ABAP 长文本内容数据迁移 SAP
SAP 长文本的内容具体存在 STXL STXH两张表。
STXH 主要存长文本抬头明细信息。
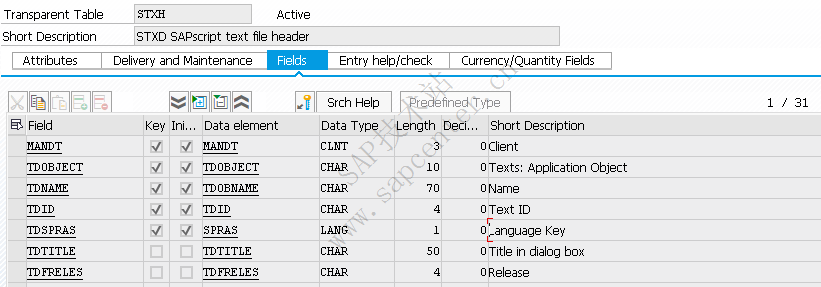
STXL 存长文本的具体内容。
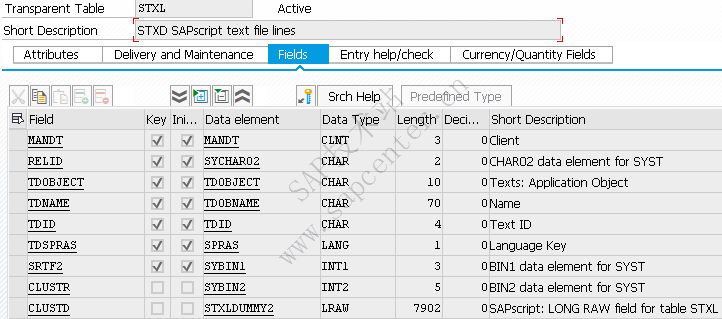
值得注意的是长文本内容在STXL进行存储的内容是转换成其他格式存储,导致不能直接从数据库取数,需要使用READ_TEXT 函数。
长文本最主要的四个参数
TDSPRAS "语言
TDID "文本标识
TDNAME "文本名
TDOBJECT "文本对象
LT_TLINE 这个内表有两列,第一列是长文本格式,第二列是内容,能具体的反应出长文本的格式内容,列如换行之类的。
举一个简单的例子,下图中*号代表换行符。
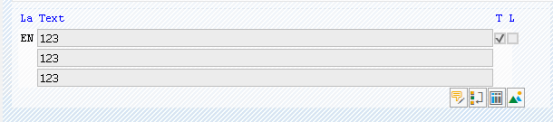
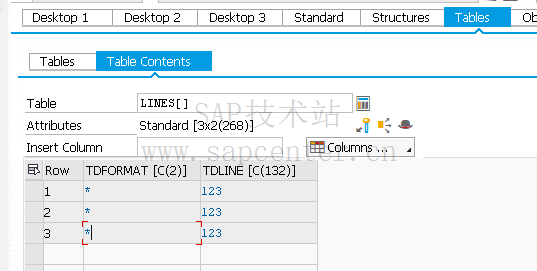
DATA: LT_TLINE TYPE STANDARD TABLE OF TLINE .
DATA: LS_TLINE TYPE TLINE.
CALL FUNCTION 'READ_TEXT'
EXPORTING
ID = TDID
LANGUAGE = TDSPRAS
NAME = TDNAME
OBJECT = TDOBJECT
TABLES
LINES = LT_TLINE.
或者CL_ESO_EXTRACTION_TOOLS=>EXTRACT_LONG_TEXT_BY_ID
这个方法,他的内核还是READ_TEXT,只不过输出形式不同,会直接把长文本拼接好放入字符串,就不展示了过程了。
* 读取长文本---通过id
* CALL METHOD CL_ESO_EXTRACTION_TOOLS=>EXTRACT_LONG_TEXT_BY_ID
* EXPORTING
* IV_LANGU = TDSPRAS "语言
* IV_TEXT_ID = TDID "文本标识
* IV_NAME = TDNAME "文本名
* IV_OBJECT = TDOBJECT "文本对象
* IMPORTING
* EV_SEARCH_TERMS = LV_STR.
再说一下遇到这次遇到的一个问题,因为要求数据迁移之后需要前端对数据库进行分析复现,所以就不能用方法去直接拼成一个字符串进行储存,这样会丢失回车换行符,所以还是需要用到READ_TEXT 来读取数据库的具体内容,因为需要识别换行符,READ_TEXT 输出的内表第一列就有格式,可以进行判断识别换行符,然后替换成通用的编码以帮助于前端分析,* 号用CL_ABAP_CHAR_UTILITIES=>CR_LF进行替换成换行符。但还碰到一种特殊情况,有一个 文本格式是>X的,如下图所示,因为是固定格式所以展示格式不同。
(在这贴上一个SAP官方文档解释格式的种类
https://help.sap.com/saphelp_ewm900/helpdata/en/4e/1c2ae30b4d1a26e10000000a42189e/content.htm?no_cache=true)


这段逻辑就是处理正常分行符格式,和特殊格式,因为>X的问题,导致换行符在文本内容那一列,所以需要单独做一个判断再进行替换
LOOP AT LT_TLINE INTO LS_TLINE ."ls_tline-TDLINE
CASE LS_TLINE-TDFORMAT"(文本格式).
WHEN '*'." 判断出换行符,直接拼接标准的换行符
CONCATENATE LV_STR CL_ABAP_CHAR_UTILITIES=>CR_LF LS_TLINE-TDLINE INTO LV_STR .
WHEN '' ." 无换行符
CONCATENATE LV_STR LS_TLINE-TDLINE INTO LV_STR .
WHEN OTHERS ." 检查文本内容中有没有换行符
if LS_TLINE-TDLINE(1) = '*' . "如果第一位字符出现*,替换为换行符
REPLACE FIRST OCCURRENCE OF '*' IN LS_TLINE-TDLINE WITH CL_ABAP_CHAR_UTILITIES=>CR_LF.
CONCATENATE LV_STR LS_TLINE-TDLINE INTO LV_STR .
else.
CONCATENATE LV_STR LS_TLINE-TDLINE INTO LV_STR .
endif.
ENDCASE.
CLEAR LS_TLINE.
ENDLOOP.
在这存储的过程中还遇到一个小问题,在DEBUG的过程中看见*号已经被替换成标准换行符,然后存入底表没有了SE11与SE16N都看不到具体换行符,以为字符串丢失了,经过询问是底表数据库不进行展示,如果用ALV报表对该底表再用SELECT抽出来会有乱码展示,只是不在底表进行显示。(因前端没进行过具体测试不太确定此方法迁移数据有用,方法仅供参考记录。)
老规矩完整代码如下,COPY可以直接运行,可以细致的DEBUG观看具体的处理过程。(还未进行后期测试,仅提供参考处理逻辑方法):
REPORT ZCCS_MIG004.
TABLES: STXL .
*&---------------------------------------------------------------------*
*& Internal Tables Declares
*&---------------------------------------------------------------------*
DATA: TEXT1 TYPE STRING.
DATA: LV_STR TYPE STRING.
DATA: LV_TDNAME TYPE STRING.
TYPES: BEGIN OF TY_TEXT,
MANDT TYPE MANDT,
ZOBJECT TYPE TDOBJECT, "文本对象
ZNAME TYPE TDOBNAME, "文本名
ZID TYPE TDID, "文本标识
ZSPRAS TYPE SPRAS, "语言
ZSRTF2 TYPE SYBIN1, "同一个长文本内容次数
ZTEXT TYPE ZTEXT, "长文本内容
END OF TY_TEXT.
TYPES: BEGIN OF TY_STXL ,
MANDT TYPE MANDT,
TDOBJECT TYPE STXL-TDOBJECT,
TDNAME TYPE STXL-TDNAME,
TDID TYPE STXL-TDID,
TDSPRAS TYPE STXL-TDSPRAS,
SRTF2 TYPE SYBIN1, "同一个长文本内容次数
END OF TY_STXL.
DATA : LT_TEXT TYPE STANDARD TABLE OF TY_TEXT,
LS_TEXT TYPE TY_TEXT,
LT_STXL TYPE STANDARD TABLE OF TY_STXL,
LS_STXL TYPE TY_STXL.
************************************************************************
* Selection screen *
************************************************************************
SELECTION-SCREEN: BEGIN OF BLOCK B1 WITH FRAME TITLE TEXT-001.
*Input screen: selection options
SELECT-OPTIONS:
S_ZOBJE FOR STXL-TDOBJECT , "文本对象
S_ZNAME FOR STXL-TDNAME OBLIGATORY, "文本名
S_ZID FOR STXL-TDID , "文本标识
S_ZSPRAS FOR STXL-TDSPRAS , "语言
S_SRTF2 FOR STXL-SRTF2 . "同一个长文本内容次数
SELECTION-SCREEN: END OF BLOCK B1.
*INITIALIZATION.
START-OF-SELECTION.
PERFORM PRECESS_DATA. " 主要数据处理逻辑
*&---------------------------------------------------------------------*
*& Form PRECESS_DATA
*&---------------------------------------------------------------------*
* text
*----------------------------------------------------------------------*
*----------------------------------------------------------------------*
FORM PRECESS_DATA.
REFRESH LT_STXL.
REFRESH LT_TEXT.
CLEAR TEXT1 .
CLEAR LV_STR.
SELECT
MANDT
TDOBJECT "文本对象
TDNAME "文本名
TDID "文本标识
TDSPRAS "语言
SRTF2 "同一个长文本内容次数
FROM STXL
INTO TABLE LT_STXL
WHERE TDOBJECT IN S_ZOBJE
AND TDNAME IN S_ZNAME
AND TDID IN S_ZID
AND TDSPRAS IN S_ZSPRAS .
SORT LT_STXL BY TDOBJECT TDNAME.
CLEAR TEXT1.
TEXT1 = '0'.
LOOP AT LT_STXL INTO LS_STXL.
CLEAR LV_STR.
PERFORM FRM_READ_TEXT USING LS_STXL-TDOBJECT "文本对象
LS_STXL-TDNAME "文本名
LS_STXL-TDID "文本标识
LS_STXL-TDSPRAS "语言
CHANGING TEXT1
LV_STR.
IF SY-SUBRC = '0' AND LV_STR IS NOT INITIAL .
LS_TEXT-MANDT = LS_STXL-MANDT. "mandt
LS_TEXT-ZOBJECT = LS_STXL-TDOBJECT. "文本对象
LS_TEXT-ZNAME = LS_STXL-TDNAME. "文本名
LS_TEXT-ZID = LS_STXL-TDID. "文本标识
LS_TEXT-ZSPRAS = LS_STXL-TDSPRAS. "语言
LS_TEXT-ZSRTF2 = LS_STXL-SRTF2. "同一个长文本内容次数
LS_TEXT-ZTEXT = LV_STR. "长文本
APPEND LS_TEXT TO LT_TEXT.
IF SY-SUBRC = '0'.
TEXT1 = TEXT1 + '1'.
ENDIF.
ENDIF.
CLEAR LS_STXL.
ENDLOOP.
MODIFY ZCCS_MIG004 FROM TABLE LT_TEXT[].
IF SY-SUBRC = 0.
COMMIT WORK AND WAIT.
MESSAGE '长文本更新成功!总数为' && TEXT1 && '条' TYPE 'S'.
ELSE.
ROLLBACK WORK.
MESSAGE '保存出错' TYPE 'S' DISPLAY LIKE 'E'.
ENDIF.
ENDFORM. " FRM_PRECESS_DATA
*&---------------------------------------------------------------------*
*& Form FRM_READ_TEXT
*&---------------------------------------------------------------------*
* text
*----------------------------------------------------------------------*
*----------------------------------------------------------------------*
FORM FRM_READ_TEXT USING TDOBJECT
TDNAME
TDID
TDSPRAS
CHANGING TEXT1
LV_STR.
* 读取长文本---通过id
* CALL METHOD CL_ESO_EXTRACTION_TOOLS=>EXTRACT_LONG_TEXT_BY_ID
* EXPORTING
* IV_LANGU = TDSPRAS "语言
* IV_TEXT_ID = TDID "文本标识
* IV_NAME = TDNAME "文本名
* IV_OBJECT = TDOBJECT "文本对象
* IMPORTING
* EV_SEARCH_TERMS = LV_STR.
DATA: LT_TLINE TYPE STANDARD TABLE OF TLINE .
DATA: LS_TLINE TYPE TLINE.
DATA: LV_TEXT TYPE C.
CALL FUNCTION 'READ_TEXT'
EXPORTING
ID = TDID
LANGUAGE = TDSPRAS
NAME = TDNAME
OBJECT = TDOBJECT
TABLES
LINES = LT_TLINE.
IF SY-SUBRC = 0.
LOOP AT LT_TLINE INTO LS_TLINE ."ls_tline-TDLINE
CASE LS_TLINE-TDFORMAT.
WHEN '*'." huan hang
CONCATENATE LV_STR CL_ABAP_CHAR_UTILITIES=>CR_LF LS_TLINE-TDLINE INTO LV_STR .
WHEN '' ." bu huan
CONCATENATE LV_STR LS_TLINE-TDLINE INTO LV_STR .
WHEN OTHERS ." 检查文本内容中有没有换行符
if LS_TLINE-TDLINE(1) = '*' . "如果第一位字符出现*,替换为换行符
REPLACE FIRST OCCURRENCE OF '*' IN LS_TLINE-TDLINE WITH CL_ABAP_CHAR_UTILITIES=>CR_LF.
CONCATENATE LV_STR LS_TLINE-TDLINE INTO LV_STR .
else.
CONCATENATE LV_STR LS_TLINE-TDLINE INTO LV_STR .
endif.
ENDCASE.
CLEAR LS_TLINE.
ENDLOOP.
ENDIF.
ENDFORM. " FRM_READ_TEXT
突然想起来还有一个函数READ_TEXT_TABLE这个函数,没用过,用兴趣可以试试。
文章来自于网络,如果侵犯了您的权益,请联系站长删除!



