取锁并且其他请求获取不到锁就阻塞,此时该请求查询数据库,并将查询结果写入redis后释放锁。后续的请求直接走缓存。
设置缓存不过期或者后台有线程一直给热点数据续期。
参考链接:
代码中优雅批量查询key的方式
Redis 使用的是客户端-服务器(CS)模型和请求/响应协议的 TCP 服务器。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听 Socket 返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
Redis 客户端与 Redis 服务器之间使用 TCP 协议进行连接,一个客户端可以通过一个 socket 连接发起多个请求命令。每个请求命令发出后 client 通常会阻塞并等待 redis 服务器处理,redis 处理完请求命令后会将结果通过响应报文返回给 client,因此当执行多条命令的时候都需要等待上一条命令执行完毕才能执行。
由于通信会有网络延迟,假如 client 和 server 之间的包传输时间需要0.125秒。那么上面的三个命令6个报文至少需要0.75秒才能完成。这样即使 redis 每秒能处理100个命令,而我们的 client 也只能一秒钟发出四个命令。这显然没有充分利用 redis 的处理能力。
而管道(pipeline)可以一次性发送多条命令并在执行完后一次性将结果返回,pipeline 通过减少客户端与 redis 的通信次数来实现降低往返延时时间,而且 Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。 Pipeline 的默认的同步的个数为53个,也就是说 arges 中累加到53条数据时会把数据提交。例如client 可以将三个命令放到一个 tcp 报文一起发送,server 则可以将三条命令的处理结果放到一个 tcp 报文返回。
需要注意到是用 pipeline 方式打包命令发送,redis 必须在处理完所有命令前先缓存起所有命令的处理结果。打包的命令越多,缓存消耗内存也越多。所以并不是打包的命令越多越好。具体多少合适需要根据具体情况测试。
原生批命令(mset, mget)与pipeline对比
原生批命令是原子性,pipeline是非原子性
(原子性概念:一个事务是一个不可分割的最小工作单位,要么都成功要么都失败。原子操作是指你的一个业务逻辑必须是不可拆分的. 处理一件事情要么都成功,要么都失败,原子不可拆分)原生批命令一命令多个key, 但pipeline支持多命令(存在事务),非原子性
原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
参考链接:
使用mget
/**
* 获取多个key的value值
* @param keys
* @return
*/
public List<Object> findMultiValue(List<Object> keys){
return redisTemplate.opsForValue().multiGet(keys);
}
使用pipeline
/**
* 获取多个key的value值
*
* @param keys
* @return
*/
public List<Object> findMultiValue(List<Object> keys) {
List<Object> objects = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
StringRedisConnection src = (StringRedisConnection) connection;
for (Object key : keys) {
src.get(key.toString());
}
return null;
}
});
return objects;
}
至此完毕
万分感谢文中引用链接的作者
文章来自于网络,如果侵犯了您的权益,请联系站长删除!



