【VLN阅读报告8:History Aware Multimodal Transformer for Vision-and-Language Navigation】
摘要: 视觉和语言导航(VLN)旨在构建遵循指令并在真实场景中导航的自主视觉代理。为了记住以前访问过的位置和采取的操作,大多数VLN方法都使用递归状态来实现内存。相反,我们引入了一个历史感知多模态变换器(HAMT),将长期历史纳入多模态决策中。
HAMT通过分层视觉变换器(ViT)对所有过去的全景观测进行有效编码,该变换器首先用ViT对单个图像进行编码,然后对全景观测中的图像之间的空间关系进行建模,最后考虑历史中全景图之间的时间关系。然后,它结合文本、历史和当前观察来预测下一步行动。
我们首先使用多个代理任务(包括单步动作预测和空间关系预测)对HAMT进行端到端训练,然后使用强化学习进一步改进导航策略。
HAMT在广泛的VLN任务上实现了SOTA,包括具有细粒度指令(R2R、RxR)、高级指令(R3R Last、REVERIE)、对话框(CVDN)以及长视距VLN(R4R、R2R Back)的VLN。我们证明HAMT对于具有较长轨迹的导航任务特别有效.
一,介绍
1.1 之前的工作有哪些问题
- 1,和VQA等任务不同,agent需要不断发现接收与指令对齐的新的视觉发现。
大多数现有的工作采用递归神经网络(RNN)来对固定大小的状态向量内的历史观察和动作进行编码,以预测下一个动作。这种凝聚态对于在扩展轨迹中捕获基本信息可能是次优的。
例如,“把勺子拿给我”要求代理人在导航到“勺子”后记住它的开始位置,而早期记忆在反复出现的状态下很容易消失。很少有人尝试为接收到的观测构建外部地图状记忆。然而,这些方法仍然依赖RNN来跟踪导航状态。由于历史在环境理解和教学基础方面发挥着重要作用,我们建议将历史明确编码为一系列先前的行动和观察,而不是使用重复状态。
- 另一个VLN挑战涉及将智能体推广到训练期间没见过的环境
一个方向是学习更通用的文本图像表示。
PRESS模型[20]使用预训练的BERT编码器[21]改进了语言表示,PREVALENT使用指令对和单步观察来预训练多模态transformer。尽管取得了有希望的结果,但这些工作并没有优化目标导航任务的视觉表示。此外,缺乏训练历史使得很难学习跨模态对齐,并增加了过度适应训练环境的风险。
更好地概括的另一个方向是克服由于训练和推断之间的差异而导致的暴露偏差。VLN采用了不同的方法,包括DAgger和计划采样。强化学习(RL)是其中最有效的方法之一,但通过RL直接训练大型transformer被认为是不稳定的。
1.2 本文怎么做的
HAMT包括用于文本、历史和观察编码的单模态transformer,以及用于捕获历史序列的长程相关性的跨模态transformer,历史包含所有先前观察的序列,代价是计算成本高。
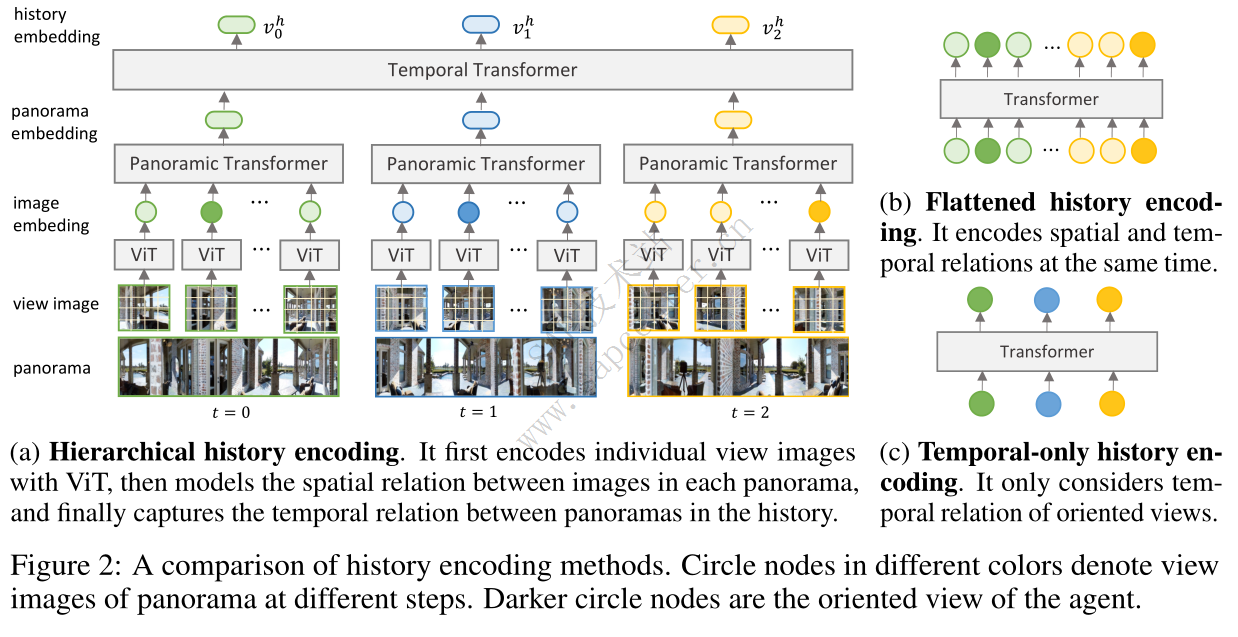
为降低计算成本,本文提出了如图2所示的分层视觉变换器,它逐步学习单个视图的表示、全景图中视图之间的空间关系以及历史全景图中的时间动态。
为了学习更好的视觉表示,本文提出了用于端到端训练的辅助代理任务。这些任务包括基于模仿学习的单步动作预测、自我监督的空间关系推理、掩蔽语言和图像预测以及指令轨迹匹配。
1.3 本文贡献
- (1)我们引入HAMT,通过分层视觉变换器有效地对观察到的全景和动作的长视距历史进行建模;
- (2) 我们以端到端的方式用辅助代理任务训练HAMT,并使用RL来改进导航策略;
- (3) 我们验证了我们的方法,并在各种VLN任务中超越了现有技术,同时证明了长期导航的更大收益。
二,相关工作
看本文需要了解的知识:
LSTM[34]是编码导航记忆的主要方法。然而,将所有历史浓缩为一个特征向量容易导致信息丢失。替代方法包括拓扑映射存储器结构。邓等人使用图形来捕捉环境布局并实现长期规划。[19]中采用了类似的基于前沿探索的决策图。但这些工作仍然利用LSTM进行状态跟踪。为了利用长期的时空依赖性,Fang等人[17]将历史存储在用变换器编码的序列中。递归VLN-BERT[5]注入一个递归单元来对VLN的变压器中的历史进行编码。与我们最相似的作品是(E.T.)[37]。与[37]不同,我们提出了全景观测历史的分层编码,并在端到端训练中优化整个模型。
三,方法
主要包含哪几个模块,每个模块的作用
问题定义
给定一个包含L个单词 { w 1 , w 2 , … , w L } \{w_1,w_2,\dots,w_L\} {w1,w2,…,wL}的指令 W \mathcal{W} W.在步骤t,agent接收一个发现(全景图) O t \mathcal{O}_t Ot, 全景图包含K个单独的image, O t ≜ ( [ v 1 o ; a 1 o ] , … , [ v K o ; a K o ] ) \mathcal{O}_t \triangleq ([v^{o}_1; a^{o}_1],\dots,[v^{o}_K; a^{o}_K]) Ot≜([v1o;a1o],…,[vKo;aKo]), v i o v^{o}_i vio是视觉特征, a i o a^{o}_i aio表示面向视图的相对角度。所有K个views中有 n n n 个 navigable viewpoints ,表示为 O t c ≜ ( [ v 1 c ; a 1 c ] , … , [ v 1 c ; a 1 c ] ) \mathcal{O}^{c}_t \triangleq ([v^{c}_1; a^{c}_1],\dots,[v^{c}_1; a^{c}_1]) Otc≜([v1c;a1c],…,[v1c;a1c]). ( O t \mathcal{O}_t Ot是可以看到的, O t c \mathcal{O}^c_t Otc是可以到达的全景)。agent只需要每一步在 O t c \mathcal{O}^c_t Otc选择一个候选决策。
步骤t之前的所有发现 O i \mathcal{O}_i Oi和执行过的动作 a i h a^{h}_i aih 形成历史 H t ≜ ( [ O 1 ; a 1 h ] , … , [ O t − 1 ; a t − 1 h ] ) \mathcal{H}_t \triangleq ([\mathcal{O}_1; a^{h}_1],\dots,[\mathcal{O}_{t-1}; a^{h}_{t-1}]) Ht≜([O1;a1h],…,[Ot−1;at−1h]), a i h a^{h}_i aih表示在步骤t的转角。
目标是学习由 Θ \Theta Θ 参数化的策略π,以根据指令、历史和当前观察预测下一个动作,即 π ( a t ∣ W , H t , O t , O t c ; Θ ) π(a_t|\mathcal{W},\mathcal{H}_t,\mathcal{O}_t,\mathcal{O}^c_t;\Theta) π(at∣W,Ht,Ot,Otc;Θ)
3.1 HAMT: History Aware Multimodal Transformer
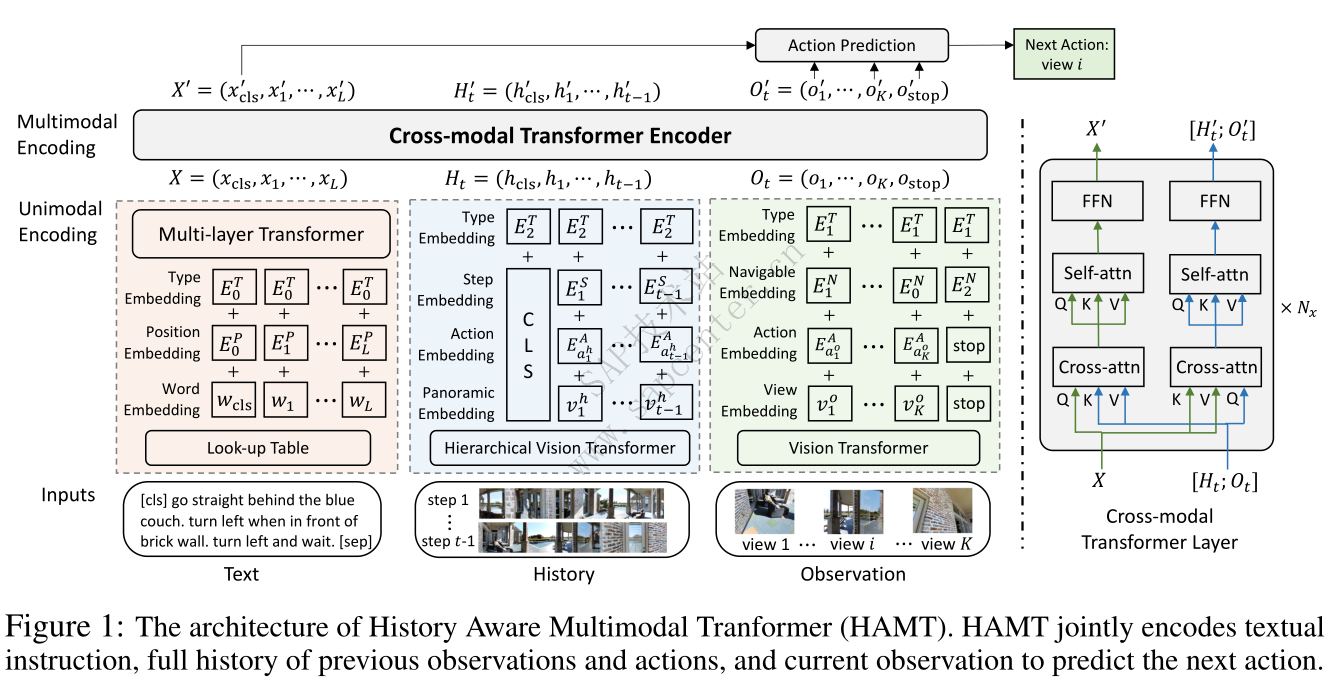
图1说明了HAMT的模型体系结构。输入文本 W W W、历史 H t H_t Ht和观测 O t O_t Ot首先分别通过相应的单模态transformer进行编码,然后馈入跨模态transformer编码器以捕获多模态关系。
文本编码
对于指令 W \mathcal{W} W中的每个标记 i,我们将其嵌入为其文字嵌入 w i w_i wi、位置嵌入 E i P E^{P}_i EiP和文本的类型嵌入 E 0 T E^{T}_0 E0T的总和。然后,我们fellow标准的BERT,使用具有NL层的变换器来获得上下文表示 x i x_i xi.
观察 O \mathcal{O} O编码
对于观察中的每个视图 [ v i o , a i o ] [v^{o}_i,a^{o}_i] [vio,aio], 首先将相对角度 a i o a^{o}_i aio表示为 E a i o A = ( s i n θ i , c o s θ i 、 s i n φ i 、 c o s φ i ) E^{A}_{a^{o}_i}=(sinθ_i,cosθ_i、sinφ_i、cosφ_i) EaioA=(sinθi,cosθi、sinφi、cosφi),其中 θ i 和 φ i θ_i和φ_i θi和φi是相对于代理人方向的相对航向和仰角.然后观测嵌入 o i o_i oi如下:
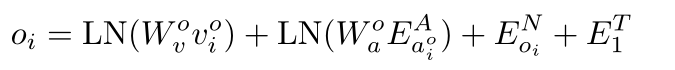
E o i A E^{A}_{o_i} EoiA表示用于区分视图类型的可导航嵌入, E 0 N E^{N}_0 E0N表示没有导航视图, E 1 N E^{N}_1 E1N表示可导航视图和 E 2 N E^{N}_2 E2N表示停止视图(我们在观察中添加停止标记以支持停止操作)。 E 1 T E^{T}_1 E1T是观测的类型嵌入。为了简单起见,我们省略了偏差项。LN 表示层归一化。因为 a i o a^{o}_i aio 比 v i o v^{o}_i vio 具有低得多的特征维度,所以我们应用 L N LN LN 来平衡编码的 a i o a^{o}_i aio和 v i o v^{o}_i vio。
分层历史编码
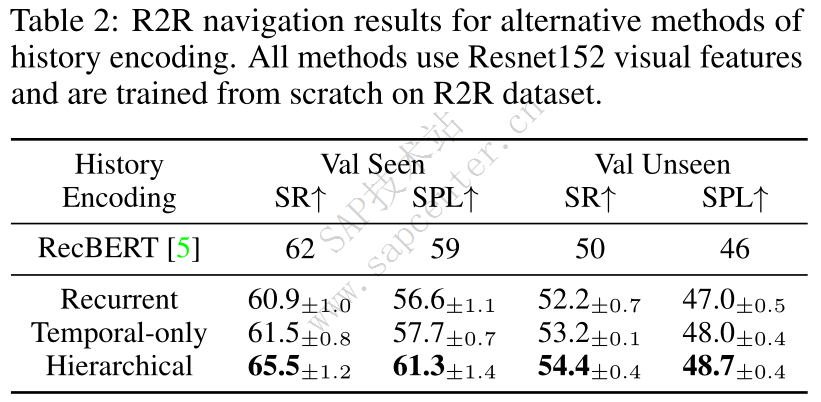
由于 H t \mathcal{H}_t Ht 由所有过去t步的全景观察 O i \mathcal{O}_i Oi和执行的动作 a i h a^{h}_i aih组成,因此高效地将 H t \mathcal{H}_t Ht 编码为上下文非常重要。图2b-2c分别描述了VLN-BERT[44]和E.T.[37]中使用的平坦化和仅时间历史编码方法。扁平化方法将 O i \mathcal{O}_i Oi中的每个视图图像视为一个标记,因此历史序列包含 t K tK tK 个标记。尽管它能够学习所有图像视图之间的关系,但计算成本随着序列长度的增加而呈二次增长,这使得它在长视距任务中效率低下。在 temporal-only方法中,仅将每个 O i \mathcal{O}_i Oi中的代理的面向视图作为输入,而不是整个全景,因此仅对 t temporal 标记进行编码。然而,这种方法可能会在过去的观察中丢失关键信息。例如,在“窗户在你的左边,穿过大房间经过休息区” 的说明中,对象“窗户”不会出现在代理的定向视图中。因此,编码的历史记录不足以判断代理是否通过了窗口,从而使模型无法采取下一步行动。
为了平衡计算效率和信息完整性,我们提出了一种分层历史编码方法,如图2a所示。它对每个全景内的视图图像进行分层编码,然后对全景间的时间关系进行编码,类似于分解的时空视频变换器[46]。对于每个 O i \mathcal{O}_i Oi,其组成视图图像首先通过ViT和等式(1)嵌入,然后通过具有 N h N_h Nh 个层的全景变换器进行编码,以学习全景内的空间关系。我们应用平均池来获得全景嵌入,并添加残差连接中的定向视图图像特征。对于不同的步骤,ViT和全景变压器中的参数是共享的。这样,每个历史观测 O i \mathcal{O}_i Oi 表示为 v i h v^{h}_i vih,并且最终的时间标记 h i h_i hi 被计算为:
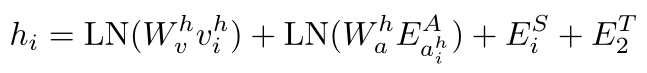
其中 E i S E^{S}_i EiS 表示第i步嵌入, E 2 T E^{T}_2 E2T 表示历史的类型嵌入。计算成本为 O ( t K 2 + t 2 ) O(tK^2+t^2) O(tK2+t2),与平坦化方法中的 O ( t 2 K 2 ) O(t^2K^2) O(t2K2) 相比显著降低。需要注意的是,我们在历史序列的开头添加了一个特殊标记 [cls],以获得全局表示。
**[cls]**的嵌入是一个要学习的参数,它从零向量初始化
跨模态编码
我们将历史和观察连接为视觉模态,并使用具有 N x N_x Nx 层的跨模态变换器来融合文本、历史和观察的特征,如图1右侧所示。使用这种双流架构而不是单流架构的原因是,不同模态的长度可能高度不平衡,并且双流架构可以通过模型设计平衡模态内和模态间关系的重要性[47]。
在每个跨模态层中,首先对视觉模态执行视觉文本交叉关注以关注相关文本信息,反之亦然。然后,每种模态都使用自我关注来学习模态内的关系,如观察和历史之间的相互作用,然后是完全连接的神经网络。最后,HAMT模型输出嵌入 X ′ = ( x c l s ′ , x 1 ′ , ⋅ ⋅ ⋅ , x L ′ ), h 0 t = ( h c l s ′ 、 h 1 ′ , ⋅ ⋅ ⋅ , h t − 1 ′ ), O t ′ = ( o 1 ′ , ⋅ ⋅ , o K ′ , o s ′ t o p ) X^{'}=(x^{'}_{cls},x^{'}_1,···,x^{'}_L),h0t=(h^{'}_{cls}、h^{'}_1,···,h^{'}_{t−1}) ,O^{'}_t=(o^{'}_1,··,o^{'}_K,o^{'}_stop) X′=(xcls′,x1′,⋅⋅⋅,xL′),h0t=(hcls′、h1′,⋅⋅⋅,ht−1′),Ot′=(o1′,⋅⋅,oK′,os′top)分别用于文本、历史和观察中的标记。
3.2 使用代理任务进行端到端培训

我们的模型可以利用各种代理任务来学习跨模态对齐、空间和时间推理以及历史感知动作预测。给定输入对(W,HT),其中T是完整轨迹的长度,我们可以应用常见的代理任务,如视觉和语言预训练 包括掩蔽语言建模Masked Language Modeling (MLM)、掩蔽区域建模Masked Region Modeling (MRM)和指令轨迹匹配 Instruction
Trajectory Matching (ITM)。
Single-step Action Prediction/Regression (SAP/SAR)单步行为预测
该任务部署模仿学习,以根据指令、专家演示的历史和当前观察预测下一步行动。我们将其分别表述为分类和回归任务。
在SAP分类任务中,我们为 O t c \mathcal{O}^c_t Otc中的每个导航视图预测了的动作概率,即 p t ( o i ′ ) = e x p ( f S A P ( o i ′ ⊙ x c l s ′ ) ) ∑ j e x p ( f S A P ( o j ′ ⊙ x c l s ′ ) ) p_t(o^{'}_i)= \frac{exp(f_{SAP}(o^{'}_i \odot x^{'}_{cls}))}{\sum_j exp(f_{SAP}(o^{'}_j \odot x^{'}_{cls}))} pt(oi′)=∑jexp(fSAP(oj′⊙xcls′))exp(fSAP(oi′⊙xcls′)),其中 f S A P f_{SAP} fSAP 是一个两层完全连接的网络,
⊙ \odot ⊙ 是element-wise multiplication
x c l s ′ x^{'}_{cls} xcls′ 是特殊文本标记 [cls] 的输出嵌入。目标是最小化目标视图action o ∗ ′ : L S A P = ( θ ^ − θ t ) 2 + ( ϕ ^ − ϕ t ) 2 o^{'}_{*}: L_{SAP} = (\hat{\theta} - \theta_t)^2 + (\hat{\phi}- \phi_t)^2 o∗′:LSAP=(θ^−θt)2+(ϕ^−ϕt)2
在SAR回归任务中,我们基于文本标记 [cls] 直接预测行动航向和仰角, θ ^ t , ϕ ^ t = f S A R ( x c l s ′ ) \hat{\theta}_t, \hat{\phi}_t = f_{SAR}(x^{'}_{cls}) θ^t,ϕ^t=fSAR(xcls′)。损失函数为 L S A R = ( θ ^ t − θ t ) 2 + ( ϕ ^ t − ϕ t ) 2 L_{SAR}=(\hat{\theta}_t− θ_t)^2+(\hat{\phi}_t− \phi_t)^2 LSAR=(θ^t−θt)2+(ϕ^t−ϕt)2. 两个代理任务使模型能够学习如何根据指令和上下文历史进行动作决策。
Spatial Relationship Prediction (SPREL)
自我中心和异地中心空间关系的表达在导航指令中很常见,比如“走进左边的房间”和“走进楼梯旁边的卧室”。为了学习空间关系感知表示,我们提出了SPREL自监督任务,以仅基于视觉特征、角度特征或两者来预测全景图中两个视图的相对空间位置。假设[voi;aoi]和[voj;aoj]是Ot中的两个视图,我们将vo随机归零∗ 或ao∗ 其编码表示为o0i和o0j,相对航向和仰角为θij,φij。然后我们预测ˆθij,\710φij=fSPREL([o0i;o0j]),其中[;]表示向量连接并优化LSPREL=(ˆθij− θij)2+(φij− φij)2.该任务有助于观察中的空间关系推理。
Training Strategy
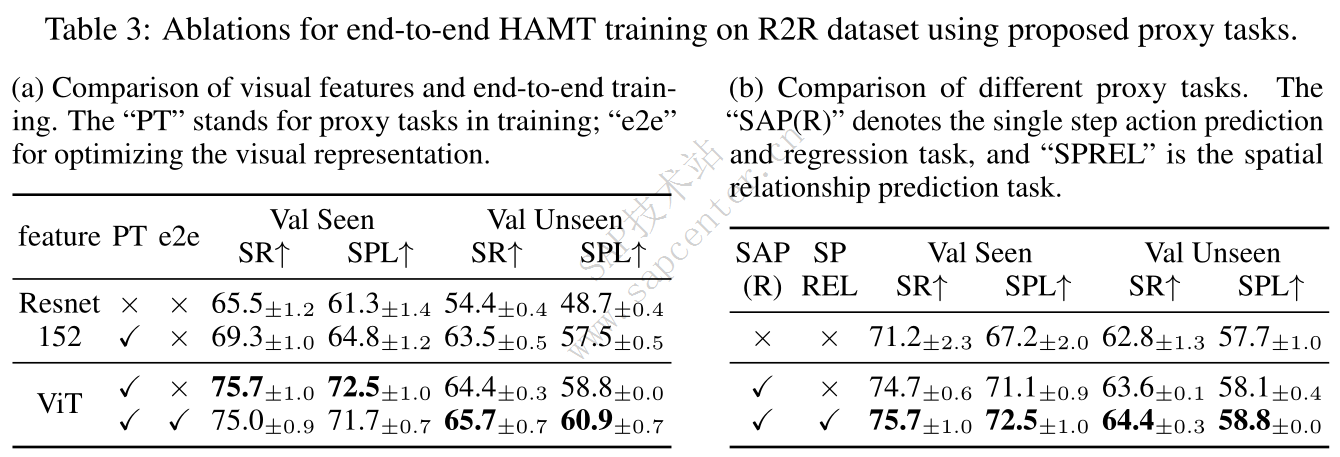
我们建议分两个阶段逐步训练 HAMT,而不是一次直接训练整个HAMT 模型。在第一阶段,我们冻结在ImageNet[48]上预训练的 ViT,并训练随机初始化的其余模块。这旨在避免灾难性地忘记 ViT 中的预训练权重。然后我们解冻 ViT 并从头到尾训练整个模型。ViT 的学习速率被设置为高于其他模块,以避免梯度消失并加速收敛。我们的经验表明,在补充材料中,建议的两阶段训练优于一阶段训练。
3.3 Fine-tuning for sequential action prediction
Structure Variants
我们在下文中介绍了两种用于行动预测的HAMT变体。
1) MLP动作头:我们在SAP任务中直接重用动作预测网络 f S A P f_{SAP} fSAP 来预测可导航视图。我们将其用作VLN任务的默认值。2) 基于编码器-解码器结构的MLP动作头:原始HAMT模型将跨模态注意力应用于视觉到文本和文本到视觉,这在指令较长时计算成本较高。因此,我们去除了从文本到视觉的跨模态注意。通过这种方式,我们将跨模态变换器分为一个编码器和一个解码器,编码器只将指令作为输入,解码器将历史和观察作为查询输入,并处理编码的文本标记。详见补充资料
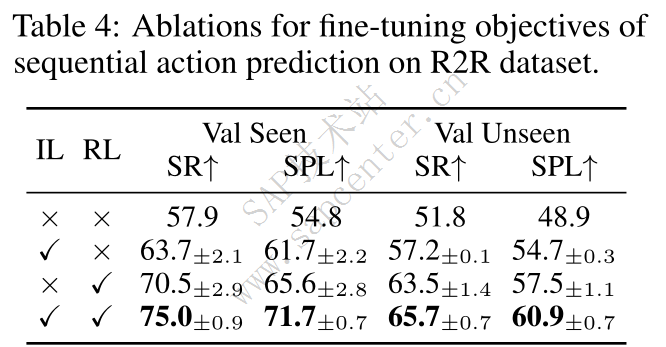
RL+IL Objective
我们结合强化学习(RL)和模仿学习(IL)来微调HAMT以进行顺序动作预测。IL依赖于第3.2节中定义的SAP损失,并在每一步遵循专家行动,同时RL根据策略 π 对行动进行采样。具体而言,我们使用了异步优势行为批评(A3C)RL算法[28]。在每个步骤t,代理根据策略 π : a ^ t h ∼ π ( a t ∣ W , H t , O t , O t c ) π: \hat{a}^{h}_t \sim π(a_t| \mathcal{W}, \mathcal{H}_t, \mathcal{O}_t, \mathcal{O}^{c}_t) π:a^th∼π(at∣W,Ht,Ot,Otc) 对动作进行采样,并获得即时奖励 r t r_t rt。对于non-stop 动作,我们将 r t r_t rt 设置为与[5]中定义的专家演示相比,动作到目标的距离缩短,对齐分数[3]增加;对于停止动作,如果代理成功到达目标,则 r t = 2 r_t = 2 rt=2,否则为 -2。训练批评者网络以估计每个状态 s t s_t st 的值,即 R t = ∑ k = 0 T − t γ k r t + k R_t = \sum^{T-t}_{k=0} \gamma^{k} r_{t+k} Rt=∑k=0T−tγkrt+k,其中 γ \gamma γ 是贴现系数。我们将其实现为 V t = f c r i t i c ( x c l s ′ ⊙ h c l s ′ ) V_t = f_{critic}(x^{'}_{cls} \odot h^{'}_{cls}) Vt=fcritic(xcls′⊙hcls′) 。由于奖励信号倾向于最短距离,我们根据经验发现,将A3C RL与以 λ λ λ 加权的IL相结合是有益的,即
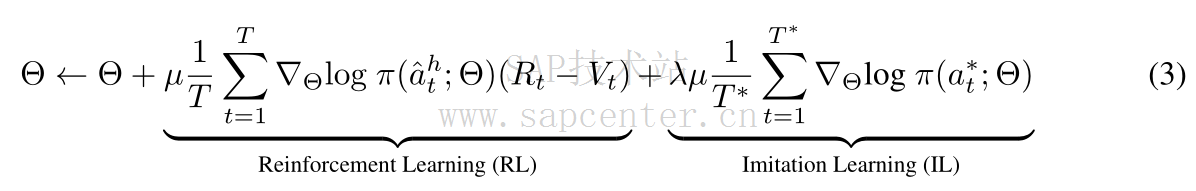
其中µ是学习率, a t ∗ a^{*}_t at∗是长度为 T ∗ T^* T∗ 的专家轨迹的步骤 t 处的专家动作
四,实验
4.1 实验设置
数据集
• RxR 是一个基于Matterport 3D的大型多语言VLN数据集。说明有三种不同的语言(英语、印地语和泰卢固语)。数据集强调了语言在VLN中的作用,解决了路径中的偏差,并描述了比R2R更可见的实体。
• R4R 通过连接R2R中两个相邻的尾部到头部轨迹来扩展R2R数据集。因此,它有更长的指令和轨迹。由于轨迹不一定是从起点到终点的最短路径,因此轨迹也不太偏向。
• R2R Back是本工作中提出的新VLN设置。到达目的地后,代理必须返回其起始位置。代理需要记住其导航历史来解决任务。我们在R2R中的每条指令的末尾添加了一个返回命令,并添加了从结束位置到开始位置的反向路径作为专家演示。
• R2R-Last is our proposed VLN setup similar to REVERIE. It only uses the last sentence from
the original R2R instructions describing the final destination.
评估指标
(1) 轨迹长度(TL):代理的导航路径,单位为米;
(2) 导航误差(NE):代理人最终位置与目标之间的平均距离,单位为米;
(3) 成功率(SR):到达目的地且最大误差为3米的轨迹与目标的比率;
(4)由最短路径的长度与预测路径(SPL)之间的比率归一化的成功率。SPL比SR更相关,因为它平衡了导航精度和效率。对于长视距VLN任务(R4R和R2R Back),我们进一步使用三个度量来测量预测路径和目标路径之间的路径保真度,包括
(5)由长度分数(CLS)加权的覆盖率[3];
(6) he normalized Dynamic Time Warping(nDTW);
(7) the Success weighted by nDTW (SDTW)
实现细节
对于HAMT模型,我们为语言变换器设置NL=9,为分层历史编码中的全景变换器设置Nh=2,为跨模态变换器设置Nx=4。
在每个全景观察中有K=36个视图图像。如果未另行规定,我们使用ViT-B/16进行图像编码。
在使用代理任务的训练中,我们以预定义的比率为每个小批量随机选择代理任务。
我们在4个NVIDIA Tesla P100 GPU上使用5e-5的学习率和64的批量大小,使用固定的ViT训练HAMT进行200k次迭代(∼1天)。
整个HAMT模型在20个NVIDIA V100 GPU上进行端到端的20k迭代训练,ViT的学习率为5e-5,其他的为1e-5(∼20小时)。除非另有说明,否则我们使用[22]中的R2R训练集和增强对进行训练。
在使用RL+IL进行微调时,我们在等式(3)中设置λ=0.2,γ=0.9。
该模型在单个GPU上进行了100k次迭代微调,学习率为1e-5,批量大小为8。默认情况下,单模编码器是固定的。最佳模型是根据val seven split的性能选择的。
4.2 消融实验
How important is the history encoding for VLN?
How much does training with proxy tasks help?
What is the impact of the fine-tuning objectives?
4.3 与SOTA比较
VLN with fine-grained instructions: R2R and RxR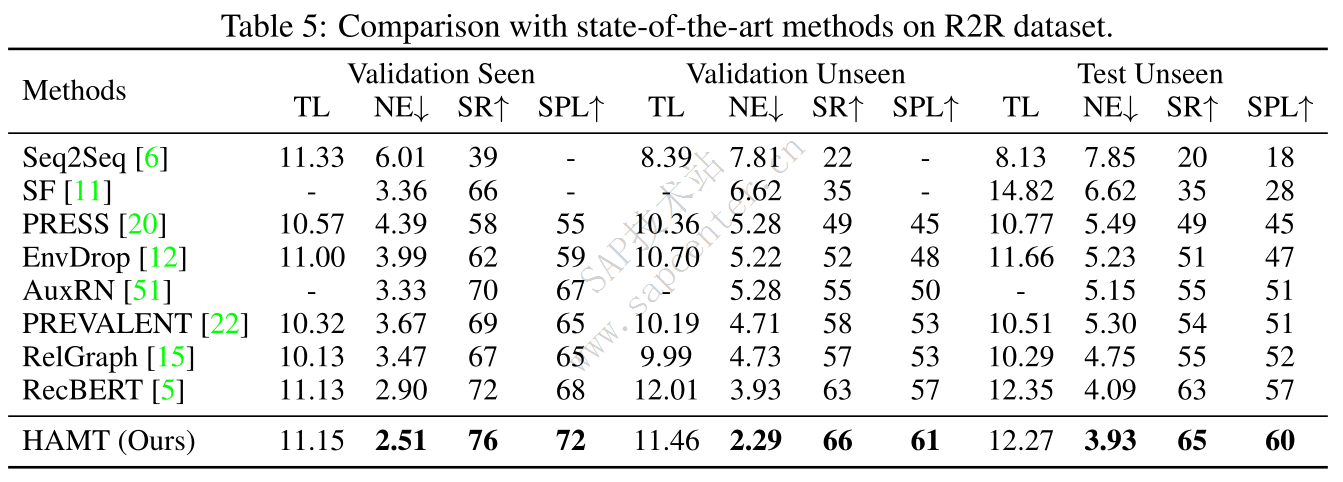
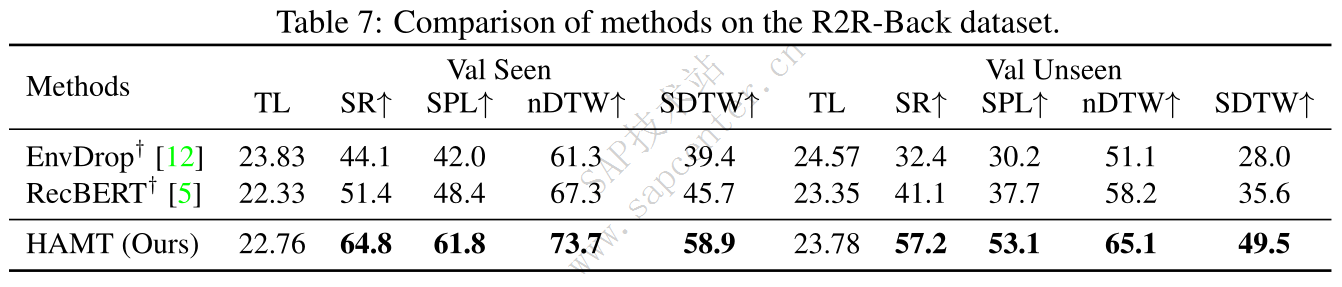
Long-horizon VLN: R4R and R2R-Back
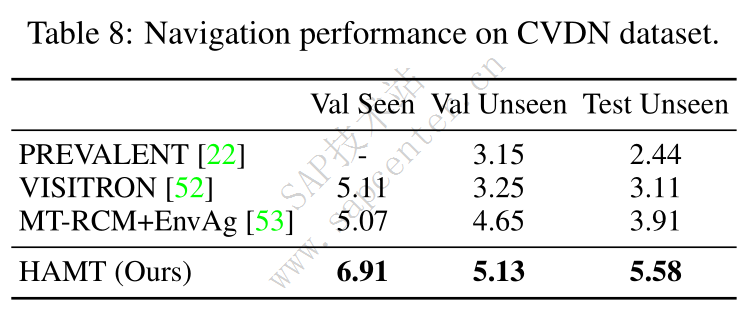
Vision-and-Dialog Navigation: CVDN
VLN with high-level instructions: R2R-Last and REVERIE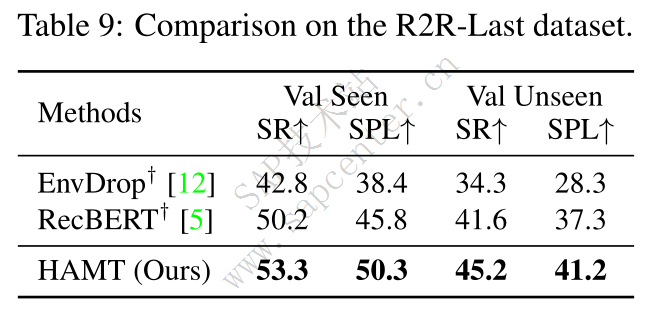
五,总结
个人思考与看法
- 之前的VLN任务试图训练好的agent能够在即使没见过的环境中找到目标位置或物体。除非环境非常相似甚至一样。不然即使人类也无法找到,只有不断试错。我们期待agent像人一样,但是感觉缺少了什么
- (本文和SOON任务同一年提出,所以没有在SOON上进行实验)
- 本文提升性能以牺牲计算量为代价,需要进一步权衡。
文章来自于网络,如果侵犯了您的权益,请联系站长删除!



